网易公开课视频地址:http://open.163.com/movie/2008/1/M/C/M6SGF6VB4_M6SGHFBMC.html?frm=record 课程主页地址:http://cs229.stanford.edu/
Lecture 1 -Introduction and Basic Concepts
机器学习定义
Tom Mitchell:对于一个计算机程序来说,给它一个任务T以及一个性能测量方法P,如果在经验E的影响下,P对T的测量结果得到了改进,那就说明计算机程序从E中学习。
监督学习
如图所示,当给定一组房屋的数据,想预测自己房屋大概值得多少钱怎么办?
根据已知的样本点,画一条一次曲线,从x轴上找到自己房屋大小,其对应直线上的纵坐标即预测的价格。 或者画一条对数据拟合更好的二次曲线,可以看出,预测的结果比一次曲线要高一些。
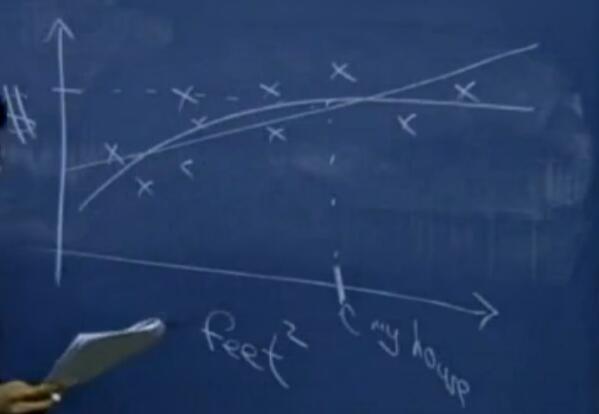
在本例中,之所以称之为监督学习,是因为我们提供了一组正确的房屋面积–价格的对应数据,或者说输入算法的“标准答案”,希望算法去学习标准输入(面积)与标准答案(价格)之间的联系,当我们提供其他的输入时,能为我们提供更为标准的答案。
这类问题其实是属于回归问题(Regression),又或者说是分类问题。 见下面这个例子,给了一组乳腺癌的数据,横纵坐标代表肿瘤大小和年龄,其中x代表恶性肿瘤,o代表良性肿瘤。当给定一个新病人时,如何判断是良性or恶性肿瘤?
机器学习算法,可能会画出如图的一条线,将两类肿瘤分开,根据新病人的肿瘤大小和年龄找到相应的点,然后判断出新病人患的是良性肿瘤,而不是恶性肿瘤。
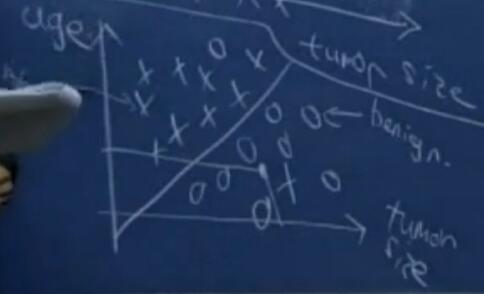
上例中,判断肿瘤类别中用了肿瘤大小和年龄两个属性,但在实际中,判断一个肿瘤是良性还是恶性,还要用到细胞大小、数量等属性,这样样本点就不能像上图一样在二维空间表示出来,那么如果用多维空间或者二维空间表示这些样本点呢?
支持向量机(SVM)算法可以把数据映射到无限维空间中。
无监督学习
同样的乳腺癌例子,但不同的是,这次没有标记出每个样本是良性的还是恶性的,需要机器学习算法从样本中自己寻找些有趣的数据结构,这就是无监督学习要做的事情。

机器学习算法有可能找到这样的数据结构,将样本划分为两类,其中一类是良性肿瘤,另一类是恶性肿瘤。这就演变成了聚类问题,聚类问题是无监督学习中的一种。

强化学习(Reinforcement Learning)
强化学习通常是在一段时间内做出一系列的决定,列如编写一个无人驾驶飞机的程序,当进行了一系列不正确的决策时,直升机会立马掉下来,这时就将这些不正确的操作标记为bad!bad!bad!,而当进行了一系列正确的决策时,直升机能够平稳飞行,就将这些决策标记成good! 对直升机进行不断的学习,通过这些标记,来找寻一条正确的决策路线。