请咨询作者同意后转载。
BinGo: Cross-Architecture Cross-OS Binary Search
| 期刊/会议: | ESEC/FSE ’16 (A类) |
|---|---|
| 发表时间: | 2016年 |
| 发表机构: | 南洋理工 |
1. 方法概述
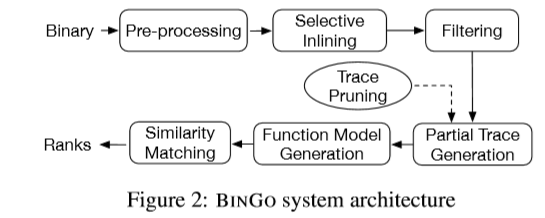 BinGo方法依次经过如下三个模块,从而寻找出Query function的匹配结果:
BinGo方法依次经过如下三个模块,从而寻找出Query function的匹配结果:
-
选择性内联: 在经过反汇编得到的汇编代码中,其中的函数调用具有丰富的语义信息,表示着这个函数调用能够实现什么样的功能。因此,选择内联技术将那些具有丰富语义的函数调用内联到函数中,从而完善函数的语义信息。
-
过滤:为了能够处理在真实世界中数量巨多的二进制,一个高效的过滤过程能够在进行昂贵的匹配步骤之前移除掉不相关的目标函数。在BinGo中分别实现了三个过滤器来进行逐步的过滤。
-
部分路径生成:之前用于检测函数语义等价性的使用定理证明器,但是使用定理证明器直接对函数代码进行判别等价性的代价是十分昂贵的,因此这里作者从CFG中提取一定长度的路径,给定相同输入的情况下,使用定理证明器来输出这些路径的执行结果,相对代价会小很多。
Bingo算法的工作流程,完整的叙述如下:
- 首先,给定一个query function,BINGO将对这个二进制进行预处理(ie.反汇编,提取CFG)来进行之后的分析。
- 下一步,识别target binaries中库函数和其他的用户定义函数,对部分库函数和其中具有丰富语义的用户函数进行内联。
- 使用三个filters来shortlist出那些与query functon函数相似的函数,作为candidate functions。
- 从query funciton 和candidate functions中生成长度不同的部分路径。
- 在部分路径生成阶段,通过trace pruning来移除一些不相关或者不可行的路径。
- 对这些部分路径进行group来形成function models。
- 从这些function models中提取语义特征
- 这些语义特征用来语义相似性匹配,计算相似性分数。
2.选择性内联
为了能够内联相关的函数,作者使用函数的调用模式来引导内联的决策。如图3所示,是作者总结的6种函数调用模式。

Case1: 图3(a)描述了对标准C库函数的直接调用情况。为了能够恢复出程序的语义信息,理解这些被调用库的语义是非常重要的,但目前我们只内联libc和msvcrt库。
Case2: 图3(b)展示了调用者函数和被调用函数f之间递归调用的情况,这里我们只内联f一次。
Case3: 图3(c)展示了一个功能函数的通用模式,被调用的函数f被其他的用户函数调用,且调用一些库函数,这样的函数f成为通用功能函数。所以f也很可能被内联。
Case4: 图3(d)是Case3的一个变体,被调用的函数f有许多对库函数的引用,但是没有对用户函数的引用。这样的函数可能具有很多语义,但是注意当函数f调用的库函数50%以上不是终止函数(exit,abort)时才被内联。
Case5: 图3(e)中的被调用的函数f只有很少的对库函数的引用,然而所有调用的库函数都是终止函数,这样的函数我们认为是加速程序的终止,具有很少的语义信息,所以不需要内联。
Csae6: 图3(f)中,函数f调用了很多的用户函数和库函数,似乎只其了调度函数的作用,因此这样的函数并没有太对独特的语义,不需要内联。
2.2 内联决策算法
在图3(a,b,d,e)中的场景都有明确的标准来决定函数f是否内联,但是对于图3(c,f)的场景,我们让然需要一种系统的决策过程。为此,作者引入了函数耦合的概念,我们可以通过计算function coupling score来度量函数的耦合程度:
Definition : Funtion Coupling Score可以用来判断一个函数中设计的函数调用的复杂程度,其可以通过$\alpha = \lambda_e / (\lambda_e + \lambda_a)$来计算。
其中$\lambda_a$表示调用函数f的用户函数的数量,$\lambda_e$表示被函数f调用的用户函数的数量。 当$\alpha$的值越低时,函数f就越应该被内联,这是因为低函数耦合分数意味着高的函数独立性。
作者提出的内联选择算法的形式化描述如算法1所示:

3. 函数过滤器
为了能够处理在真实世界中数量巨多的二进制,一个高效的过滤过程能够在进行昂贵的匹配步骤之前移除掉不相关的目标函数。
Filter1: 如果target 函数中与query函数有相同的库函数调用,那么target函数就为候选函数,这是因为库函数通常能够提供函数丰富的语义信息。但是此filter依赖于OS且不能支持具有相同语义功能但不同名字的函数(memcpy,memmove)
Filter 2: 为了解决上面的库函数调用问题,作者考虑在库函数调用更好层次来进行匹配,即库函数调用操作类型。如图4所示,将每个具体的库函数归纳到level 1进行匹配。并且filter2是与OS无关的,虽然相同功能的函数在不同的OS下可能具有不同的名字,但是都可以映射到相同的操作类型。
 但是库函数调用可以被编译器内联或者由编程者实现在相同功能的用户函数中。
但是库函数调用可以被编译器内联或者由编程者实现在相同功能的用户函数中。
Filter 3: 这第三个filter被设计来捕捉指令类型的相似性信息。每一个指令类型都对应着该指令所进行的高级别操作。因此,作者将指令分类为14和8类 ,分别在Intel和ARM架构下。并且filter3与架构无关。
将如上三个Filter组合在一起的算法如下所示:

4. SCALABLE 函数匹配
4.1 长度不同部分路径提取
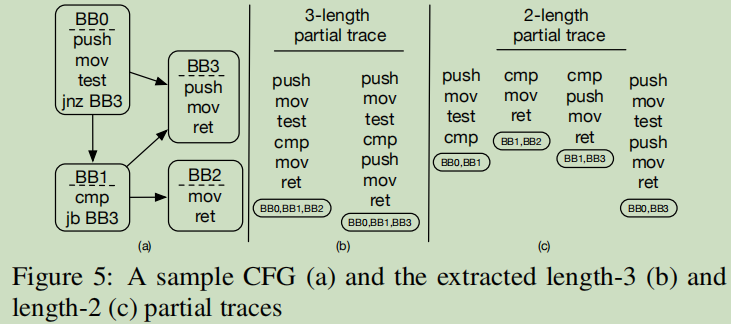
简而言之,就是CFG中几个连续可达的基本快,并且忽略的跳转指令。如图5所示,时从CFG中提取的长度为2和3的部分路径:
4.2 语义特征提取
我们可以从之前提取的部分路径中提取出一系列符号表达式的集合,这里定义执行前的机器状态为$\mathcal{X} = <men,reg,flag >$,称之为post-state;执行后的机器状态为$\mathcal{X’} = <mem’,reg’,flag’>$。
为了度量两个函数之间的相似性,我们可以直接使用约束求解器,比如Z3.可以用Z3约束求解器来计算不同符号表达式之间的语义等价性,但是计算代价太昂贵。
所以为了解决scalable的问题,作者使用了一种基于机器学习的方法。具体如下:从符号表达式中随机生成输入/输出样本,并且使用机器学习方法来寻找语义相似性。其中而I/O样本的生成是通过赋予pre-state变量具体的值,输出表达式中对应的post-state变量的值。
但是随机生成I/O样本有个缺点,就是符号表达式之间的依赖关系被忽略了。比如下面从一个路径中提取出的两个表达式:
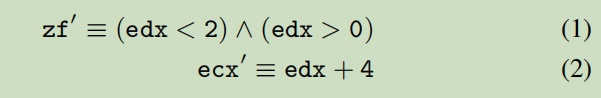
公式(1)和(2)都有相同的pre-state变量:edx。所以,这两个等式都相互依赖于一个公共变量,但是对于这两个等式edx可能被分配为两个不同的值。
所以这里就需要使用Z3约束求解器来生成I/O样本,注意,使用Z3生成I/O样本的速度会比Z3证明等式等价性快的多。
4.3 路径修剪
4.3.1 不可行路径的修剪
使用约束求解器,我们不再需要额外的功夫来识别不可行的路径,因为如果约束求解器不能为pre-和post-state变量需找到合适的值,那么与这相关的路径就被认为是不可行的。
但是因为全局变量、堆中的数据、动态数据等影响,在实际的运行中发现很多约束求解器生成的I/Opair也是不可达的,但是怎么将这些不可行路径移除是一个很难的问题。
编译器指定代码的修剪
有些编译器选项引入的额外的代码会引入额外的噪声,但是如果从parial trace中直接移除一些代码可能导致trace不正确的语义信息。所以,作者提出了一种保守的方法来解决这个问题通过泛化编译器生成代码到一些模式中,并将那些包含此模式50%以上的partial trace给移除掉。
4.4 函数匹配
在BINGO中,走i这利用长度不同部分路径来给函数建模,首先为每个函数生成长三个不同长度的路径(eg,k=1,2,3),如下所示:
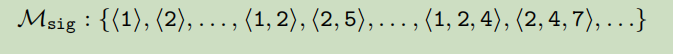
然后,根据query fucntion 和target function之间的n-to-m, 1-to-n, n-to-1 and 1-to-1部分路径匹配来进行函数模型的相似性匹配,以此来减轻程序结构差异带来的影响。
1-n匹配解决基本快切分的问题:query函数中的一个基本快被切分到目标函数中的多个基本快。n-1则相反。
最后,将这个函数模型考虑为部分路径的bag,我们可以使用Jaccard相似性系数来度量两个不同函数模型之间的相似度:
