RTFM! Automatic Assumption Discovery and Verification Derivation from Library Document for API Misuse Detection
作者:Tao Lv, Ruishi Li, Yi Yang, Kai Chen, Xiaojing Liao, XiaoFeng Wang, Peiwei Hu, Luyi Xing
单位: Chinese Academy of Sciences,Indiana University Bloomington
会议: CCS 2020
Abstract
在API开发者文档中,开发者通常需要遵从一些约束假设(Integration Assumptions, IA),若在开发过程中违背了这些约束假设,则会造成API的误用。为此,作者提出了一种基于NLP的方法,称为Advance,来从松散格式的文档中来发现这些IAs,并将这些IAs形式化描述来检测API误用。
Advance在5个库(OpenSSL,SQlite,libpcap,libdbus and libxml2)和39个应用软件中发现了193个API误用,其中有139个是没报告过的。
1. Introduction
先看一个根据API文档来发现API误用的例子:
图 (b)描述了在文档中对API函数 pcap_geterr() 的约束假设(IA),要求对其返回值的使用必须在close前进行;图(a)中第1080行调用了pcap_geterr(),第1087行 close了pc,但第1088行仍对返回值cp进行了使用。

若要完成对API文档的自动化分析和检测误用,需要克服如下几个挑战:
- 松散格式的API文档:项目间风格差异、不充足的描述信息。
- 文档中对API和参数的引用:如何将close映射到
pcap_close()。 - 约束条件满足性的判断:怎么分析文档中的信息流和数据流。
2. Advance:Design
2.1 Overview
三个关键组成部分:
- IA discovery: 根据API文档内容,发现其中存在的约束假设(IA)
- IA dereference: 将IA中涉及引用API函数名、参数名的部分解引用到对应的API函数
- VC generation: 根据约束条件,生成验证代码(Verification Code)

2.2 IA Discovery
目标: 从文档中提取约束假设(IA)
作者发现在文档中所有的IA都具有一个特点:表达出强烈的情感来强调约束条件,越重要的IA这种情感描述就会越强烈。
例子: “the application must finalize every prepared statement”; “make sure that you explicitly check for PCAP_ERROR”
Sentiment-based IA classifier: 为了从整个API文档的描述语句中表达强烈情感的IA语句,作者基于HAN[1]提出了S-HAN模型,来输入一个句子,生成这个句子的vector,然后进行情感分类。
S-HAN模型结构如图所示:
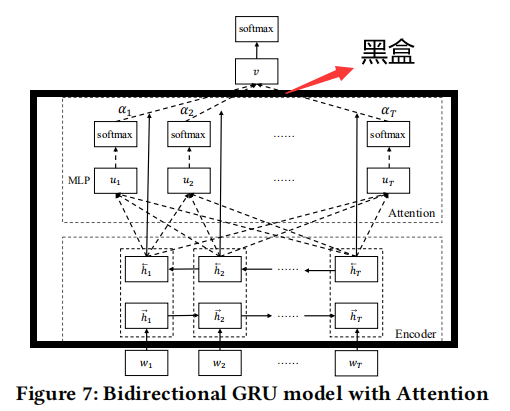
2.3 IA Dereference
目标: 寻找在约束假设(IA)中对API函数名和参数的隐式引用。
例子: 对于IA “The application must finalize every prepared statement”
“finalize every prepared statement”引用的是API sqlite3_finalize,“prepared statement”引用的是API sqlite3_prepare的第三个参数。
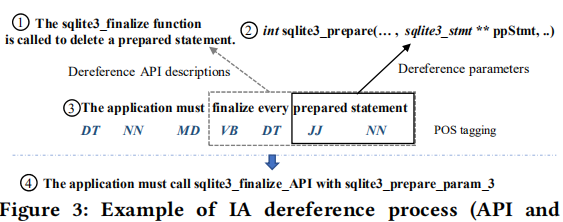
2.3.1 基于语义的API解引用
基于观察:文档中API的引用文本应当和描述API功能性的文本语义相似。这里描述API功能性的文本指的是在API文档中描述API的第一句话,也是作者发现第一句话具有表达API功能性的能力。
同时,作者表示描述API进行何种操作引用文本中通常都包含动词,所以IA中包含的动词信息可以帮助IA的解引用。
具体做法:
- 对IA中的单词进行词性标注
- 基于现有的语法规则,使用正则表达式寻找出动词短语
如图3所示,“finalize”为一个动词,“statement”为一个名词,结合起来的 “finalize every prepared statement”就是一个动词短语。
在得到IA中的动词短语之后,Advance将其转化成一个embedding 向量$S_1$来表征其语义;同样地,将描述API功能性的文本也转换成一个表征语义的embedding 向量$S_2$。因此,IA中的引用文本和API功能描述文本之间的相似度可计算为:
\[sim = \frac{S_1 ·S_2}{\|S_1\| \|S_2\|}\]通过寻找相似的API引用和描述文本对,我们就可以完成对IA中API函数的解引用。
2.3.2 参数解引用
通过观察,作者将IA中对参数的解引用文本总结为三种形式:
- 参数名的缩写
- 参数名的扩写
- 参数的类型
为了完成对IA中参数的解引用,作者将所有IA中出现的名词短语当成可能的参数引用文本,对所有API的参数使用正则表达式进行匹配。
个人理解:枚举所有的(参数引用文本,参数名)、(参数引用文本,参数类型)对,用正则匹配缩写或扩写。
2.4 Verification Code Generation
要将约束假设文本中的约束条件提取出来,比如数据流和控制流,并自动化的生成验证代码是一件很困难的事。
作者观察到,那些重要且对安全敏感的约束条件通常包含共同的组成部分。为此作者将这些共同的组成部分映射到单独的验证代码片段(VCS)中去。
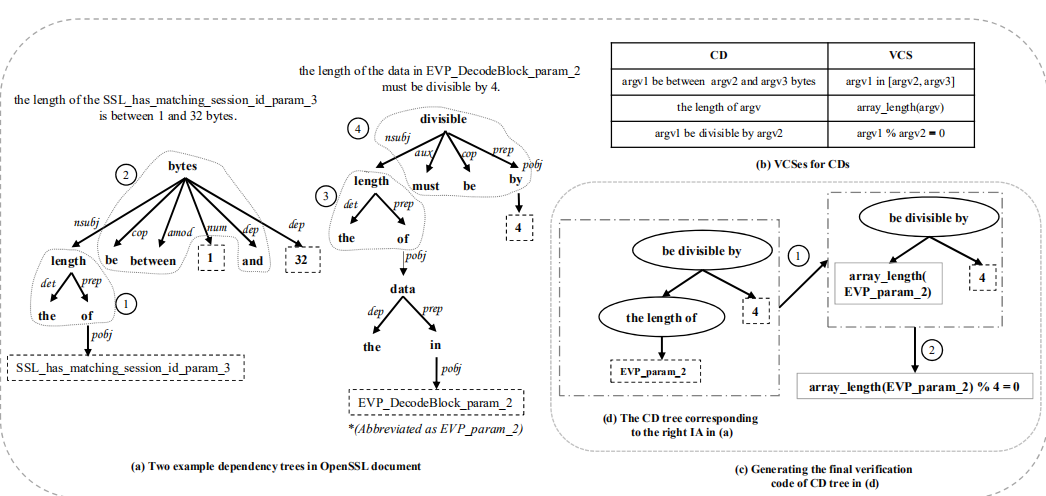
作者处理的流程如下图所示:
- 使用依赖分析将IA语句解析成语法树的形式。(图a)
- 使用频繁子树挖掘算法,寻到公共模式“the length of”。(图a)
- 手工将挖掘出的频繁子树映射到验证工具要用的验证代码片段(VCS),
array_lenth(argv)。(图b) - 将依赖树转化为代码描述树,然后转化验证工具所需的验证代码。(图c)
3. Evaluation
验证工具: CodeQL
实验设置: 先对整个Advance进行API误用检测实验,后对每个模块的准确率进行单独的验证。
3.1 Advance 端到端的API误用检测实验
对使用了库(OpenSSL, SQLite, libpcap, libdbus and libxml2)的39个应用软件进行了检测,Advance报告出了193个API误用,其中有139个是未公开过的,有54个是已经公开过的。但只有16个未公开的API误用被开发者确认。
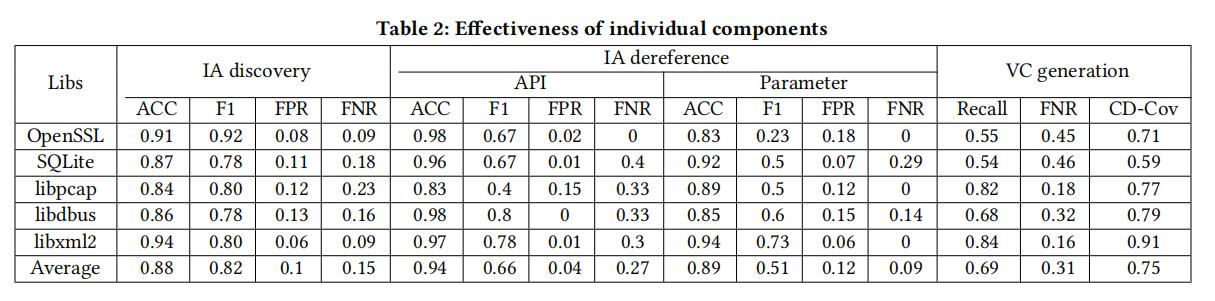
3.2 Advance 单个模块的准确率测试
4. Discussion
读论文中发现的一些疑惑:
- 首先HAN[1]的应用场景为document classification并不是sentence classification;
- 其次此论文发表在2020年,但是此前已经存在State-of-the-art的Sentence classification模型Sentence-BERT[2],所以设计S-HAN模型没有意义;
- 另外在Evaluation中说对比的是两个State-of-the-art的模型[3][4],但是这些都是2015年前的模型,完全不应当作为Comparision的对象。
参考文献
- [1] Hierarchical attention networks for document classification. In Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics
- [2] Sentence-BERT: Sentence embeddings using siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
- [3] Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882 (2014).
- [4] Recurrent convolutional neural networks for text classification.(2015). In Twenty-ninth AAAI conference on artificial intelligence.