视频地址:https://www.bilibili.com/video/av41393758/?p=10 课程主页地址:http://web.stanford.edu/class/cs224n/ 课程讲义下载地址:https://yunlongs-1253041399.cos.ap-chengdu.myqcloud.com/Books/CS224n/cs224n-2019-notes06-NMT_seq2seq_attention.pdf
1.Neural Machine Translation with Seq2Seq
神经网络在机器翻译方面的应用,这一部分还是直接看吴恩达的笔记即可 序列模型和注意力机制(Sequence models & Attention mechanism) 以上链接总共涉及了以下知识点:
- 条件语言模型
- greedy search
- Beam search
- 改进Beam search
- Beam search的误差分析
- Bleu得分
- 注意力模型
剩下将补充cs224n里其他的知识点,和注意力模型。
2.Attention Model
2.1 注意力模型的动机
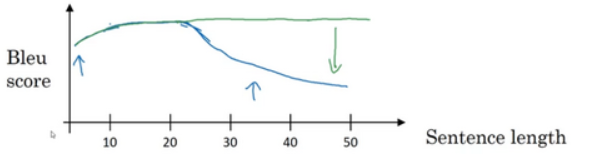 动机: 当句子越来越长时,神经网络将整个句子记忆下来的能力会越来越差。而注意力模型翻译得很像人类,一次翻译句子的一部分。且机器翻译系统只会翻译句子的一部分,不会有上图中一个巨大的下倾(huge dip)。
动机: 当句子越来越长时,神经网络将整个句子记忆下来的能力会越来越差。而注意力模型翻译得很像人类,一次翻译句子的一部分。且机器翻译系统只会翻译句子的一部分,不会有上图中一个巨大的下倾(huge dip)。
2.2 网络结构
这里我们只将到$S^{\lt 2 \gt}$涉及的网络层次进行了展开,其余的类似。

2.3 注意力机制
下面我们将注意力模型的网络结构,从下往上进行详细的阐述。
用$a^{\lt t^{\prime} \gt}$表示时间步上的特征向量。由于是双向RNN,对于每个$a^{\lt t^{\prime} \gt}$:
\[a^{\lt t^{\prime} \gt}=\left(a^{\rightarrow\lt t^{\prime} \gt}, a^{\leftarrow\lt t^{\prime} \gt}\right) \tag{1}\](2) 使用上一步的隐藏层状态$ S^{\lt t-1 \gt} $ 和每一步的激活值$a^{\lt t^{\prime} \gt}$,建立一个简单的神经网络,利用反向传播算法、梯度下降算法迭代优化,来求出$e^{\lt {t, t’} \gt}$:
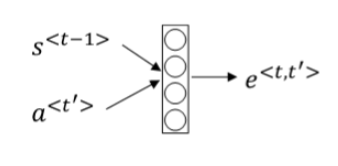
注意力权重用$\alpha$表示,之后再利用一softmax层,来计算出每一激活值$a^{\lt t^{\prime} \gt}$的权重,决定了此激活值$a^{\lt t^{\prime} \gt}$对当前的隐藏层状态$S^{\lt t \gt}$能产生多少影响:
\[\alpha^{\lt t, t^{\prime} \gt}=\frac{\exp \left(e^{\lt t, t^{\prime} \gt}\right)}{\sum_{t^{\prime}=1}^{T_{x}} \exp \left(e^{\lt t, t^{\prime} \gt}\right)} \tag {3}\]C是各个RNN神经元经过注意力权重得到的参数值。 将每一步的激活值$a^{\lt t^{\prime} \gt}$乘以其相应的权重$\alpha^{\lt t, t^{\prime} \gt}$,再进行累加得到最后隐藏层的输入C:
\[C^{\lt 1 \gt}=\sum_{t^{\prime}} \alpha^{\lt 1, t^{\prime} \gt} \cdot a^{\lt t^{\prime} \gt}\tag{4}\]2.4 注意力模型的表现
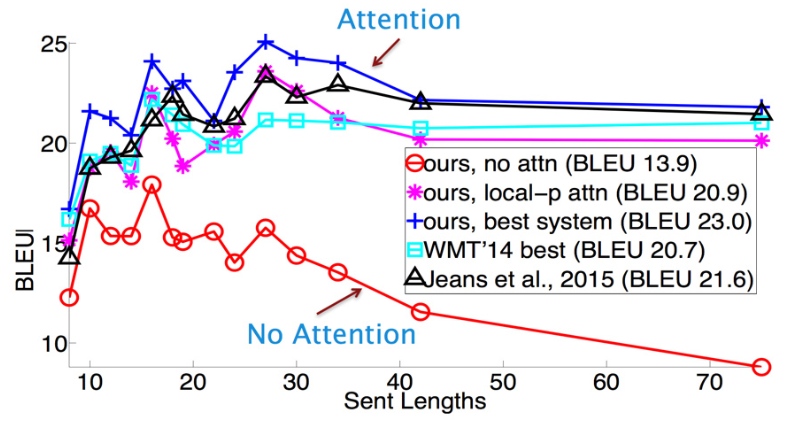
句子特短的时候,模型们的得分都不高。这纯粹是因为语料中的短句子本来就语义隐晦,比如某个专有名词作为标题。而有attention的模型在句子很长的时候,效果依然没有下降,说明了attention的重要性。