这篇文章我将按照本书中从上到下中重要的知识点顺序编写,word2vec,简而言之,就是讲自然语言中的词(word)转换成数学计算可用的向量(vector),本书请点击链接下载《word2vec中的数学原理》,为了方便理解以及找到重点,我在此书中使用红线做了适当的圈画及注释,使用wps2019应该可以显示。
Word2vec中的数学原理详解笔记
预备知识
基本的数学公式和数据结构知识
2.1 sigmoid函数
当成一个数学函数来理解,是神经网络中常用的激活函数之一。
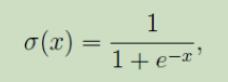
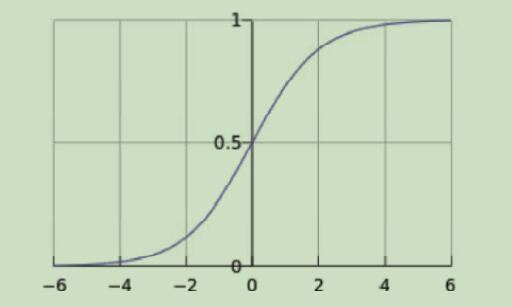
从图中可以看出,x大于0,y大于0.5;x小于0,y小于0.5,可应用于后续的二分类问题。
数学性质:
-
类奇函数,值域(0-1),定义域无穷
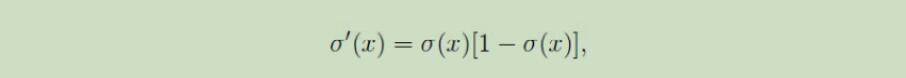
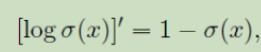
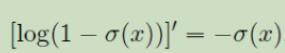
2.2逻辑回归
在这里我将其简单的理解为二分类问题:在样本集{x,y}中,yi=1相对应的xi为正例,yi=0相对应的样本xi为负例.
二分类的假设函数如下:
 其中θ为待定参数,令x0=1可简写为
其中θ为待定参数,令x0=1可简写为
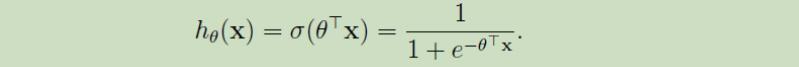 当阈值取T=0.5时,二分类的判别公式为
当阈值取T=0.5时,二分类的判别公式为
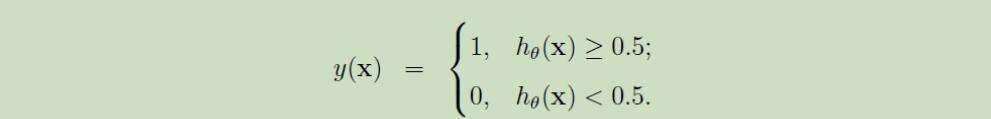 这里可以理解为,当计算出的h(x)>T时,y就是正例,否则,y是负例。
这里可以理解为,当计算出的h(x)>T时,y就是正例,否则,y是负例。
分类过程中的参数θ的求法:对如下整体损失函数进行优化,得到最优的参数θ*进行计算。
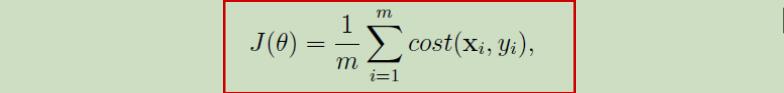
优化的方法,感觉是利用极大似然估计法,来求得未知参数的极大值或极小值。
单个样本的损失函数cost(xi,yi)的对数似然函数为:
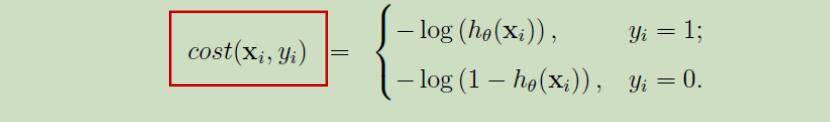
故,若将上述5个公式编号,整个二分类问题的执行过程如下:5->1->4->2->3。
2.3 贝叶斯公式
这里涉及先验概率和后验概率的概念。
定义:A为堵车事件,B为迟到事件
先验概率: 知因求果,已知事件A发生时求事件B发生的概率P(B|A),即当堵车时迟到的概率
后验概率: 知果求因,当事件B发生时,造成事件B发生的原因是事件A的概率P(A|B),即当你迟到并且原因是堵车的概率。
贝叶斯公式的作用: 用先验概率易知时可求后验概率,或后验概率易知时可求先验概率。
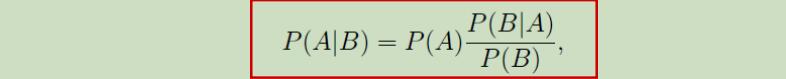
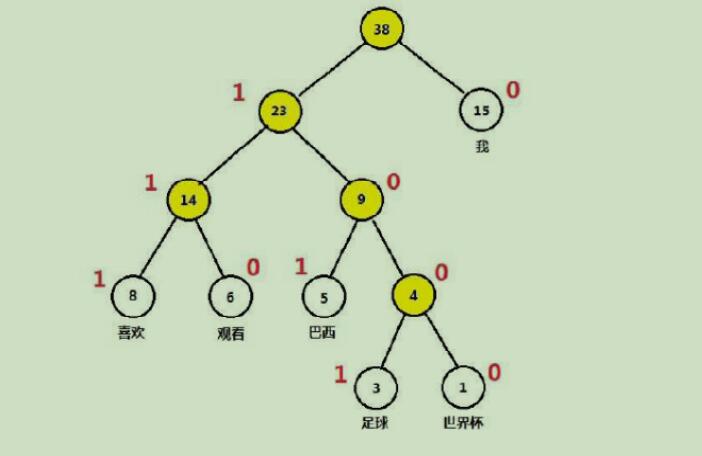
2.4 哈夫曼编码
所选取语料中的每个词的权值为该词在语料中出现的次数,每次选最小的两个节点合并形成哈夫曼树,根节点的权值为所有词出现总次数,新增非叶节点个数为n-1个,词频越大离根节点越近。

进行编码(左1,右0)
3.背景知识
自然语言处理(Nature Language Processing,NLP)
3.1 统计语言模型
统计语言模型是用来计算一个句子概率的概率模型。
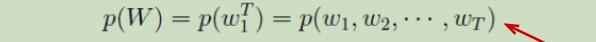 利用贝叶斯公式,可链式分解为:
利用贝叶斯公式,可链式分解为:
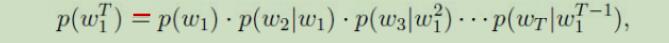
从上式中可以看出,统计语言模型的实质就是再求每个单词的条件概率,这些条件概率就是模型的参数,有了这些参数,就可以求得一个句子出现的概率。
3.2 n-gram模型
n-gram模型的实质就是将概率转化为次数,且每个单词仅与前n个单词相关。如下两图所示:
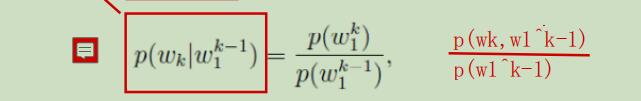 统计语言模型的参数。
统计语言模型的参数。
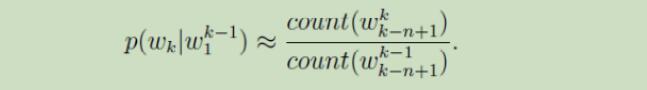
n-gram模型主要的两大问题:稀疏性和存储成本
稀疏性:
考虑如下问题:
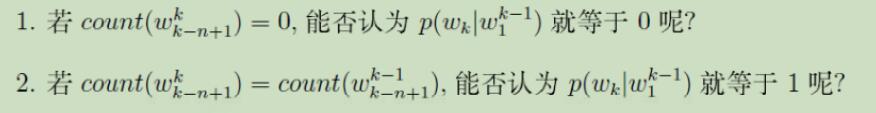 因此,需要进行平滑化处理。
因此,需要进行平滑化处理。
3.3 机器学习通用招数
在机器学习领域有一种通用的招数是这样的:对所考虑的问题建模后先为其构造一个目标函数,然后对这个目标函数进行优化,从而求得一组最优的参数没,最后利用这组最优参数对应的模型来进行预测。
问题建模-->构造目标函数-->优化-->最优参数-->预测


有了似然函数(即目标函数),即可利用极大似然估计法,来对函数进行最大化。

其中θ是待定的参数集,优化目标函数即可获得到最优参数集θ*。 得到了最优参数,即可利用对应的统计语言模型进行预测。
3.4神经概率语言模型
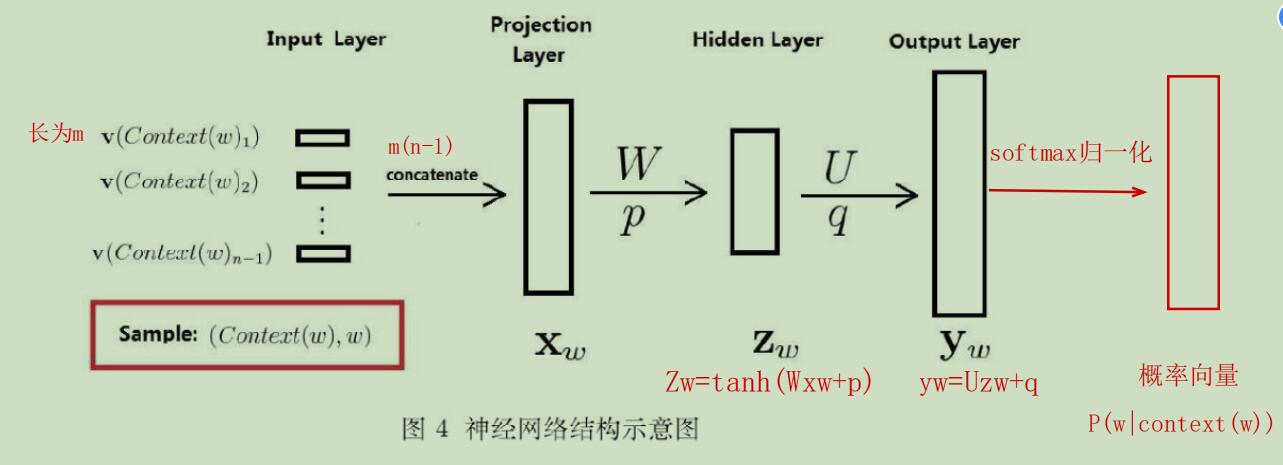
3.5 词向量的理解
词向量的表示方式:
-
one-hot representation 词向量的维数即词典D中所有的词的数量,一个词在词典D中是索引中的第几个,词向量中第几个分量为1,其他分量为0
-
Distributed Representation 基本思想:通过训练将某种语言中的每一个词映射成一个固定长度的较短向量,所有这些向量构成一个词向量空间,每一个向量则可视为该空间中的一个点。即可通过点之间的距离来判断词之间的相似性。
如何获取词向量?
LSA(Latent Semantic Analysis)和LDA(Latent Dirichlet Allocatiojn),还有神经网络模型的应用.以及下图。词向量可以通过神经网络模型训练获得。
$4. Naive Skip-gram和Naive CBOW
word2vec主要有两种算法:
- Continuous Bag of Words (CBOW):预测目标单词
- Skip-grams (SG):预测上下文
这两种算法都有更高效的训练方式:
- 基于Hierarchical softmax
- 基于Negative sampling
这一章节的内容将讲述原生的Skip-gram算法和CBOW算法,但在此书中没有讲述,是我在观看了cs224n课程后继续补充的。
4.1 Naive Skip-gram
4.1.1 Skip-gram基本思想
在拥有一大堆语料后,skip-gram算法 的目标为根据中心词$w_t$,来预测出其窗口词$w_{-t}$(除$w_t$之外所有的窗口词),用概率公式来表示就是 \(p(w_{-t}\|w_t)\) 当给定一个其中的窗口词$w_c$时,来预测在中心词$w_t$窗口词是有$w_c$的概率,则可定义损失函数如下:
\[J = 1-p(w_c\|w_t)\]如果概率$p(w_{c}|w_t)$很接近1,则损失很比较小,代表预测较为正确。
通过调整一个单词及其上下文单词的向量,使得根据两个向量可以推测两个词语的相似度;或根据向量可以预测词语的上下文。 从而可以学习得到具有分布式属性的词向量。
4.1.2 目标函数
skip-gram目标函数可以定义为是在中心词$w_t$的情况下,使窗口词被预测到的概率最大化:
\[J^{\prime}(\theta)=argmax \prod_{t=1}^{T} \prod_{-m \leqslant j \leqslant m} p(w_{t+j} \| w_{t} ; \theta)\]因为我们在机器学习问题中,一般喜欢进行最小化,所以我们在公式右边加了个负号,并且其对数似然函数形式如下:
\[J(\theta)=argmin -\frac{1}{T} \sum_{t=1}^{T} \sum_{-m \leqslant j \leqslant m} \log p(w_{t+j} \| w_{t};\theta)\]其中的细节说明:上下文概率可以由softmax函数得到
\[p(w_c \| w_t) = \frac{exp(w_c^Tw_t)}{\sum_{v=1}^V exp(w_v^Tw_t)}\]其中V为字典的大小,向量之间的点积操作可以看作为向量之间粗糙的相似度度量
4.1.3 网络结构
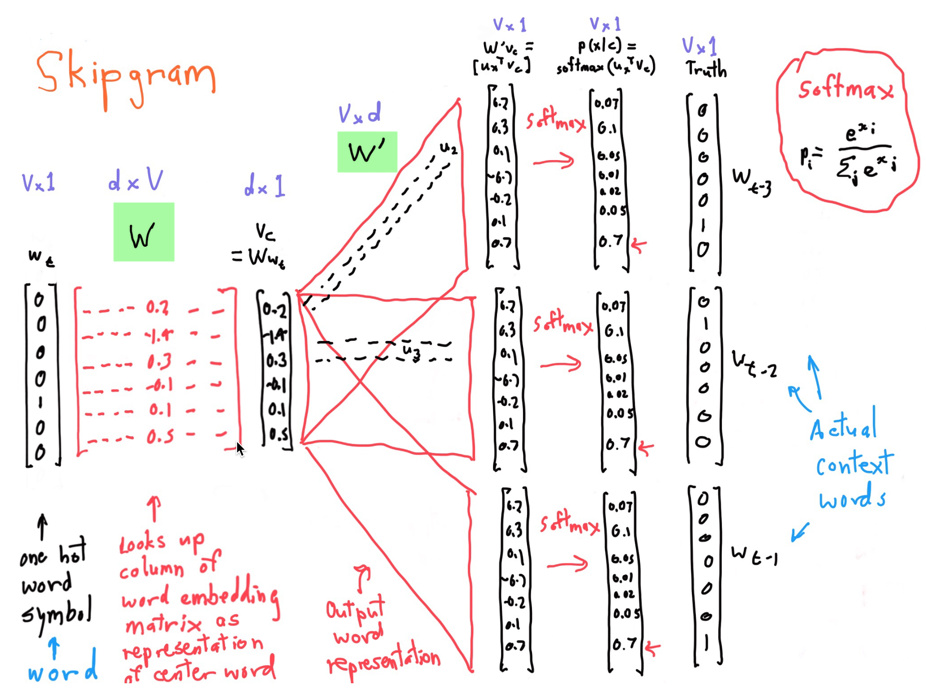
但是我们需要注意到一个问题,就是两个矩阵$W$和$W’$都含有V个词向量,也就是说同一个词有两个词向量,哪个作为最终的、提供给其他应用使用的embeddings呢?有两种策略,要么加起来,要么拼接起来。
4.1.4 目标函数优化
我们将所有的参数都放在$\theta$中,但是因为有两个参数矩阵,所以我们需要训练2倍的$d\times V$量的参数。
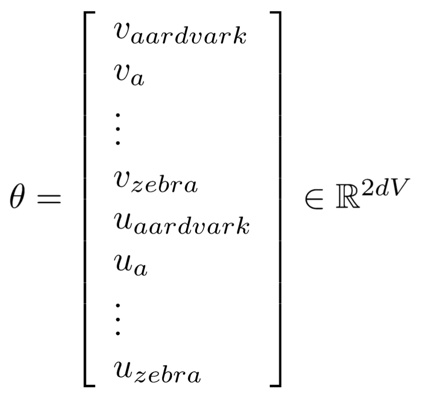 我们的目标函数为:
我们的目标函数为:
\(J(\theta)=argmin -\frac{1}{T} \sum_{t=1}^{T} \sum_{-m \leqslant j \leqslant m} \log p(w_{t+j} \| w_{t};\theta)\) 我们采用梯度下降的方法来对上式子求导,求出其梯度:
\(\begin{array}{l}{\frac{\partial}{\partial v_{c}} \log \frac{\exp (u_{0} ^T v_{c})}{\sum_{w=1} \exp (u_{u} v_{c})}} \\ {=\frac{\partial}{\partial v_{c}} \log \exp (u_{0}^{\top} v_{c})-\frac{\partial}{\partial v_{c}} \log \sum_{w=1}^{v} \exp (u_{w}^{\top} v_{c})} \\ = u_0 -\frac{1}{\sum_{w=1}^V \exp (u_w^Tv_c) }(\frac{\partial}{\partial v_c} \sum_{x=1}^V \exp(u_x^tv_c)) \\ =u_0 - \frac{1}{\sum_{w=1}^V \exp (u_w^Tv_c) }(\sum_{x=1}^V \exp(u_x^tv_c)u_x) \\ =u_0 - \sum_{x=1}^V \frac{\exp(u_x^Tv_c)u_x}{\sum_{w=1}^V \exp(u_w^Tv_c)} \\ =u_0 -\sum_{x=1}^V p(u_x\|v_c)u_x \end{array}\)
$5 基于Hierarchical Softmax的模型
5.1 CBOW模型
5.1.1 网络结构
目标函数为优化$p(w|context(w))$
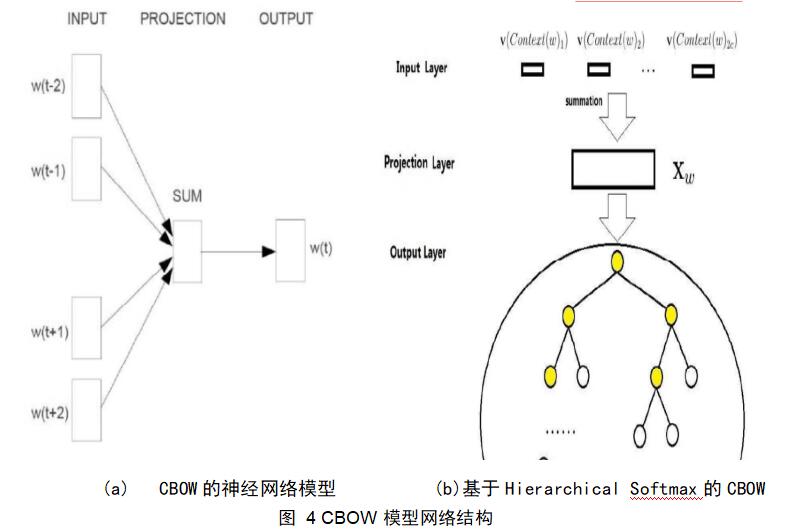
基于Hierarchical Softmax的CBOW模型如图4(a)显示,是在已知中心词上下文context(w)的情况下,预测其中心词w,包括输入层、投影层、输出层三层。更为详细点的模型图如图5(b)所示,输入层的输入为当前样本中心词的所有上下文词向量,投影层的功能是将输入层所有词向量累加求和,而输出层则是经过Huffman树进行目标优化后再经过softmax后的词概率。
5.1.2 目标函数优化过程
根据图中的Huffman树,还需要定义以下符号:(1)$p^w$ 为从根节点出发到达词w所对应叶子节点的路径;(2)$l^w$为$p^w$上所包含的节点个数;(3)$d_j^w$代表着$p^w$中第j个节点对应的编码,左节点编码为0,右节点编码为1。
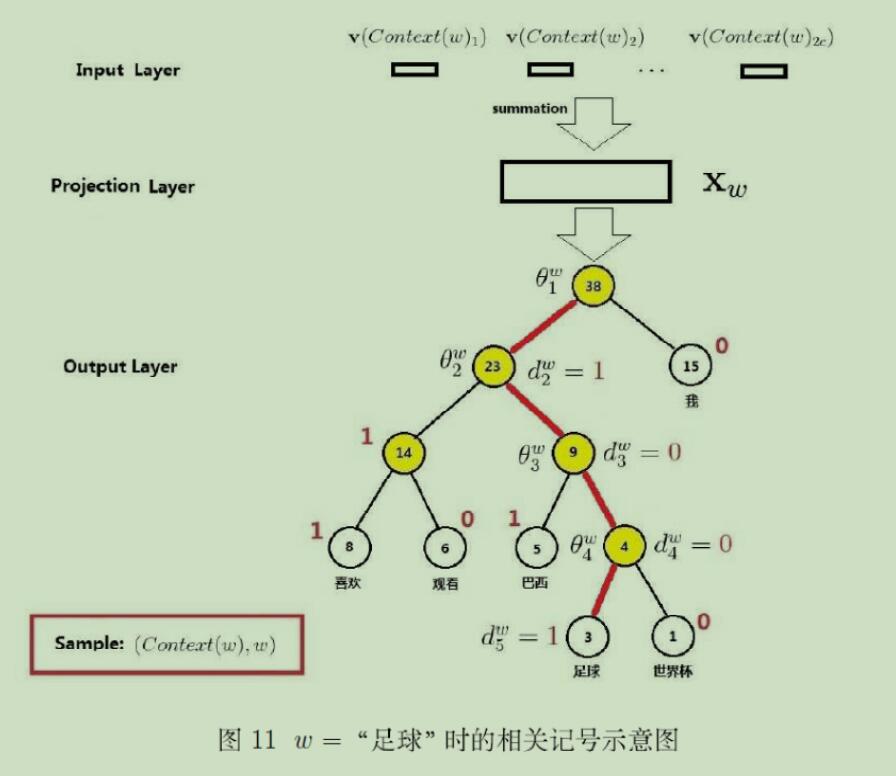
这里Huffman树建立的方式如下:投影层的输入为上下文2c个向量,输出为上下文2c个向量的累加。Huffman树的叶子节点为该词典中的所有词,每个词的权重为这个词在语料中出现的次数。生成后的Huffman树的根节点的向量表示就为Xw。输出层的输出为从根节点到每个词的概率再经过softmax后最大的那个词。参数θ 是一个辅助向量。
从根节点$x_w$到目的节点预测中心词之间的每一次分支都可以看成进行了一次二分类,分到左边的是负类,右边的是正类。
根据逻辑回归,分到正类的概率是:
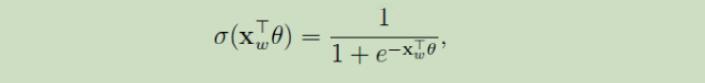 分到负类的概率是:
分到负类的概率是:
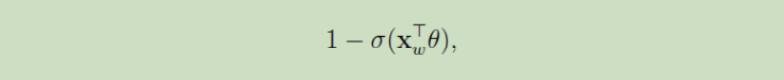
对一词典D中的任意词w,在Huffman树中必有根节点到w节点的唯一路径pw,路径pw上存在lw-1次分支,每次分支都是一次二分类,将路径上所以分类的概率连乘起来,就是所需的$p(w丨contexe(w))$

5.1.3 随机梯度上升法
将目标函数(p(w|Context(w))) 做其对数似然函数
 L(w,j)表示双重累加符号,故目标函数可简写为
L(w,j)表示双重累加符号,故目标函数可简写为
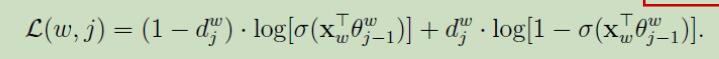 这就是CBOW模型的目标函数,使这个函数最大化(优化),这里采用的是随机梯度上升法.
首先梯度的计算:
对上式中两个未知参数Xw,θ求偏导
这就是CBOW模型的目标函数,使这个函数最大化(优化),这里采用的是随机梯度上升法.
首先梯度的计算:
对上式中两个未知参数Xw,θ求偏导
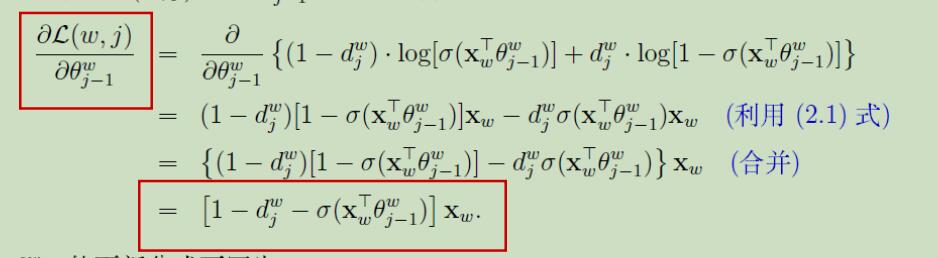
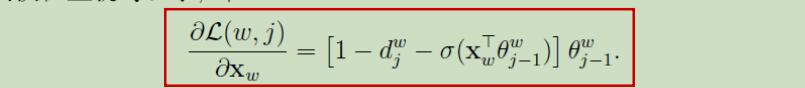
两个参数的更新公式:
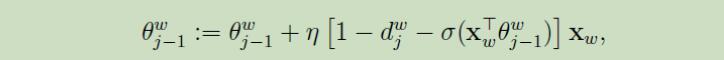

5.1.4 算法总结
CBOW的目标函数是$P(w丨context(w))$,所以经过softmax后此模型的输出时概率最大的那个词。并且词向量的产生只是优化该目标函数时产生的副产品,且副产品不仅仅为2c个上下文的词向量,还有能使得目标函数最大化的辅助向量θ。详细见伪代码。
算法流程:
- 基于语料训练样本建立霍夫曼树。
- 随机初始化所有的模型参数θ,所有的词向量w。
- 进行梯度上升迭代
- 更新context(w)的词向量

5.2 Skip-gram模型
5.2.1 网络结构
优化目标函数为$P(context(w)|w)$
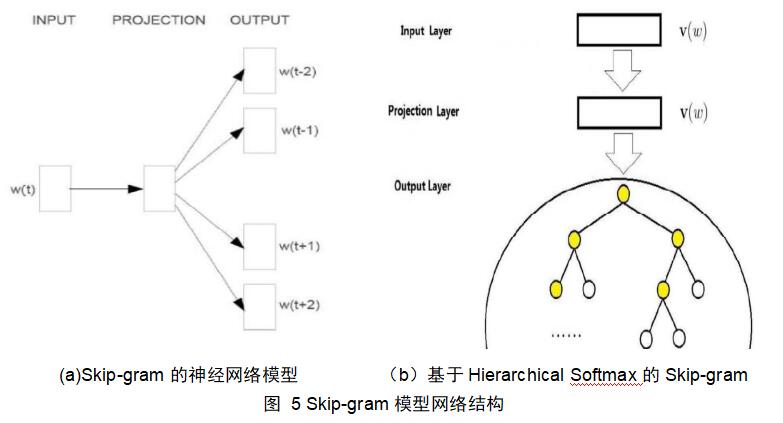 基于Hierarchical Softmax的Skip-gram模型如图5(a)显示,是在已知当前词wt的情况下,预测其上下文wt-2,wt-1,wt+1,wt+2,包括输入层、投影层、输出层三层。更为详细点的模型图如图5(b)所示,输入层的输入为当前样本中心词的词向量v(w),投影层的功能只是个恒等映射,故投影层的输出仍然为v(w),而输出层则是经过Huffman树进行目标优化后再经过softmax后的词概率。
基于Hierarchical Softmax的Skip-gram模型如图5(a)显示,是在已知当前词wt的情况下,预测其上下文wt-2,wt-1,wt+1,wt+2,包括输入层、投影层、输出层三层。更为详细点的模型图如图5(b)所示,输入层的输入为当前样本中心词的词向量v(w),投影层的功能只是个恒等映射,故投影层的输出仍然为v(w),而输出层则是经过Huffman树进行目标优化后再经过softmax后的词概率。
5.2.2 目标函数优化
目标函数可以进行展开
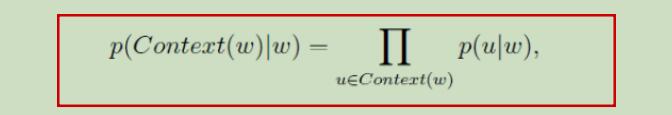
这里我们将图5(b)中输出层的Huffman树建立过程描述如下: 由语料中所有出现过的词作为叶子节点,根据每个词在语料中出现的次数作为叶子节点的权重,并依此建立起Huffman树。Huffman树的根节点的向量表示为输出层的输入v(w)(之后用Xw表示),所有新增的非叶节点的向量表示为辅助向量θ,所有叶子节点的向量表示为对应词的词向量。
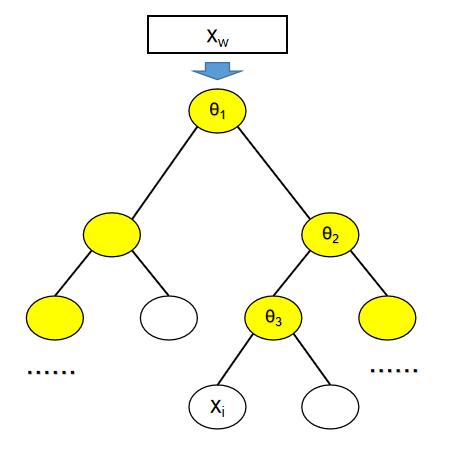 基于Hierarchical Softmax的Skip-gram模型中是这样来表示在已知中心词xw求其上下文词的概率,即$Pr(u|x_w)$:以图6为例,从中心词$x_w$所对应的根节点开始形成到其上下文$x_i$的路径$p^i$,在$p^i$中从根节点开始每遇到一个非叶节点就要做一次二分类,使用逻辑回归分别计算出到该非叶节点2个孩子的概率,规定该飞叶子节点到其左边孩子节点的概率为$1-σ(x_w^Tθ)$,到其右边孩子节点的概率为$σ(x_w^Tθ)$,将$p^i$所有经过节点的概率相乘,就得到了$Pr(x_i|x_w)$。
基于Hierarchical Softmax的Skip-gram模型中是这样来表示在已知中心词xw求其上下文词的概率,即$Pr(u|x_w)$:以图6为例,从中心词$x_w$所对应的根节点开始形成到其上下文$x_i$的路径$p^i$,在$p^i$中从根节点开始每遇到一个非叶节点就要做一次二分类,使用逻辑回归分别计算出到该非叶节点2个孩子的概率,规定该飞叶子节点到其左边孩子节点的概率为$1-σ(x_w^Tθ)$,到其右边孩子节点的概率为$σ(x_w^Tθ)$,将$p^i$所有经过节点的概率相乘,就得到了$Pr(x_i|x_w)$。
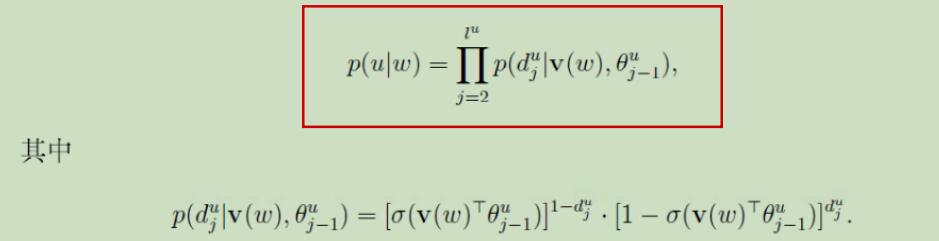 但是这里得到的是,$x_i$只是语料中心词w上下文的一个,若我们对上下文所有词都进行这样的计算,同时将目标函数进行最大化,再经过softmax归一化后得到的将是语料中每个词成为中心词w上下文的概率,概率最大的2w个词即可作为预测出的上下文。
对目标函数做其对数似然函数,并简化为:
但是这里得到的是,$x_i$只是语料中心词w上下文的一个,若我们对上下文所有词都进行这样的计算,同时将目标函数进行最大化,再经过softmax归一化后得到的将是语料中每个词成为中心词w上下文的概率,概率最大的2w个词即可作为预测出的上下文。
对目标函数做其对数似然函数,并简化为:
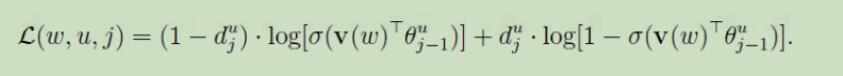
但是我们的任务是获得词向量,研究目标函数的优化过程可以发现,所需的词向量其实只是优化过程中产生的一个副产品,所以为了获得词向量并不需要完整的Skip-gram模型,优化过程如下:对目标函数使用随机梯度上升算法进行最大化,可以得到参数$x_w$和θ的更新公式为:
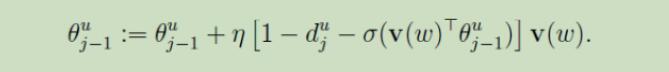

由此可得基于Hierarchical Softmax的Skip-gram模型运作流程总结如下:

5.2.3另一种实现方案
上面是根据原文献文献中词嵌入技术发明者提出skip-gram模型的理论实现方案,由流程中的c)可得该模型运行一次仅能得出中心词w的词向量,嵌入效率低于能一次更新所有上下文词向量的CBOW模型。在之后的word2vec技术实现中,根据上下文的作用是相互的,期望最大化$Pr(u|x_w)$等同于期望最大化$Pr(x_w|u)$,因此将优化目标由$Pr(u|x_w)$变成了$Pr(x_w|u)$。
改进后的Huffman树如下:
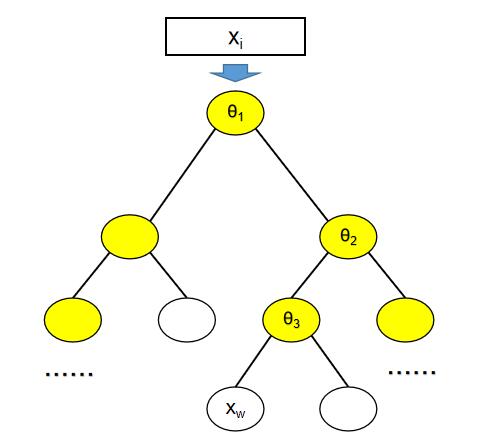 Huffman树的输入变成了上下文中的词的向量xi,目标路径通往中心词w对应的节点。优化后的基于Hierarchical Softmax的Skip-gram模型运作流程如下:
Huffman树的输入变成了上下文中的词的向量xi,目标路径通往中心词w对应的节点。优化后的基于Hierarchical Softmax的Skip-gram模型运作流程如下:

$6 基于Negative Sampling的模型
NEG不再采用复杂的Huffman树,而是利用相对简单的随机负采样,大幅提高性能。
6.1 CBOW模型

对于给定的一个正样本(Context(w),w),目标函数为
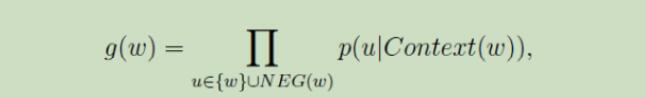 其中,
其中,
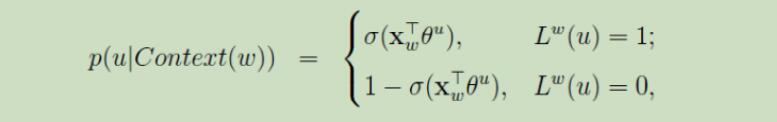 对g(w)最大化时,可以增大正样本的概率同时降低负样本的概率,故可以作为整体优化的目标。
取g(w)的对数似然函数
对g(w)最大化时,可以增大正样本的概率同时降低负样本的概率,故可以作为整体优化的目标。
取g(w)的对数似然函数
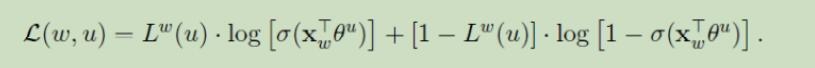
计算梯度,并可得更新公式
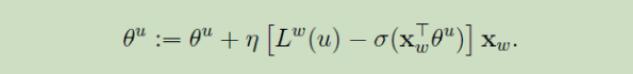
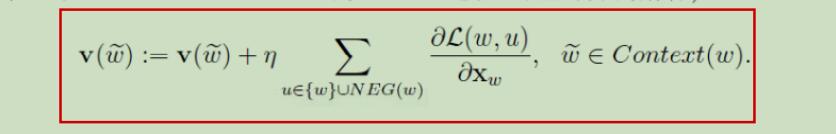
6.2 Skip-gram模型
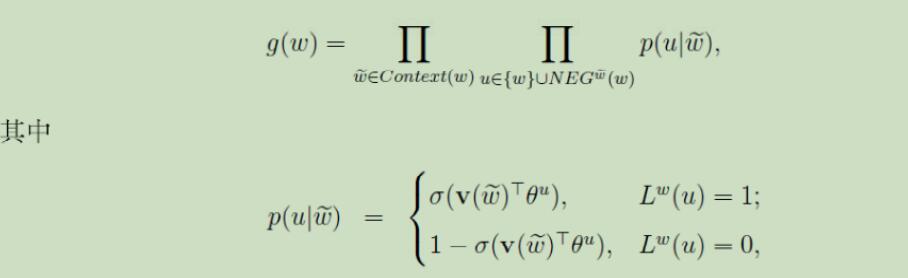 最大化g(w),做g(w)的对数似然函数:
最大化g(w),做g(w)的对数似然函数:
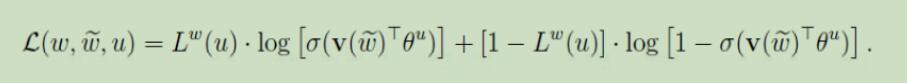
得到更新公式
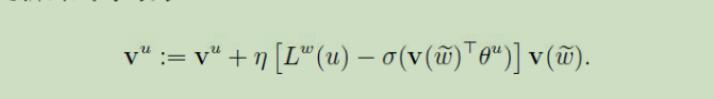
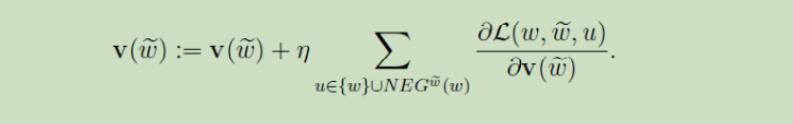
6.3 负采样算法
负采样即给定一个词w,如何生成NEG(W)?
负采样的过程本质是一个带权采样的过程
将[0-1]根据每个次的长度(出现次数)不等均分为In。
再根据词的个数n等分为Mn。建立的映射关系如下:

生成随机数,根据映射m寻找相应的I进行采样。
由此,对于高频词,被选为负样本的概率就大些,对于低频词,被选为负样本的概率就小些。