BinMatch:A Semantics-based Hybrid Approach onBinary Code Clone Analysis
| 期刊/会议: | ICSME (B类) |
|---|---|
| 发表时间: | 2018年 |
| 发表机构: | 上交 |
一.前言
首先作者分析了,在二进制代码相似性检测这个问题上,动态方法和静态方法各自的优缺点:
- 动态方法能够从代码执行中获得丰富的语义,来确保搞得精准性,但是其之分析了执行的代码,具有很低的覆盖率。
- 静态方法能够覆盖所有的程序片段,但是其更依赖于语法和结构特征,缺少语义。另外,静态方法不能够决定函数调用和间接跳转的目标,具有相对较低的准确率。
为此作者开展了动静混合的二进制代码相似性检测工作。
二.System Overview
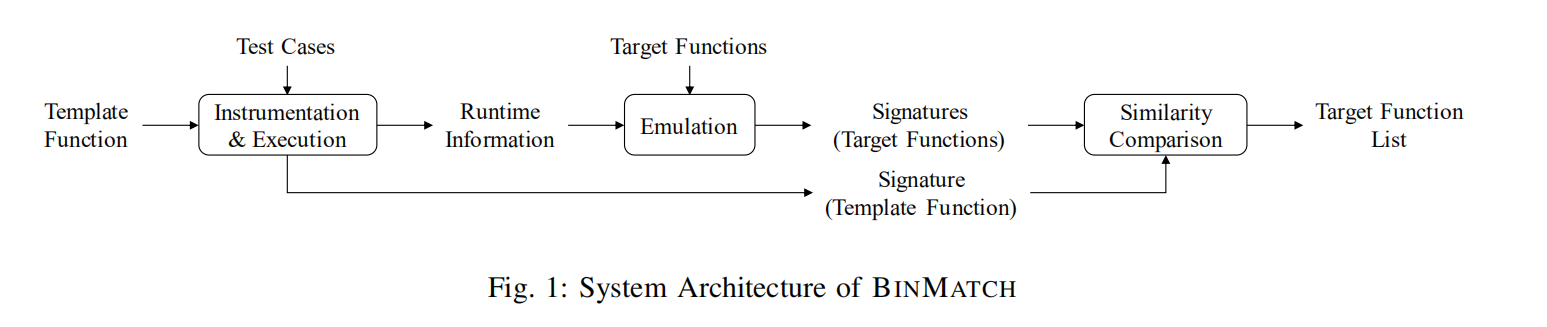 图1展示了BINMATCH的工作流程:
图1展示了BINMATCH的工作流程:
- 首先,给定一个我们分析理解的template函数,BinMatch会使用指令插桩技术并和测试程序一起执行它,来捕捉其语义指纹。与此同时,在执行中的运行信息会被记录。
- 然后,BinMatch会将这些运行中的信息迁移到每个目标函数中,来仿真目标函数的执行,并确保目标函数的执行环境与template函数的执行环境一直,提取其语义指纹。
- 最后,BinMatch拿template函数的指纹与每个目标函数的指纹进行比较,来计算相似性。
三.方法介绍
在这一部分主要介绍我们要引入哪些特征作为语义指纹,然后再讨论如何捕捉这些指纹信息。
A.Semantice Signatures
对于每个二进制函数,BinMatch将捕捉每个函数运行时的行为作为其指纹。 给定特定的输入,指纹指示函数如何处理输入并生成输出,这反映了该函数的语义。
BinMatch的指纹由如下特征组成:
- Read and Written Values: 该特征由在执行过程中从内存中读取或写入内存的全局(或静态)变量值组成。当给定一个确切的输入时,这就包含了这个函数的输入和输出值,以此来表示这个函数的语义。
- Comparison Operand Values: 这个特征由比较操作的值组成,因为比较惭怍一般决定了一个输入下的控制流路线,所以这个特征语义相关性也很高的。
- Invoked Standard Library Functions: 标准库函数的调用已经证明了时非常有效且语义相关的。
B.Instrumentation and Execution(指令插桩和执行)
算法1展示了作者对指令插桩的伪代码。
BinMatch将会遍历每个指令$\mathcal{I}$,算法1的第4-9行,如果$\mathcal{I}$访问了全局变量、比较操作、标准库函数调用,那么BinMatch就再I前面个注入代码来捕捉特征和生成指纹。
第11-16行 表示的时记录程序在运行时的一些值。比如在第11-12行,如果$\mathcal{I}$从函数调用前压栈的值中读取了一个变量,那么就可以认为读取的值就是函数的参数,记录下来。
其中第13-14行,记录下函数F间接调用的函数的地址。
第15-16行,记录下所有调用函数的返回值。

C.Emulation
在这一步,BinMatch将会使用template函数F在运行时的信息,并迁移到需要比较的目标函数T中去,以此来确保函数T在执行时的状态和输入与函数F时相同的,这样的话,如果这两个函数时相似的,那么其在运行时的行为也应当是相似的。
仿真流程的伪代码如算法2所示。

1.函数参数的分配
根据函数的调用约定(压栈和入栈),BinMatch能够识别出目标函数T的参数,如果T的参数个数和template函数的参数个数一致,那么BinMatch就顺序的为T分配之前F的参数。否则,BinMatch将会跳过T的仿真,因为T不可能与F匹配上。
下面举了个例子,例如F和T拥有下面的参数列表:
 如果F在执行过程中值访问了其中的两个参数,farg_0和farg_2,在之前的指纹提取的阶段BinMatch就已经保存了这两个参数的值。然后BinMatch会将这两个值分别分配给targ_0和targ_2,而参数targ_1就会被分配一个预定义的值(比如, 0xDEADBEEF)
如果F在执行过程中值访问了其中的两个参数,farg_0和farg_2,在之前的指纹提取的阶段BinMatch就已经保存了这两个参数的值。然后BinMatch会将这两个值分别分配给targ_0和targ_2,而参数targ_1就会被分配一个预定义的值(比如, 0xDEADBEEF)
2.全局变量读
在函数F执行的过程中,其读取的全局变量的值很有可能时已经被之前的函数修改过的,所以为了能够在函数F的内存空间的布局下来仿真目标函数T,因此BinMatch需要考虑如下两点:
- 获得T读取的全局变量的地址。
- 将函数F中对应的全局变量的值写入T对应的全局变量的地址中去。
而全局变量的位置是存储在二进制程序的特定段上(比如.data),而且程序中全局变量的位置,包括全局数据结构(eg.array)的基址都是在程序编译后决定好的,并且不会再发生变化。因此,全局变量就可以通过硬编码的方式来进行访问。而访问全局结构内某一个成员时候的偏移,也是由函数的输入决定的。
所以,BinMatch可以轻松的获得全局变量的值和仿真时T中的全局变量的地址。 并且BinMatch是根据全局变量的使用顺序来进行迁移的。
3.间接调用或跳转
因为目标函数T已经使用了template函数F的内存空间来进行仿真,所以T所间接调用的函数地址应当和F中调用这个函数的地址一样,然后再将此函数的返回值迁移给T。否则在仿真环境下的目标函数T就不可能与F匹配。
间接跳转或者分支是被实现在了可执行文件中的.rodata段中的jump table中的,里面包含了顺序的目标地址的列表。
比如在图3中所展示的就是switch结构的间接跳转的一个例子。当index的值小于0x2A的时候,就会执行默认的case,然后就有一个间接跳转,并且可以看出jump table的基址为0x808F630,还有程序确定的偏移。

4.标准库函数的调用
如果目标函数T调用了一个标准库函数来请求系统资源的支持,比如malloc,那么BinMath就会掉过对此库函数的仿真,并且将F所调用的对应函数的返回值分配给它。
D.Similarity Comparison
LCS算法不仅考虑比较的两个序列的元素顺序,而且还允许跳过那些非匹配的元素。对代码优化和混淆具有一定的容忍性。所以作者采用Longest Common Subsequence算法来评价特征间的相似性。
计算公式如下:
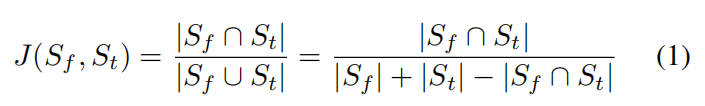 其中$|S_f|$和$|S_t|$分别为各自的长度,$|S_f \hat{S_t}|$为这两个序列的LCS长度。
其中$|S_f|$和$|S_t|$分别为各自的长度,$|S_f \hat{S_t}|$为这两个序列的LCS长度。
四.实现
A.Binary Function Boundary Identification
可以用IDA的插件来获得指定函数的起始地址和终止地址。
B.Instrumentation and Emulation
使用Valgrind实现了BinMatch的指令插桩模块,Valgrind会同意二进制代码到VEX-IR的形式,并且向IR代码中注入指令代码,然后将IR代码转化成二进制代码来执行。
仿真阶段的实现 是基于angr的,angr是一个二进制分析框架,其从Valgrind中获得VEX-IR,并静态的将二进制代码转化成需要被分析的IR。
其提供了一个叫做SimProcedure的模块来仿真IR code的执行,还允许指令插桩。并且自身还维护有一个标准库函数的数据库,减轻了仿真的压力。
C.Similarity Comparison
采用Hirschberg’s Algorithm来计算LCS,只需要$O(min(m,n))$的空间复杂度。
实验评估
数据集
 图中的这些各种类型的开源软件,然后clang、gcc,O0-O1编译。
图中的这些各种类型的开源软件,然后clang、gcc,O0-O1编译。
准确率评估
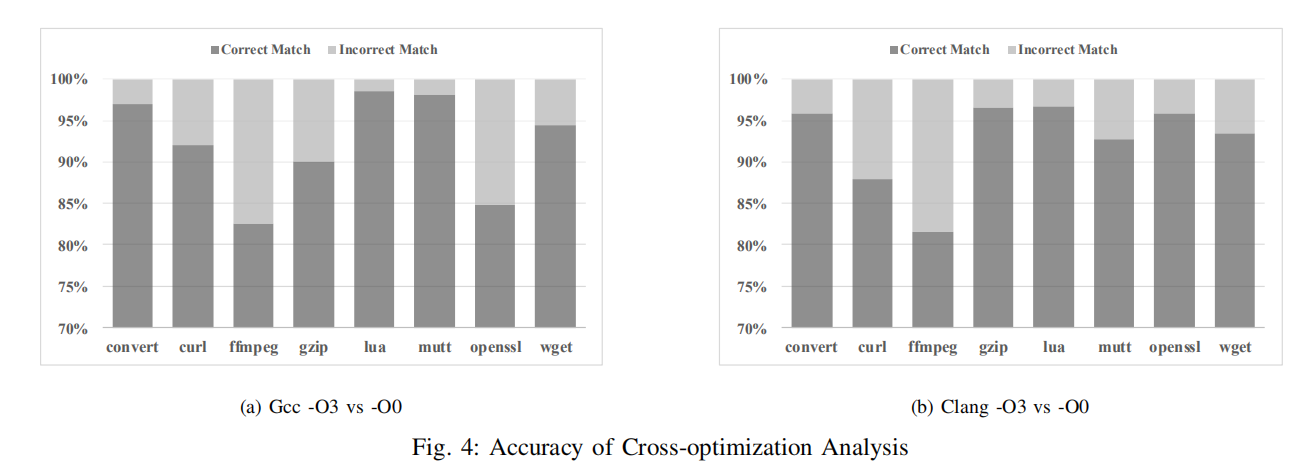
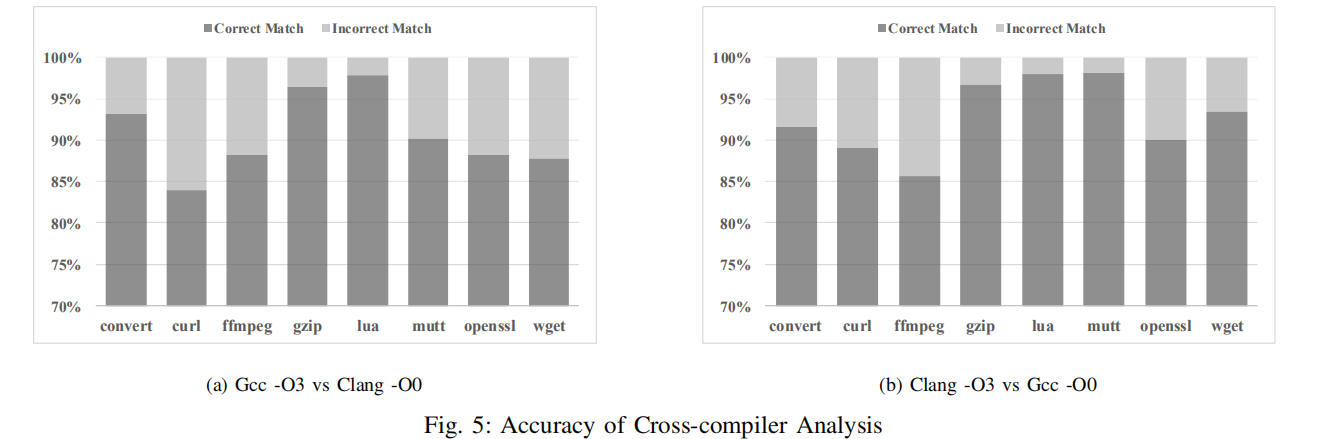
下图4和图5分别展示了跨优化选项和跨编译器下的表现,基本都达到了85%以上。
然后是与其他方法的横向对比:
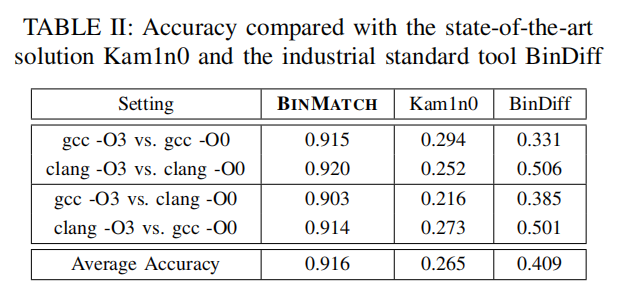
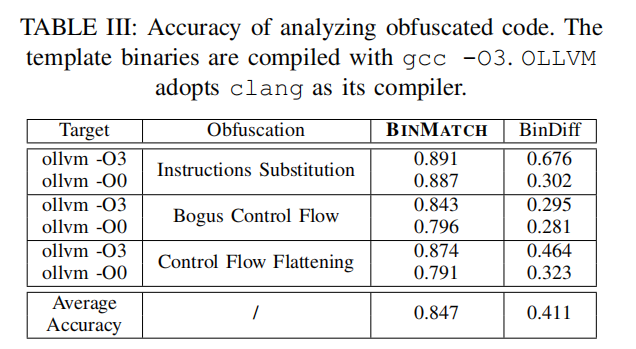
甚至在加了混淆的情况下,也能够有很高的准确率。
效率
动态分析带来的短板就是效率太低了,而且LCS更加耗费时间。
仿真一个函数的运行需要4.3秒,而因为LCS的高时间复杂度,一对函数的相似性比较花费573.9秒。