课程信息:感谢@李文哲老师,贪心科技–“ 共同战疫” NLP系列专题 直播课,本文所有版权归贪心科技https://www.greedyai.com/所有。
Lecture 1 - 词向量与ELMo模型
一.词向量分布
1. 语言模型
计算句子的概率或者一系列单词的概率:
$P(全民AI是趋势)=P(全民,AI,是,趋势)=P(全民) \times P(AI | 全民) \times P(是|全民,AI) \times P(趋势|全民,AI,是)$
语言模型需要最大化上面的似然概率,即基于训练好的模型,可以基于“全民”这个单词可以猜出“AI”这个单词,基于“全民AI”可以预测出“是”….从而预测出整个句子。
2. 基于分布式的词向量表示模型总览
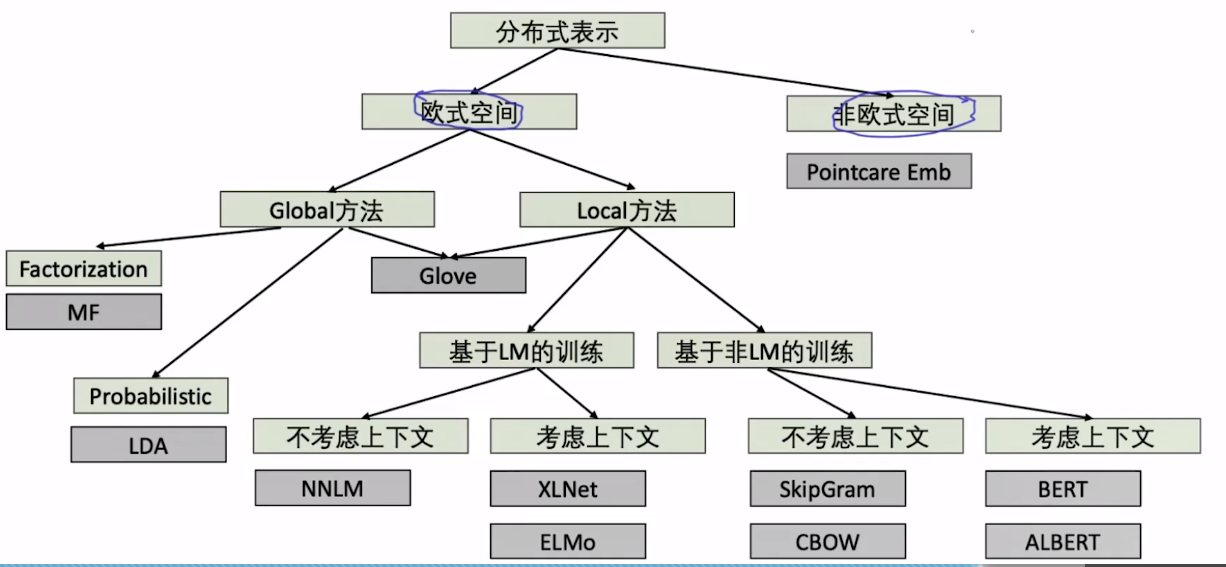
Global vs Local 方法: Global方法:将整个数据集输入模型之中,从而学习到词的全局属性
- Advantange:全局
- Disadvantage:1,计算大 2,不能在线学习
Local方法: 比如Skip-gram,基于窗口的局部方法
- Advantage: 随时增减,方便应用在大数据
- 不能全局think问题
二.词向量训练的常见方法
1.基于非语言模型方法
Skip-gram: 通过中心词预测上下文。 CBOW:通过上下文预测中心词。
NNLM方法: 给定句子 $s= w_1, w_2,w_3,w_4,w_5$。 通过最大化$P(w_2|w_1)\times P(w_3|w_2)\times P(w_4|w_3)\times P(w_5|w_4)$(二阶马尔科夫假设)来进行学习。
2.词向量的多义性问题
通过前面的方法训练出的每一个单词的词向量是固定的,但是在一些句子中一个单词通常代表不知一个意思,例如下句:
Yesterday,when he backed the car,he hurt his back.
所以,如何学出一个单词在不同上下文中的词向量呢?
 答案:ABCD
答案:ABCD
三.ELMO(deep contextualized word representations)
主要思想: 基于LSTM进行词向量学习->Deep BI-LSTM
但是这里的双向LSTM并不是真正意义上的双向,而是将两个LSTM的隐层拼在了一起。

启发:深度学习中的层次表示:例如下图,可以看出通过深度学习模型,可以学出每一个层级的特征,而随着层侧的增加,学习到的特征表示从简单到复杂,越来越能够表现出图像所表示的内容。

对于NLP,也有类似的特征:
Deep LSTM == ELMO:

训练及使用:
训练基于语言模型,通过输入语料来学习出模型的参数。
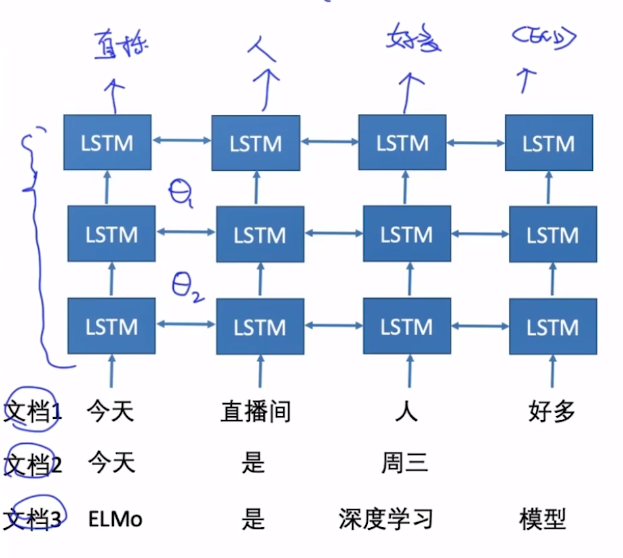
那么训练好参数的ELMo模型怎么使用呢?
- 对于第k个词条,L层的双向语言模型需要计算2L+1个表示(词的基向量+每层的双参数),如下:

- 对于特定的下游任务,ELMo将会学习一个权重来合并这些表示
