视频地址:https://www.bilibili.com/video/av41393758/?p=3 课程主页地址:http://web.stanford.edu/class/cs224n/ 课程讲义下载地址:https://yunlongs-1253041399.cos.ap-chengdu.myqcloud.com/Books/CS224n/cs224n-2019-notes02-wordvecs2%E7%AC%94%E8%AE%B0.pdf
Lecture 3 - Glove,Evaluation and Training
Lecture1的内容主要是介绍NLP相关的概念,Lecture2的内容主要介绍了Skip-gram模型,见Word2vec中的数学原理详解笔记
1. Global Vectors for Word Representation(GloVe)
扩展阅读:https://blog.csdn.net/linchuhai/article/details/97135612
1.1 与先前面模型的比较
在之前我们主要两类词嵌入的方法:
- 1.基于统计和矩阵分解的算法(LSA,HAL)
-
- 优点:能有效利用全局统计信息。
-
- 缺点:捕捉的主要是词的相似性,在词的类比、指示词空间的结构上较为欠缺
- 2.基于浅层窗口预测的模型(Skip-gram,CBOW)
-
- 优点:不仅能捕捉词的相似性,还能够捕捉复杂的语言结构
-
- 缺点:未能利用全局共存的统计信息
相对的,GloVe结合以上两种模型的优点进行了改进,GloVe由一个加权最小平方模型组成,此模型基于全局词与词之间的共存计数来训练,所以能够有效的利用统计信息。此模型还可以产生一个具有子结构意义的词向量空间。
GloVe在词类比任务中具有卓越的标签,并且再其他的任务中也比之前的模型要好。
1.2共存矩阵(Co-occurrence Matrix)
共存矩阵的例子如下:
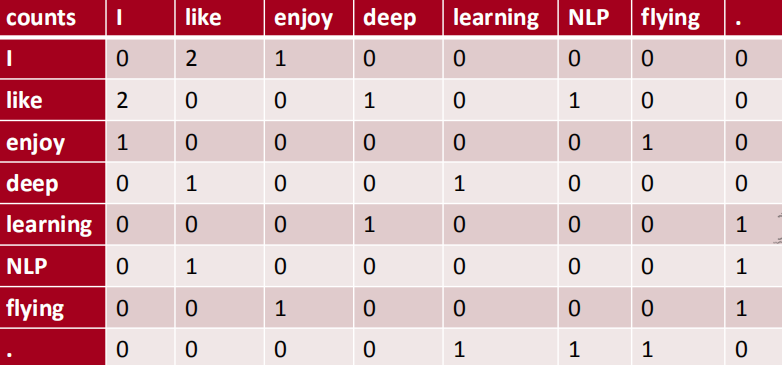
我们定义如下符号:
- $X$代表共存矩阵
- $X_{ij}$表示词j出现在词i的上下文中的次数
- $X_{i}=\Sigma_{k} X_{i k}$为出现在词i上下文所有词的个数
- $P_{i j}=P(w_{j} | w_{i})=\frac{X_{i j}}{X_{i}}$为词j出现在词i上下文的概率
显而易见,填充此矩阵的工作量非常巨大,至少需要遍历一遍完整的语料,但还好共存矩阵只需要计算一次。
1.3 最小平方目标函数(Lease Squares Objective)
回忆在skip-gram模型中,我们计算$p(u_j | v_i)$的softmax函数如下:
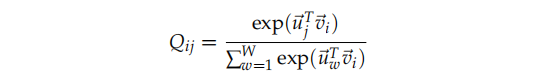 它的训练过程可以使用随机的方法,但是我们需要注意到全局的交叉熵损失要计算如下:
它的训练过程可以使用随机的方法,但是我们需要注意到全局的交叉熵损失要计算如下:
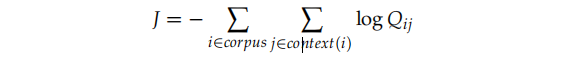
正如相同的词i和j可以多次的出现在语料中,如果我们首先将相同值的i和j聚在一起,会更加的高效:
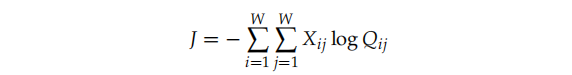
但是上式子有一个问答的缺点,就是$Q_{ij}$的计算需要遍历整个词汇表,其中的累加和点积计算代价很昂贵 ,所以我们使用如下最小平方目标函数:
 其中$\hat P_{ij}=X_{i j}$和$\hat Q_{i j}=\exp \left(\vec u_{j}^{T} \vec{v}_{i}\right)$都是未标准化的分布。
其中$\hat P_{ij}=X_{i j}$和$\hat Q_{i j}=\exp \left(\vec u_{j}^{T} \vec{v}_{i}\right)$都是未标准化的分布。
这是这个公式又会引入一个新的问题,$X_{ij}$通常取很大的值,这将导致优化变得困难,所以我们有做了如下的改进:
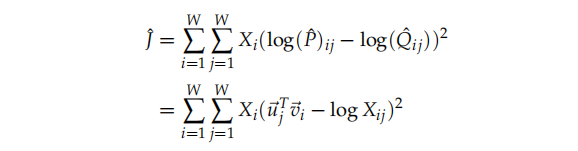
权重因子$X_i$并不保证时最优的,继而,我们可以引入一个更加普遍的权值函数:

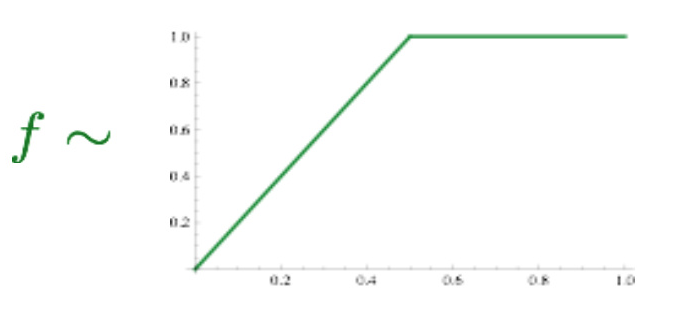
f是一个max函数:
明眼人会发现这里面有两个向量uu和vv,它们都捕捉了共现信息,怎么处理呢?试验证明,最佳方案是简单地加起来: $X_{\text {final}}=U+V$
2. 词向量的评估
有两种方法:Intrinsic(内部) vs extrinsic(外部)
Intrinsic: 专门设计单独的试验,由人工标注词语或句子相似度,与模型结果对比。好处是是计算速度快,但不知道对实际应用有无帮助。有人花了几年时间提高了在某个数据集上的分数,当将其词向量用于真实任务时并没有多少提高效果。
Extrinsic: 通过对外部实际应用的效果提升来体现。耗时较长,不能排除是否是新的词向量与旧系统的某种契合度产生。需要至少两个subsystems同时证明。这类评测中,往往会用pre-train的向量在外部任务的语料上retrain。
2.1 内部评估例子:词向量类比
例如,我们希望这道这种关系$x_b-x_a = x_d-x_c$,比如:(国王-王后 = 男演员 - 女演员)
\(d=\underset{i}{\operatorname{argmax}} \frac{\left(x_{b}-x_{a}+x_{c}\right)^{T} x_{i}}{\left\|x_{b}-x_{a}+x_{c}\right\|}\)
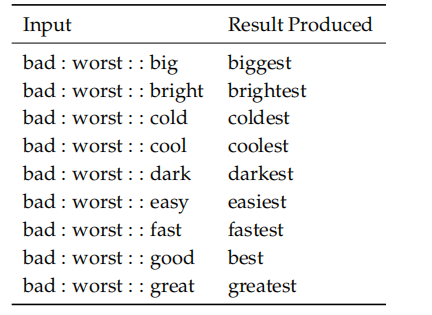
2.2 内部评估调试例子:类比性能评估
要对比各种算法模型的优劣的话,我们需要先统一个模型的超参数,其中可能涉及到的超参数如下:
- 词向量的维度
- 语料大小
- 语料来源
- 上下文窗口的大小
- 上下文窗口是否对称
例如对于GloVe算法,考虑窗口是否对称(还是只考虑前面的单词),向量维度,窗口大小:
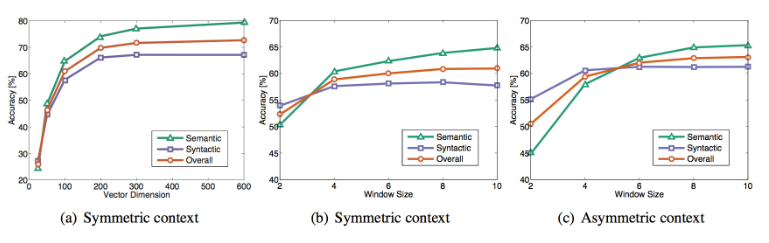 可以看见,当向量维度到300就已经足够,对称的窗口大小为6或7时,可以避免不必要的内存消耗。
可以看见,当向量维度到300就已经足够,对称的窗口大小为6或7时,可以避免不必要的内存消耗。
其迭代次数关系如下:

在统一的超参数下,各模型的词向量类比能力的结果如图:
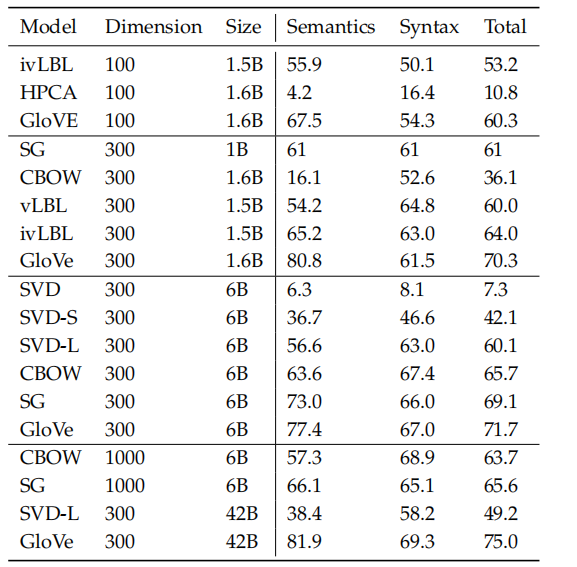
2.3 内部评估例子:相关性评估
另一种简单的方法可以用来评估词向量:让人们来为两个词的相似度打分(0-10分),然后计算这两个词的向量之间的余弦相似度,来进行对比。
如下图,就是在不同的数据集下,通过如上方法,对模型的评估结果如图:
