Similarity Metric Method for Binary Basic Blocks of Cross-Instruction Set Architecture
https://github.com/zhangxiaochuan/MIRROR
| 期刊/会议: | NDSS20 BAR workshop |
|---|---|
| 发表时间: | 2020年 |
| 发表机构: | National Innovation Institute of Defense Technology, China,… |
一、前言
本文提出了一种新的跨机构基本块比较的方法,其采用基于Transformer的NMT模型和新的指令标准化方法来进行跨架构基本块之间的相似性比较。
在此之前,能进行跨架构基本块比较的方法有INNEREYE-BB,但是其标准化方法存在着一些问题。 作者指出,在采用RNN这种架构的神经网络时,需要输入前一隐状态,但是经过统计发现,大多数基本块的结尾是以跳转其他基本块标签或函数名结束。
\[h_{t}, c_{t}=F_{L S T M}\left(s_{t}, h_{t-1}, c_{t-1}\right)\]但是再INNEREYE中的标准化步骤将所有的函数名和基本块标签名给用统一的符号代替,这样就使得在计算最后的输出时,输入的$s_n$是一样的。
二、跨架构基本块Embedding解决方案
在这一部分,作者提出了一种方案来试图将不同架构指令集下的基本块映射到相同的嵌入空间中,首先作者提出了一个理想化的模型,然后基于实际情况及理想化模型实现的困难性提出了一个实际的模型。
理想化模型:
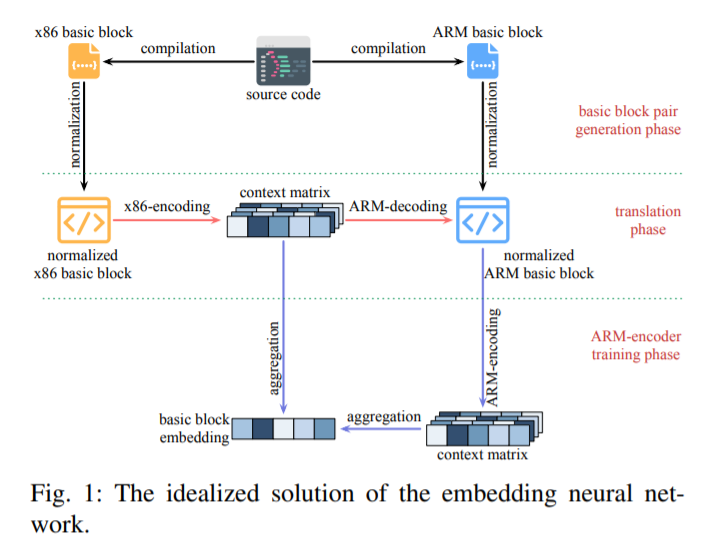 理想化模型的流程图如图1所示,作者为了能够将x86和ARM的基本块映射到相同的嵌入空间中,作者假设NMT模型能够非常完美的将x86的基本块转化成ARM的基本块。这就意味着生成的嵌入矩阵包含x86和ARM基本块中完整的语义信息。
理想化模型的流程图如图1所示,作者为了能够将x86和ARM的基本块映射到相同的嵌入空间中,作者假设NMT模型能够非常完美的将x86的基本块转化成ARM的基本块。这就意味着生成的嵌入矩阵包含x86和ARM基本块中完整的语义信息。
那么我们对于一对语义等价的跨架构基本块,首先使用x86-encoder(Transformer encoder)得到x86基本块的上下文矩阵$C=\lbrace c_i \rbrace \in R^{d \times n}$,其中$d$为embedding大小,$n$为此基本块的长度。我们再使用ARM-decoder(Transformer decoder)的话,就可以得到相同的ARM基本块,再使用ARM-encoder生成ARM的上下文矩阵。
对上下文矩阵进行求和,就可以得到这个基本块的embedding $E$,根据此embedding就可以完美的计算跨架构指令集基本块之间的相似性。 \(E = \sum_{i=1}^n c_i\)
但是如此严格的假设是明显不成立的,因为经过x86-encoder生成的上下文矩阵不可能完美的翻译成对应的ARM基本块,所以作者相应的做了些改变提出了一种更实际化的方案。
实际化模型:
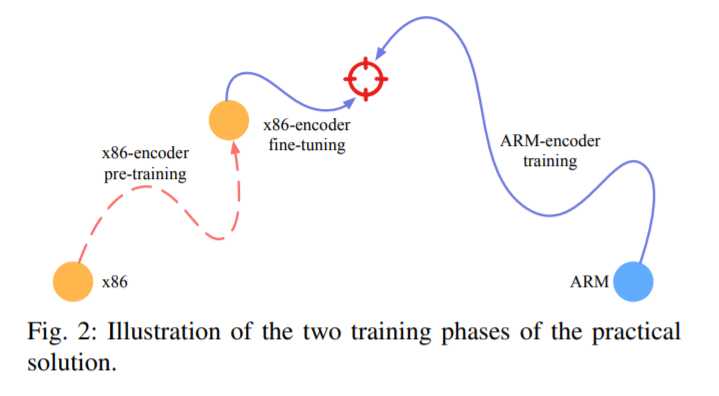 如图2所示,实际化模型分为了两个阶段:
如图2所示,实际化模型分为了两个阶段:
- 第一个阶段:使用理想化模型中x86-ARM的NMT模型进行预训练。
- 第二个阶段:两个新的encoder,其中x86-encoder是建立再x86-pretraining得基础之上,一个新的ARM-encoder(因为在理性化模型中,在x86-ARM得转化阶段假设就已经不成立,所以其后面得ARM-encoder就不能再使用)。然后这两个encoder分别对x86和ARM的基本块生成embedding,计算其相似度。
2.1 Basic Block Pair Generation
对于如何对两个由相同源码编译得到的不同指令集下的基本块加标签的方法,采用的是INEEREYE-BB中用LLVM加标签的方法。
本文中的标准化方法:
- 对于常量:划分到5类:中间值、地址、变量名、函数名、基本块标签。
- 对于x86寄存器:划分到14类:指针寄存器、浮点数寄存器、4类通用寄存器、4类数据寄存器、4类地址寄存器。其中的每一小类是根据所存储的数据长度来划分:8、16、32、64位。
- 对于ARM寄存器:划分为两类:通用寄存器和指针寄存器。
2.2 x86-encoder Pre-train
这个任务需要做的是根据输入的x86基本块,将其反映称语义相近的ARM基本块。
形式化定义如下:输入的x86基本块$S = (s_1,…,s_n)$,在decoder阶段输出的ARM基本块$T = (t_1,…,t_{k-1})$,在当前时间步需要预测下一个词条$t_k$,NMT模型输出的其实是在当前步每个词条出现的概率$y_k \in R^{|V_{ARM}|}$.
损失为交叉熵损失,定义如下:
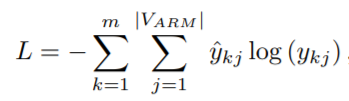
其中$\hat y_k \in R^{|V_{ARM}|}$是$t_k$的one-hot编码。
2.3 负采样算法
作者采用Triplet来生成训练样本,即三元组(Anchor,Positive,Negative)。并且引入hard Negative来提高模型的性能。
Hard Negative的样本生成是需要使用x86-pretrain-encoder来进行生成:
这里我们注意这个预训练的NMT模型,虽然其只是x86基本块encoding的半成品,但是其已经能够进行初步的判别两个x86的基本块是否相似。
- 如果anchor为ARM基本块,那么负样本就直接选择对应的x86基本块
- 如果anchor为x86基本块,那么负样本选择就选择对应x86基本块语义等价的ARM基本块。
随机负样本和hard 负样本之间的比率为2:1。
2.4 嵌入网络训练
这整个采用的网络架构其实就是Siamese网络架构,因为输入的训练样本为Triplet,所以选择的对应的损失函数也为Triplet损失: \(L=\max \left\{\mathrm{D}\left(E_{1}, E_{2}\right)-\mathrm{D}\left(E_{1}, E_{3}\right)+\gamma, 0\right\}\) 其中$D( ,)$为欧几里得距离。
2.5 相似性评估标准
因为欧几里得距离的取值范围为$0->+ \infty$,但是我们需要的基本块之间的相似性范围为$0->1$。 所以,做了如下的映射: \(\operatorname{sim}\left(B_{1}, B_{2}\right)=\exp \left(-\frac{\mathrm{D}\left(E_{1}, E_{2}\right)}{d}\right)\) 其中$d$为embedding的维度。
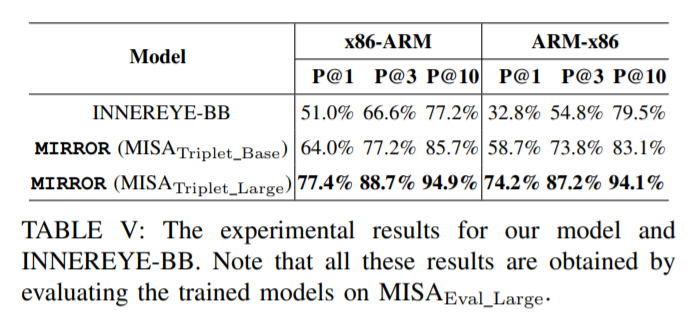
三、实验评估