关于Node2vec算法很好的讲解教程:https://zhuanlan.zhihu.com/p/46344860 OpenNe代码可以在github上找到
OpenNe源码解析之Node2vec
Node2vec 伪代码
 对伪代码逻辑简单的解读:
算法一:
对伪代码逻辑简单的解读:
算法一:
输入参数:图G(节点,边,权值),向量维数d,每个节点游走次数r,游走长度l,上下文大小k,广度权值p,深度权值q
第一步:根据p,q的值对图G的权值进行预处理,得到每个点到其邻居节点的转移概率π
第二步:将转移概率π添加到图G中,形成概率图G’=(V,E,π)
第三步:将存储游走路劲的存储结构walks 初始化
第四、五、六、七步:对概率图G’每个点进行长度为l的游走,游走路径存储到walks,并重复r次
第八步:使用随即梯度下降算法对获得的路径语料进行训练,获得向量
算法二:
输入参数:概率图G(V,E,π),起始节点u,游走长度l
第一步:初始化起始节点u的路径walk
第二步:进行l步的游走
第三步:获取游走路径中的最后的一个节点为当前节点
第四步:获取当前节点的邻居节点
第五步:根据概率对邻居节点进行取样,取出下一个节点
第六步:将这个节点添加到游走路径中
Node2vec源码解读
这里首先整理下Node2vec中函数的调用逻辑:
main(args) #主函数
--g = Graph() #初始化图g
--g.read_adjlist(filename=args.input) #读邻接表
--model = node2vec.Node2vec(...)
--__init__(self, graph, path_length, num_paths, dim, p=1.0, q=1.0, dw=False, **kwargs) #构造函数
--walker.Walker(graph, p=p, q=q, workers=kwargs["workers"]) #Walker构造函数
--self.walker.preprocess_transition_probs() #预处理转移概率
--alias_setup(normalized_probs) 使用alias方法处理节点概率
--get_alias_edge(edge[0], edge[1]) #使用alias方法处理边概率
--self.walker.simulate_walks(num_walks=num_paths, walk_length=path_length) #重复模拟随机游走
--self.node2vec_walk(walk_length=walk_length, start_node=node) #获取对每个节点进行一次游走
--Word2Vec(**kwargs) #进行训练
--save_embeddings(args.output) #存储训练结果
下面进行详细的代码解读:
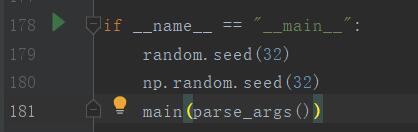
1. 在__main__.py第181行调用主函数
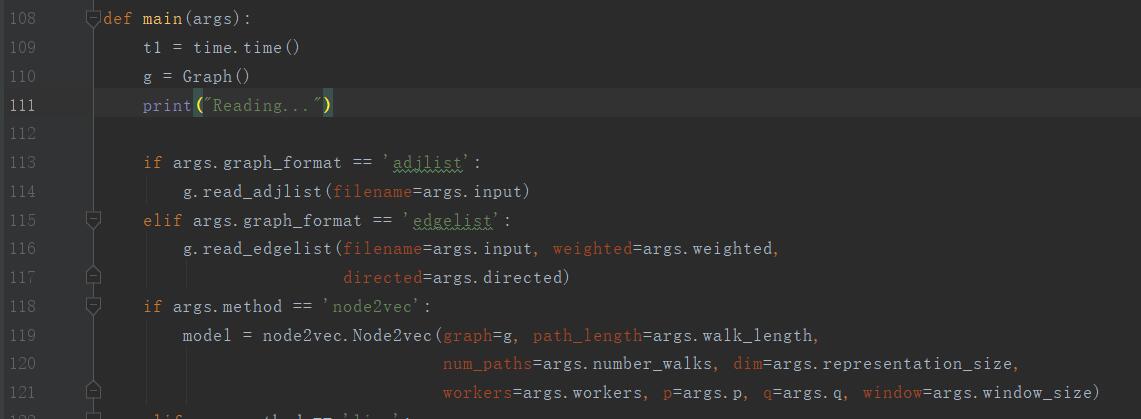
第110行初始化图g
第114行从文件中读取邻接表
第119行初始化Nodevec类
参数:graph(图),path_length(游走长度),num_paths(游走次数),dim(向量维度),workers(并发数),p(参数p),q(参数q),window(窗口大小)
2. 在node2vec.py第9行调用node2vec构造函数
第11行获取并发数
第21行调用node2vec的Walker类
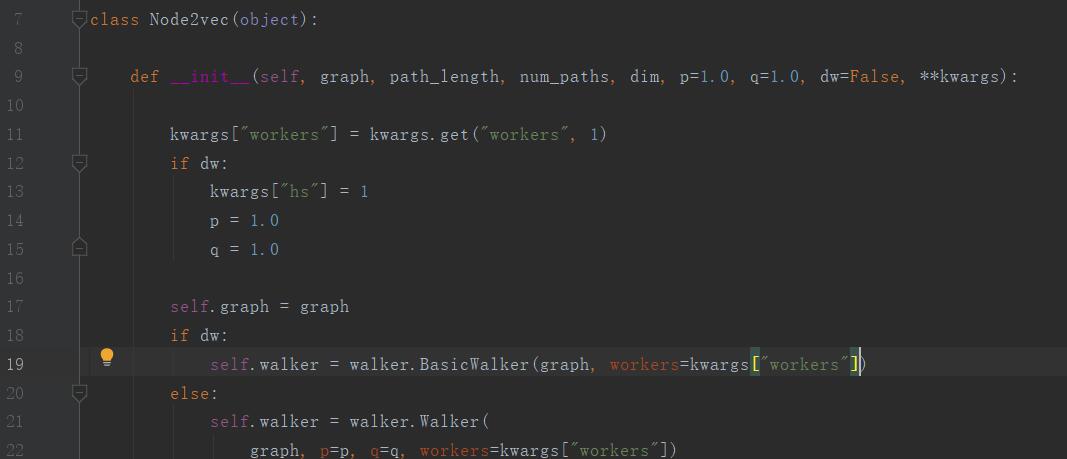
在walker.py中第58行,Walker类的构造函数如下:
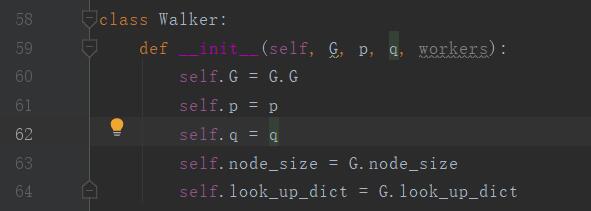 第60、61、62、64、65行,进行参数赋值
第60、61、62、64、65行,进行参数赋值
3. 在node2vec.py第24行 初始化转移概率

preprocess_transition_probs函数的申明在walker.py第135行
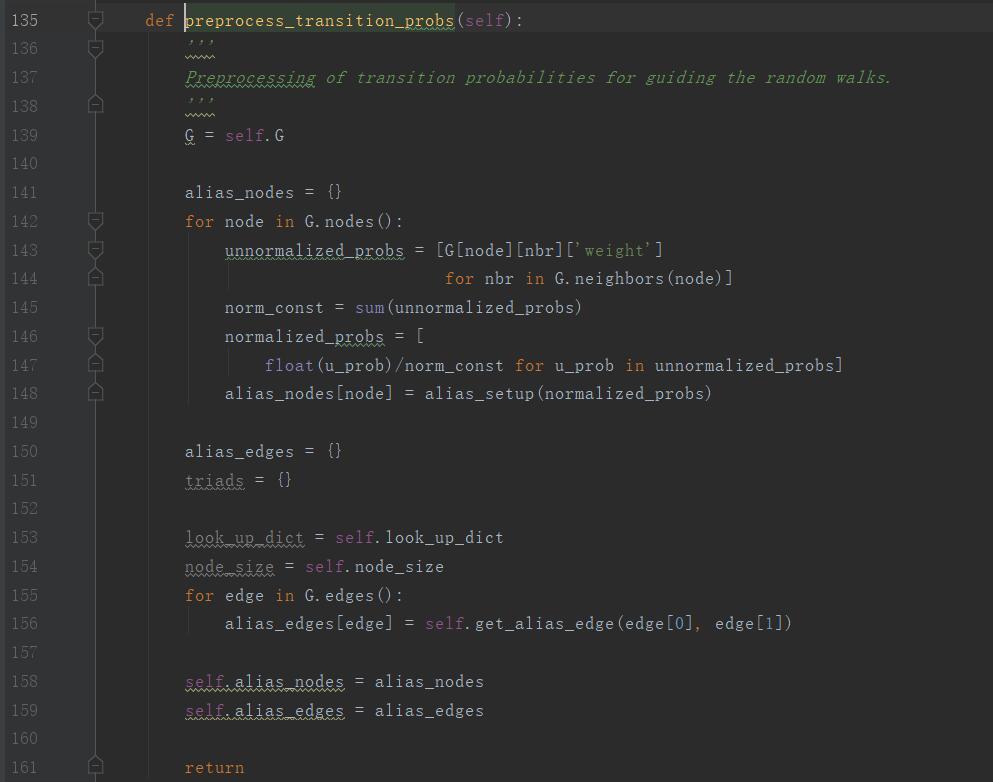 第141行,初始化alias节点列表
第141行,初始化alias节点列表
第142行,对图G中的每个节点node做如下遍历:
第143行,存储该节点所有邻居的权值
第145行,对改点所有邻居节点的权值进行累加求和
第146行,改点的每个邻居节点的权值/总权值,得到改点到每个点的概率
第148行,使用alias_nodes存储该节点经过alias方法,获得处理后的概率数组,和alias数组,该方法具体解释见Alias Method离散分布随机取样
第150行,初始化alias边列表
第155行:对图G中的每条边做如下遍历:
对每条边使用get_alias_edge函数进行处理,获得alias方法处理后的边转移数组和alias数组。
get_alias_edge函数的定义如下:
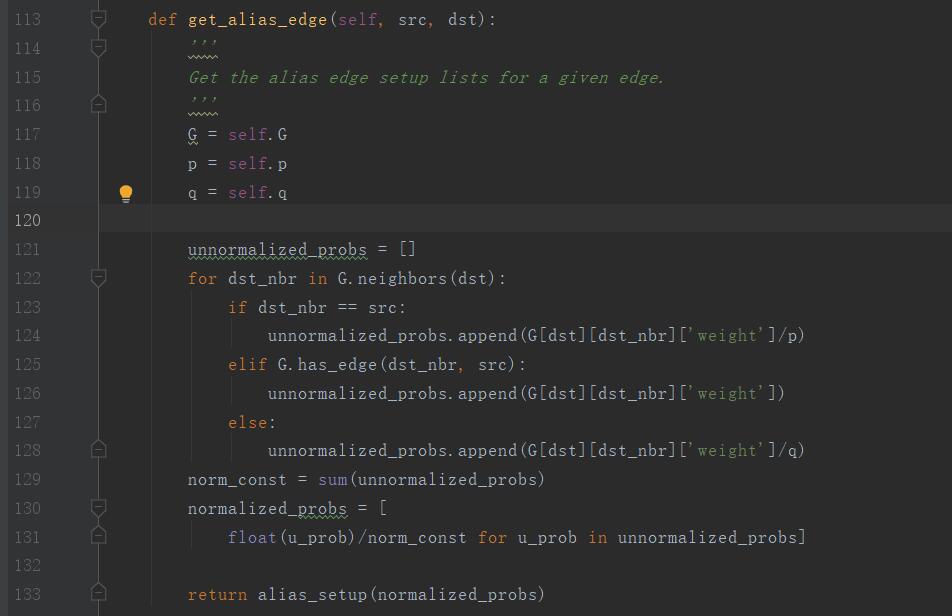 第117、118、119行,初始化赋值
第117、118、119行,初始化赋值
第121行,初始化概率列表
第122行,对这条边的目的节点对的所有邻居中,做如下遍历:
第123、124行,如果目的节点的此邻居与起始节点相同,则目的节点和此邻居边的权值为p分之一
第125、126行,如果目的节点的此邻居和起始节点相连,则目的节点和此邻居边的权值为1
第127、128行,如果目的节点的此邻居和起始节点不相连,则目的节点和此邻居边的权值为q分之一
第129行,累加所有的权值
第130行,对所有的边的权值/总权值,得到每条边的转移概率
第133行,对这些边的转移概率使用alias方法进行初始化,得到概率列表和alias列表
4. 返回到node2vec.py中第25行进行模拟游走

在walker.py中第96行,simulate_walks函数的定义如下:
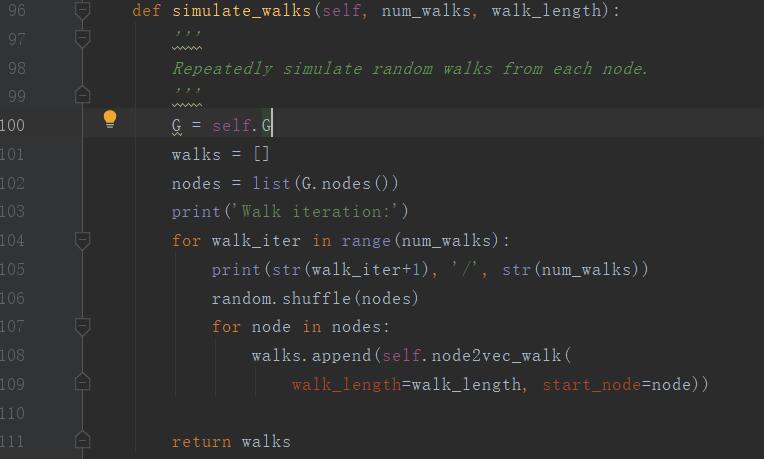
第101行,初始化walks列表,用于存储之后的游走路径
第102行,将图中的所有节点以列表的形式来存储
第104行,进行num_walks次游走,并且每次游走按照如下进行:
—-第106行,随机将列表中的节点随机打乱,以进行随机取样
—-第107行,对于列表中的每个节点进行如下操作:
———第108行,对每个节点进行以此节点为起始节点长度为walk_length的node2vec游走
其中,在walker.py第66行node2vec游走的具体定义如下:
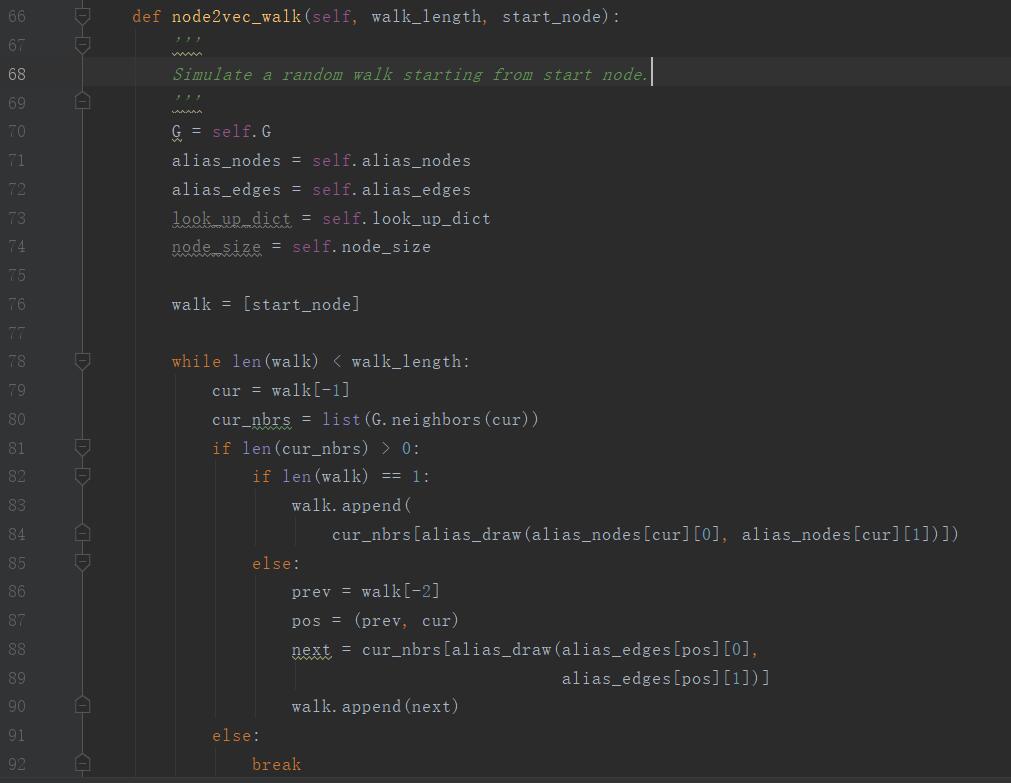 第71、72行,赋值alias节点和alias边
第71、72行,赋值alias节点和alias边
第76行,将开始节点存入walk中
第78行,当游走长度小于walk_length时,进行如下操作:
———第79行,获取walk中的最后一个节点
———第80行,获取此节点的邻居列表
———第81行,如果此列表中还存在节点
———第82,83行,walk中只存在一个节点,使用alias方法随机从它的邻居中抽取一个点存入路径
———第85、86、87、88、90行,取出倒数第二个节点,生成最后两个节点的一条边,获取使用改进后alias方法获取下一节点,存入此节点
5. 返回到node2vec.py中第27行,进行语料训练
下面这一段代码就是准备word2vec算法的参数,然后运行算法。
由于先前的代码中也有一部分参数,这里就把运行node2vec所用的kwargs参数整理下:
第11行: works代表线程数,但是并发数,此处使用的默认值8
 第13行,hs为1代表hierarchical softmax模型,0为negative sampling模型
第13行,hs为1代表hierarchical softmax模型,0为negative sampling模型
 第27行,sentences代表要训练的语料,这里就是所有的游走序列。
第27行,sentences代表要训练的语料,这里就是所有的游走序列。
 第28行,min_count代表低频词丢弃,这里使用默认值0,即不丢弃任何低频词。
第28行,min_count代表低频词丢弃,这里使用默认值0,即不丢弃任何低频词。
 第29行,size代表向量维度,这里使用默认的180
第29行,size代表向量维度,这里使用默认的180
 第30行,sg代表为0,对应CBOW算法;sg=1则采用skip-gram算法。这里采用skip-gram
第30行,sg代表为0,对应CBOW算法;sg=1则采用skip-gram算法。这里采用skip-gram

第34行,即进行hierarchical softmax下的skip-gram算法,进行训练
第36,37行,存储每个节点及其对应的向量
