
俗话说,学以致用,边学习理论知识边动手实践,能够对所学能容的掌握程度达到一个新的高度。在之前就购买了《WebAI三部曲》,考研完终于得以有时间学习,但是该书虽说是机器学习入门,但太过于偏向于实践,理论知识很少进行讲解,故在吴恩达老师的cs229n课程学习了一小段时间的机器学习理论知识,现在根据此书对所学知识进行应用是再好不过的了。
Lecture 1- 朴素贝叶斯算法
通常,企业和大型右键服务器提供商都会提供拦截垃圾邮件的功能,其中最常见的一种算法就是基于朴素贝叶斯的文本分类算法,答题思路就是通过学习大量的垃圾邮件和正常邮件样本,让朴素贝叶斯训练出文本分类模型。 贝叶斯分类是一系列分类算法的总称,这类算法均以贝叶斯定理为基础,故统称3为贝叶斯分类。其中朴素贝叶斯是其中应用最为广泛的分类算法之一。NB基于一个简单的假定:给定目标值时属性之间相互条件独立。NB算法有坚实的数学基础以及稳定的分类效率,同时所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。NB包括以下算法:
- 高斯朴素贝叶斯
- 多项式朴素贝叶斯
- 伯努利朴素贝叶斯
关于朴素贝叶斯算法的说明在笔记吴恩达Stanford机器学习公开课(五)笔记中有记录。
示例:hello world!朴素贝叶斯
首先就类似于一门语言中的hello world一样,能让其运作起来是最重要的,这里使用sklearn自带的iris鸢尾花数据集,让朴素贝叶斯算法先运作起来! 关于此数据集更多的描述在此http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
导入库遗迹数据集合:
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import GaussianNB
训练数据集:
gnb = GaussianNB()
验证结果:
y_pred = gnb.fit(iris.data,iris.target).predict(iris.data)
print("Number of mislabeled points out of a total %d points : %d"%(iris.data.shape[0],(iris.target!=y_pred).sum()))
运行结果如下:
Number of mislabeled points out of a total 150 points : 6
检测异常操作
1.数据搜集和数据清洗
在http://www.schonlau.net/ 网站中可以找到针对Linux系统操作的训练数据。
训练数据包括50个用户的操作日志,每个日志包含15000条操作命令,其中前5000 条都是正常操作,后面的10000条日志中随机包含有异常操作。为了便于分析,数据集每100条操作作为一个操作序列,同时进行了标注,每个操作序列只要有1条操作异常就认为这个操作序列异常。
每个文件内容如下:
2.特征化
读取数据集:依次读取每行操作命令,没100个命令组成一个操作序列,保存在列表里面:
with open(filename) as f:
i=0
x=[]
for line in f:
line=line.strip('\n')
x.append(line)
dist.append(line)
i+=1
if i == 100:
cmd_list.append(x)
x=[]
i=0
对统计得到的数据进行去重:
fdist = FreqDist(dist).keys()
下图是user3数据集全部操作指令去重后的结果:
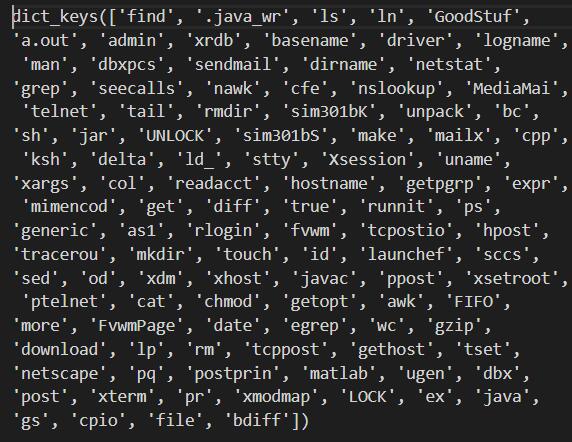
以该词汇表作为向量空间,将每个命令序列转换成对应的向量:
def get_user_cmd_feature_new(user_cmd_list,dist):
user_cmd_feature=[]
for cmd_list in user_cmd_list:
v=[0]*len(dist)
for i in range(0,len(dist)):
if dist[i] in cmd_list:
v[i]+=1
user_cmd_feature.append(v)
return user_cmd_feature
3.训练模型
使用NB训练:
clf = GaussianNB().fit(x_train, y_train)
4.验证效果
y_predict_nb=clf.predict(x_test)
score=np.mean(y_test==y_predict_nb)*100
print ("NB %d" % score)
最后的输出结果为:
NB 83
即准确率达到了83%。
该例子的全部代码如下:
# -*- coding:utf-8 -*-
import numpy as np
from nltk.probability import FreqDist
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
#测试样本数
N=90
def load_user_cmd_new(filename):
cmd_list=[]
dist=[]
with open(filename) as f:
i=0
x=[]
for line in f:
line=line.strip('\n')
x.append(line)
dist.append(line)
i+=1
if i == 100:
cmd_list.append(x)
x=[]
i=0
fdist = FreqDist(dist).keys()
print(fdist)
return cmd_list,fdist
def get_user_cmd_feature_new(user_cmd_list,dist):
user_cmd_feature=[]
for cmd_list in user_cmd_list:
v=[0]*len(dist)
for i in range(0,len(dist)):
if dist[i] in cmd_list:
v[i]+=1
user_cmd_feature.append(v)
return user_cmd_feature
def get_label(filename,index=0):
x=[]
with open(filename) as f:
for line in f:
line=line.strip('\n')
x.append( int(line.split()[index]))
return x
if __name__ == '__main__':
user_cmd_list,dist=load_user_cmd_new("Masquerading-data/User3")
user_cmd_feature=get_user_cmd_feature_new(user_cmd_list,dist)
labels=get_label("Masquerading-data/label.txt",2)
y=[0]*50+labels
x_train=user_cmd_feature[0:N]
y_train=y[0:N]
x_test=user_cmd_feature[N:150]
y_test=y[N:150]
clf = GaussianNB().fit(x_train, y_train)
y_predict_nb=clf.predict(x_test)
score=np.mean(y_test==y_predict_nb)*100
print ("NB %d" % score)