Binary Similarity Detection Using Machine Learning
| 期刊/会议: | CCS PLAS’18 session |
|---|---|
| 发表时间: | 2018年12月19 |
| 发表机构: | Cornell Tech & Tel-Aviv, Israel |
基于 similarity by composition的思想,这篇论文采用了代码分解的技术(strands)来生成特征向量,并使用机器学习方法来快速的进行二进制匹配。
ZEEK 方法
strands as feature
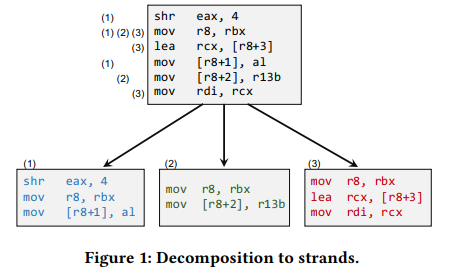 像上图,首先提取出给定代码片段的strands。
像上图,首先提取出给定代码片段的strands。
然后根据Similarity by composition的启发,这次工作中,作者希望能够使用strands来合成一个代码段作为其特征集合。作者将strands转化为数字,并将这些数字汇集起来形成一个特征向量来表示对应的代码段,为了能够学习代码块(strands)的共现和频繁性,作者训练了一个机器学习模型。因此那些包含稀有的strands或者少见的strands的组合时,就会很可能被认为是更独特的,并拥有更高的相似性分数。那些常见的strands就与相似性无关。
Prov2Vec model
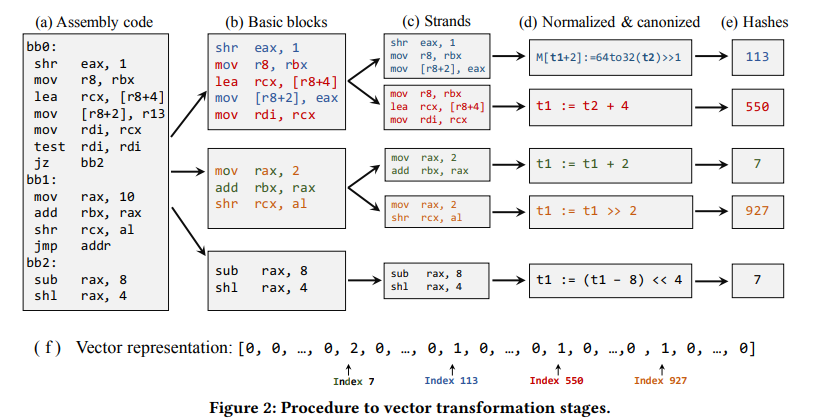 如图2所示,将以代码段转化为特征向量分为以下的五个步骤:
如图2所示,将以代码段转化为特征向量分为以下的五个步骤:
- 根据跳转指令将程序划分为基本块
- 分解每个基本块到strands
- 将语法不同但是语义相同的strands转化成相同的IR表示。(这里利用的是GitZ中的re-Optimizion技术)
- 应用b-bit的MD5哈希方法对strands生成hash值,这样的话每个strand就被映射到了$\lbrace 0,2^b-1 \rbrace$范围内的一个整数。
- 如图2f所示,使用此代码段中所有strands的映射整数集合来建立此代码段的特征向量,其中向量的长度为$2^b$,并使用整数集合中的每个整数来作为索引。这就相当于,特征向量中的每个元素就等价于映射到这个位置上的strand的个数。
在算法的实现方法上,作者使用PyVEX开源库来将二进制代码转化成VEX-IR和切片。
数据集生成
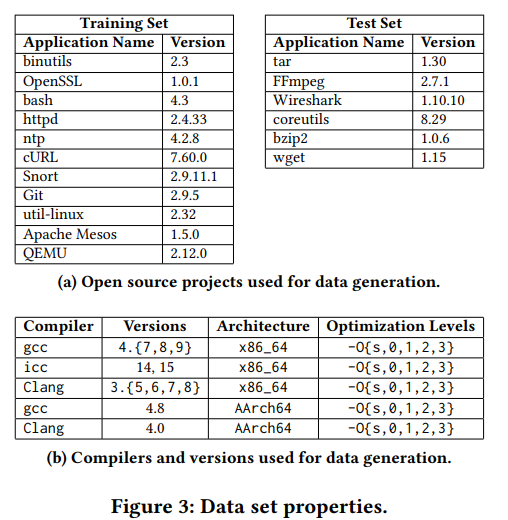
使用的数据集如下图所示。
作者通过堆叠数据集中的所有特征向量可以得到一个矩阵$M$。 并根据对数据集的先验知识建立了一个match-list,match-list中的每一对都表示再矩阵$M$中所匹配的索引行。例如, 如果对$(i,j)$出现在匹配列表中,则相应的向量$M_i$(M的第i行)和$M_j$来自同一程序的源代码。
为了能够让分类器学习到程序与自身的相似性,和输入顺序的不重要性,作者对每个匹配对(x,y)数据进行了增强,(x,y), (x, x), (y,y), (y, x),并标准为正样本。
因为相似性的代码段数据集相对来说是比较少的,因此作者从以下两个方面来解决: (1)使用CROC指标,为评估不平衡的分类问题而设计的。 (2)作者生成了一个十分不平衡的数据集,并测试正样本和负样本之间的比率。
最后作者生成了2千万规模的数据集。
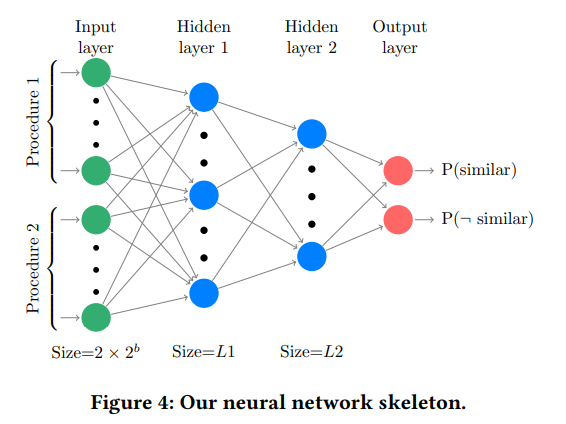
NN分类器
给个图就完事。