课程信息:感谢@袁源老师,贪心科技–“ 共同战疫” NLP系列专题 直播课,本文所有版权归贪心科技https://www.greedyai.com/所有。
Lecture 2 - Self-Attention与Transformer
1. 背景介绍
(1)之前模型的缺点:本质原因还是RNN体系的梯度消失/爆炸问题,尽管LSTM在一定程度上能缓解该问题,然而并未能完全避免。 (2)计算量的问题:因为时序模型必须是串行的,可能在预测阶段还能接受这个时效性,但是在训练阶段,与能并行计算的CNN相比,时效性表现的就不尽如人意了。
2.Transormer网络结构
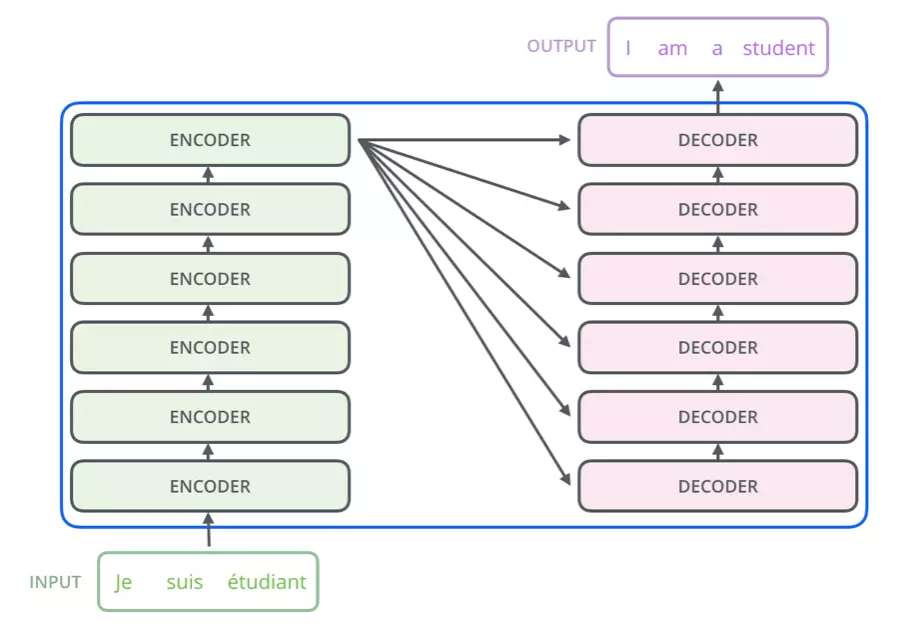
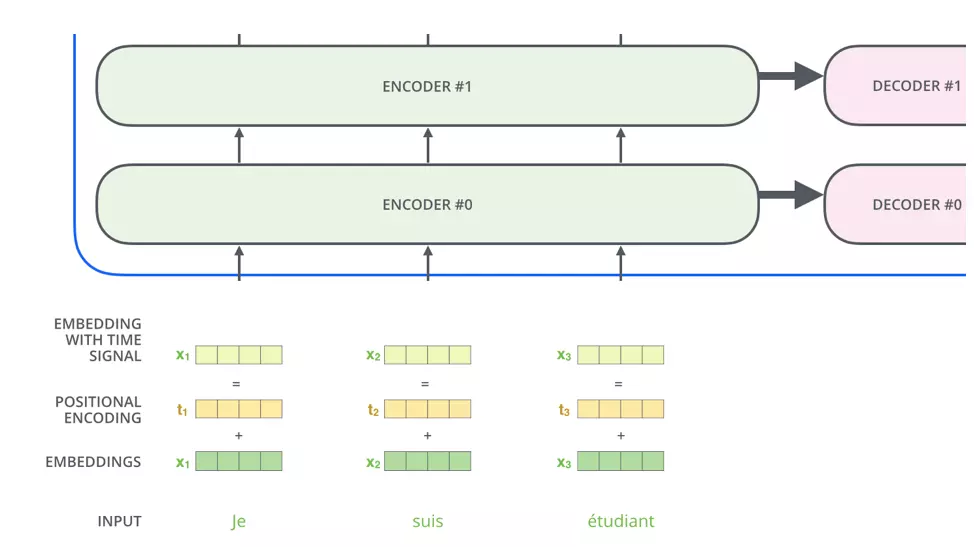
Transformer内部由6个Encoder和6个Decoder组成。
Encoder和Decoder的内部结构
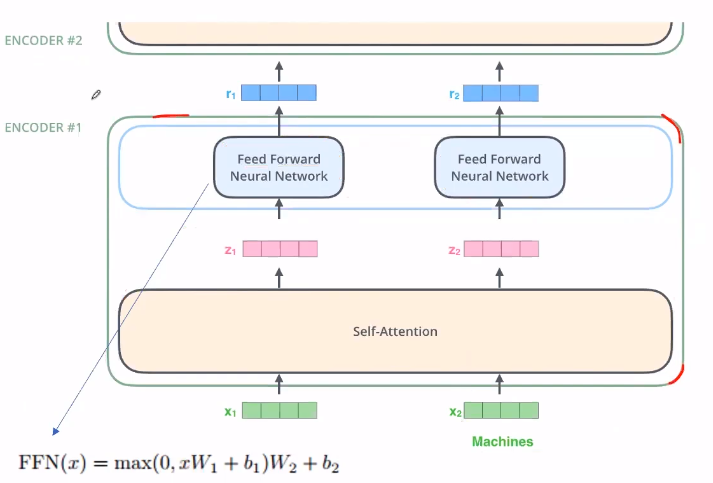
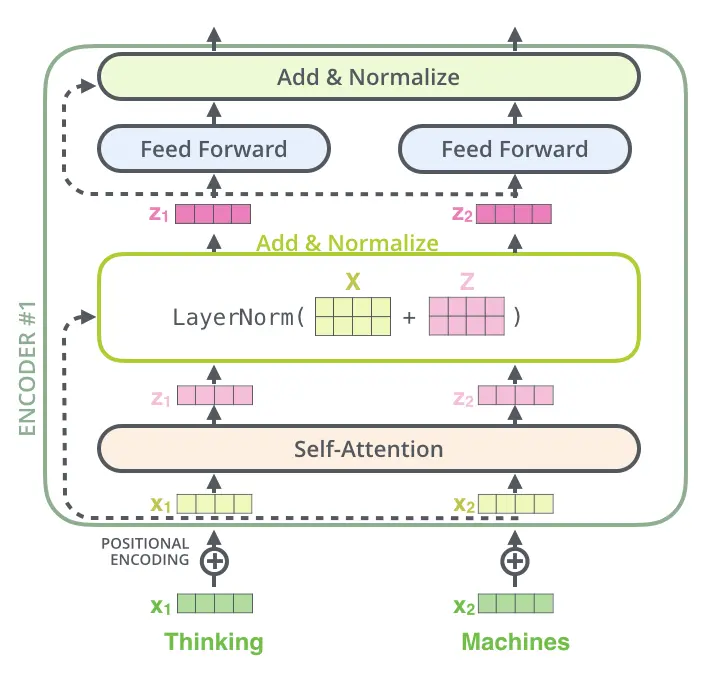
每个Encoder分为Self-Attention层和前馈网络层,Decoder接受Encoder的输入并且中间多了一层Attention。
如下图,深度仅为一层 的Transformer的Encoder结构图

Encoder
对于一个Encoder的内部结构如图,输入词$x_1$和词$x_2$的embedding,通过Self-Attention共同生成$z_1$和$z_2$,随后单独通过前馈网络得到$r_1$和$r_2$
3.Self-Attention
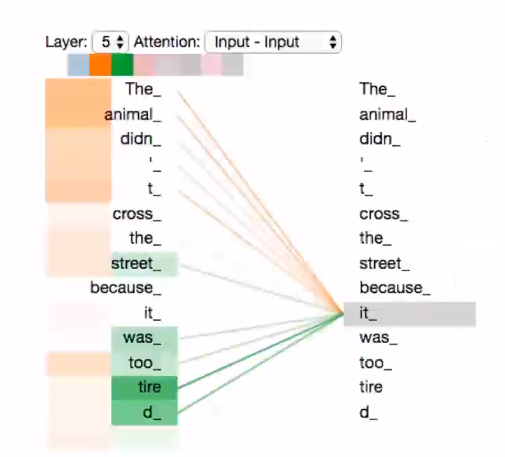
如果有下图所示的句子,将其分解为一系列的单词,每个单词都计算与其他单词之间的attention有多大。例如单词it与代词The和名次animal之间的注意力权重最大。

Attention计算
我们现在来理解Attention是如何计算的
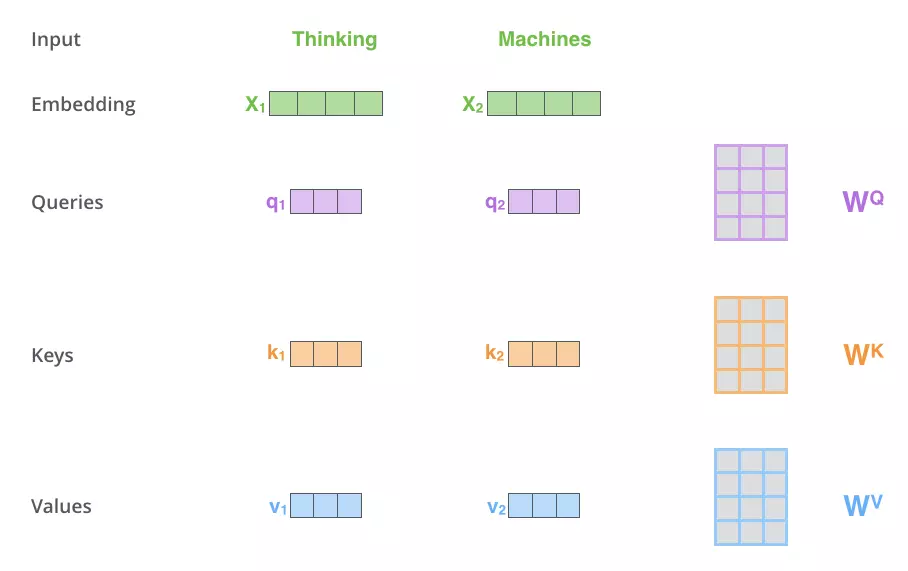
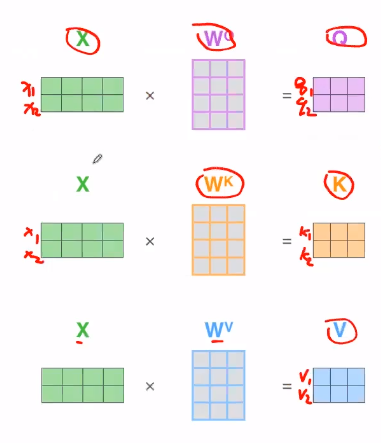
第一步: 首先根据公共权值矩阵$W^Q,W^K,W^V$来计算出每个单词embedding所对应的Queries、Keys、Values是那个向量。
$q_1 = x_1 \times W^Q$,
$k_1 = x_1 \times W^K$,
$v_1 = x_1 \times W^V$。
所有的词都共用同一个权重矩阵
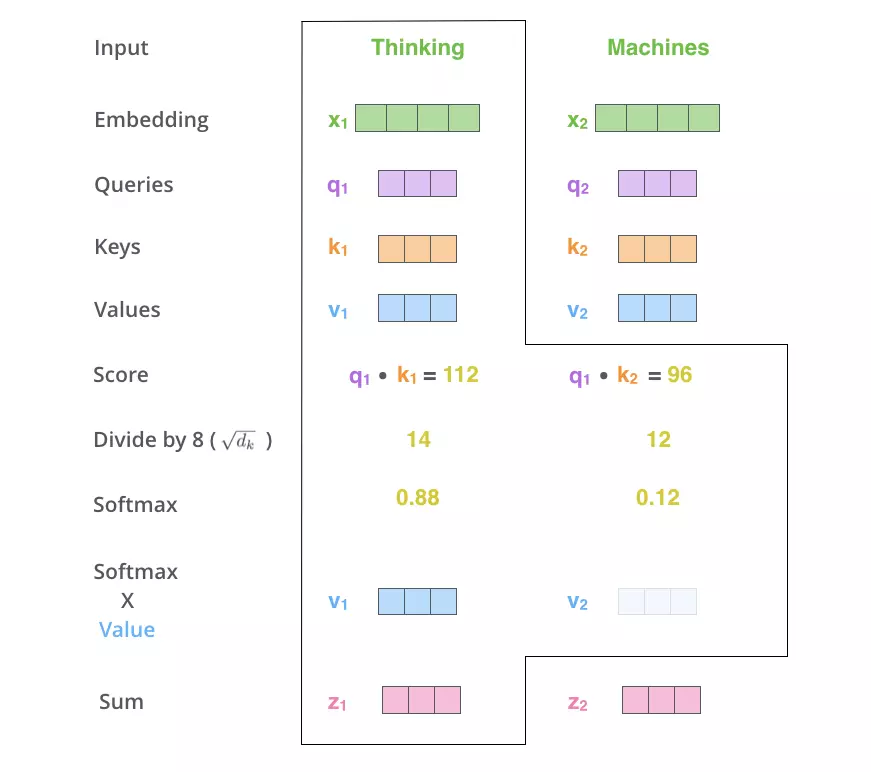
第二步: 根据如下步骤即可计算出每个输入embedding的attention向量$z$。
对Queries、Keys和Values的解释: 最初用于信息检索领域: 此时有查询q=”5G” 和两个键-值对:K=>V : “5G” =>“Huawei” K=>V : “4G”=>”Nokia”
可以看出来检索出“Huawei”的概率更大一些,所以为了能使两个不相关的词$x_1,x_2$能够相互检索,这里就可以使用公共权重矩阵来建立联系。公共权重矩阵最开始是随机化的,在之后的学习过程中逐渐学习到适当的模式。
向量化
为了加快运算,当然要进行向量化。
上述Attention计算的过程就为
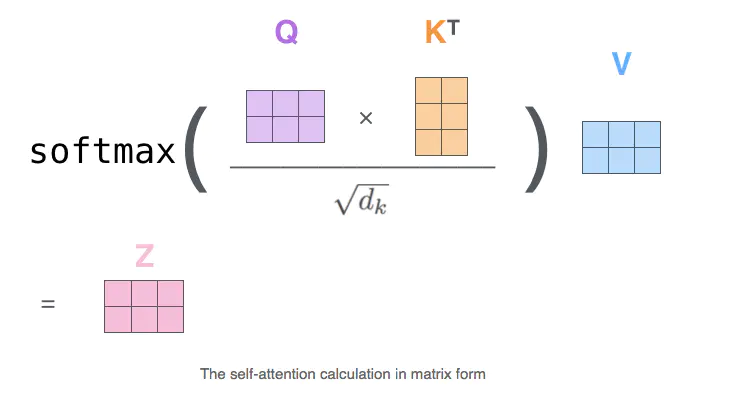
这里解释下$\sqrt d_k$的作用: 这里我们假设矩阵$Q$和$K^T$的均值为0,方差为1。那么矩阵相乘后的方差为$d_k$,来缩放其运算结果。
具体公式推导见https://www.zhihu.com/question/339723385
在进行向量化的过程中,需要注意一个序列填充的问题: 在对句子进行处理时,填充0到固定长度是一件很常见的事,但是当输入矩阵进行填充后,该如何计算attention使得其不受填充的影响呢?
https://blog.csdn.net/qq_35169059/article/details/101678207
但是呢,我观察tensorflow.org和BERT的Transformer的源码发现,其mask的逻辑是这样的。 比如,下图是计算出的$Q\times K^T$后的Attention socre矩阵: \(\begin{bmatrix} 0.3 & 0.2& 0.1 \\0.3 & 0.6 & 0.3 \\ 0.23 & 0.45 & 0.67 \end{bmatrix}\) 而我们的输入序列为$[32,22,0]$对应的mask为$[0,0,1]$
if mask is not None:
scaled_attention_logits += (mask * -1e9)
处理后的attention score为 \(\begin{bmatrix} 0.3 & 0.2& -inf \\0.3 & 0.6 & -inf \\ 0.23 & 0.45 & -inf \end{bmatrix}\) 随后计算Softmax时就可以将填充词的贡献计算为0. 并在之后与$V$相乘计算新的embedding时,未填充词不会使用被MASK词的Value,所以encoder最后输出时,未填充词的embedding始终和被MASK无关。 但是因为被MASK的词使用了未填充词的Value,所以在encoder输出时,也需要将output进行mask
def compute_output_mask(seq):
"""
因为输出的结果中包含了mask词的embedding,所以需要将这些mask词的embedding清0
:param seq: shape=[batch_size,seq_len]
:return:
"""
mask = 1. - tf.cast(tf.math.equal(seq,0),tf.float32) # [batch_size,seq_len]
mask = tf.expand_dims(mask,axis=2)
real_seq_len = tf.reduce_sum(mask,axis=1) #[batch_size,1]
return mask,real_seq_len
def get_mean_pool(seq,out):
"""
在输出层加一个池化,对未填充序列的embedding做mean
:param seq: input [batch_size,seq_len]
:param out: encoder output [batch_size,seq_len,embedding_size]
:return:
"""
mask,real_seq_len = compute_output_mask(seq)
out = mask * out
mean_pool = tf.reduce_sum(out,axis=1) / real_seq_len
return mean_pool
4. “multi-headed” attention
之前我们说,所有的词嵌入在计算attention时同用三个公共权重矩阵$W^Q,W^K,W^V$,那么如果我们像下图一样使用多个公共权重举证多计算几次,会有什么效果?
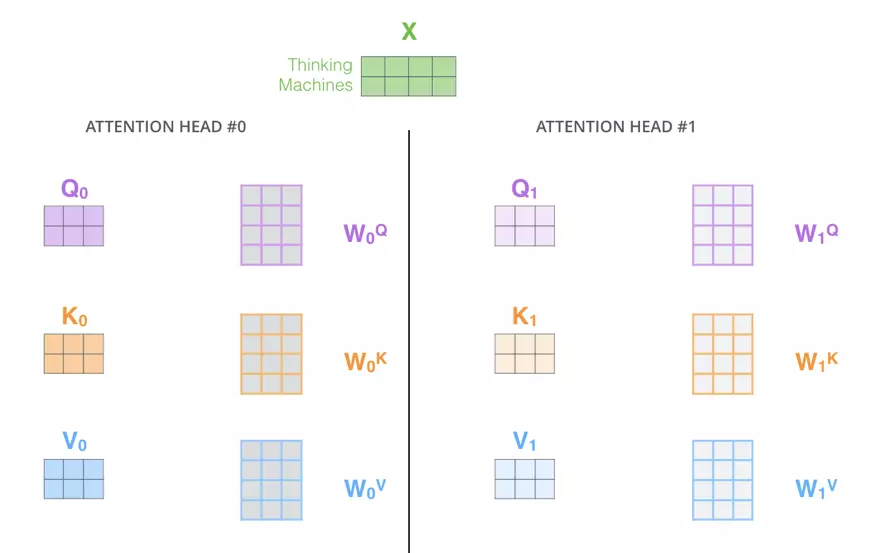
比如,现在我们采用8个不同的公共权重矩阵,产生了8个不同的Attention输出:

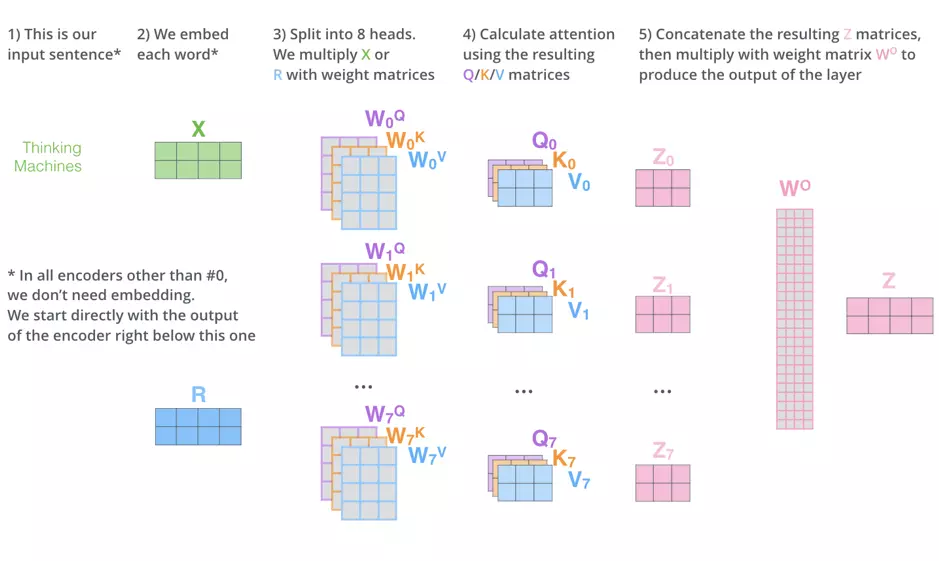
再将这8个不同的Attention heads拼接起来,乘以权重矩阵$W^o$,最后可以得到捕捉了所有attention heads的$Z$矩阵,和单head attention达成了格式上的统一。

因此,总结一下,self-attention的整个计算过程如下示意图,
但是multi-headed 能达到什么样的效果呢?
如下图,我们提取了8个head中的两个head进行展示:对于单词“it”来说,橘色部分的“The”和“animal”表达此head关注与两单词之间的指代关系,而绿色部分的“was”和“tired”表示此head更关注两单词之间的状态关系。
5.Positional encoding
需要注意的是,在我们整个transformer的框架中的输入为词嵌入与其positional encoding所得,那么这个positional encoding是干什么的?
其编码规则如下:
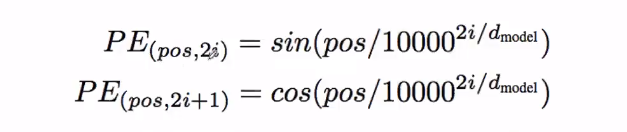
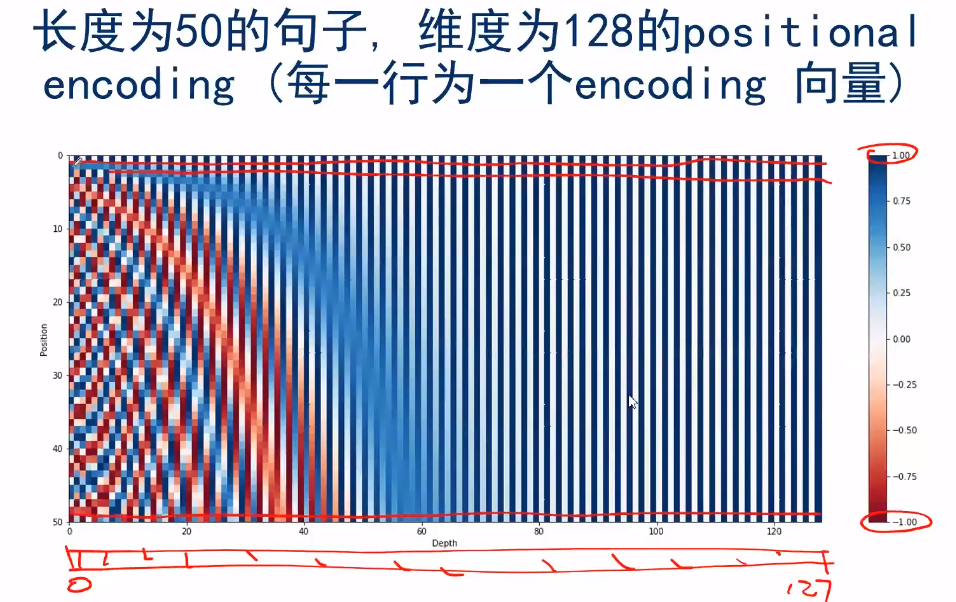
例子如下:级sin与cos交替,分母逐渐除以100…

为什么这样做?
可以看出第一行仅为01交替,越往下更越像之前的线性组合,这样可以不同单词位置的编码不一样。
但是需要注意的是,positional encoding不一定使用作者的方法,选用其他的不同的位置编码也可以。
6.Residual,Layer Normalization
每一个Encoder内部,每一层都会有一个残参连接,并且带有一个层-归一化操作。
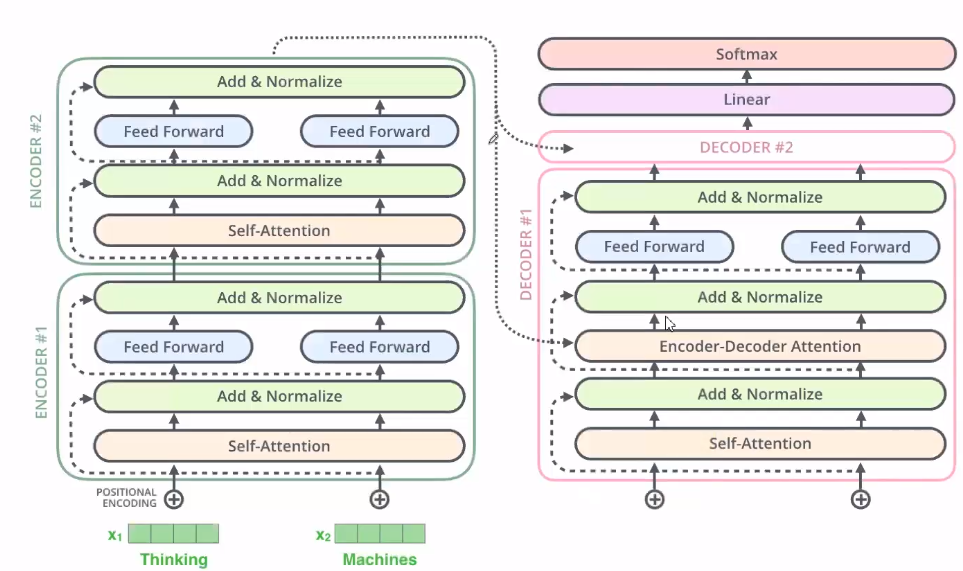
7.Decoder组成
看看如下的Transformer结构展开图,每个Decoder在Encoder-Decoder Attention层中都会接收Encoder中的K,V向量矩阵 作为输入,那么其具体是做什么的呢?
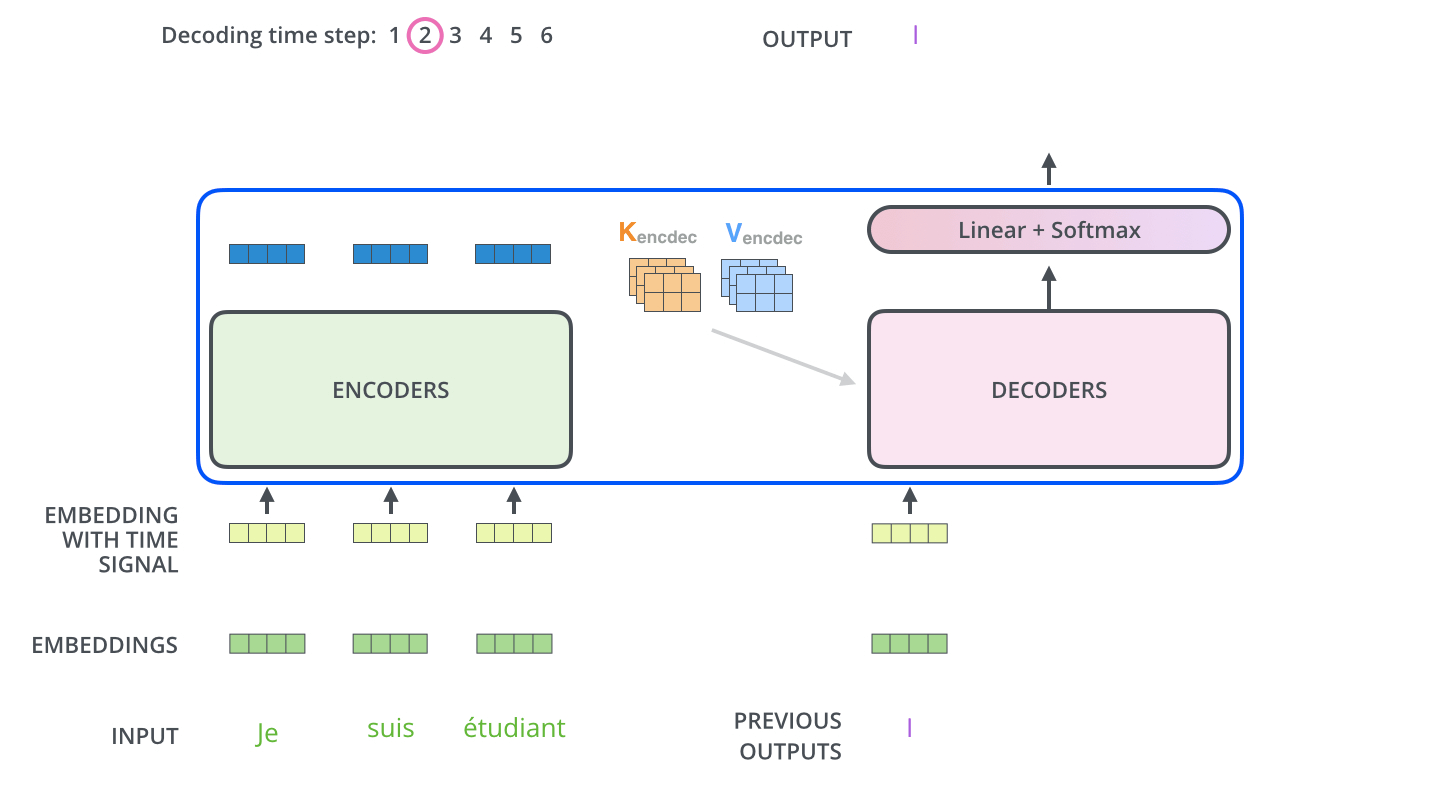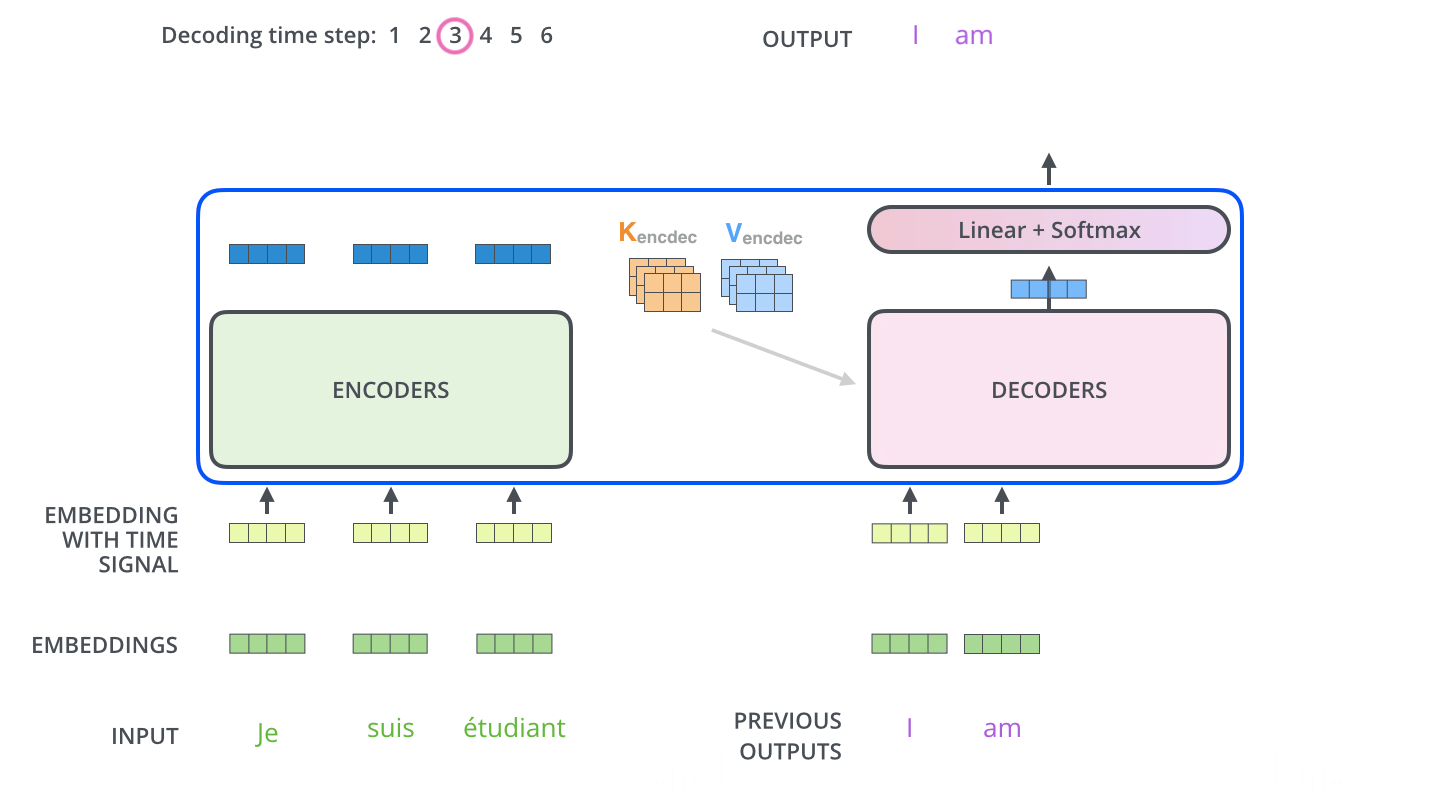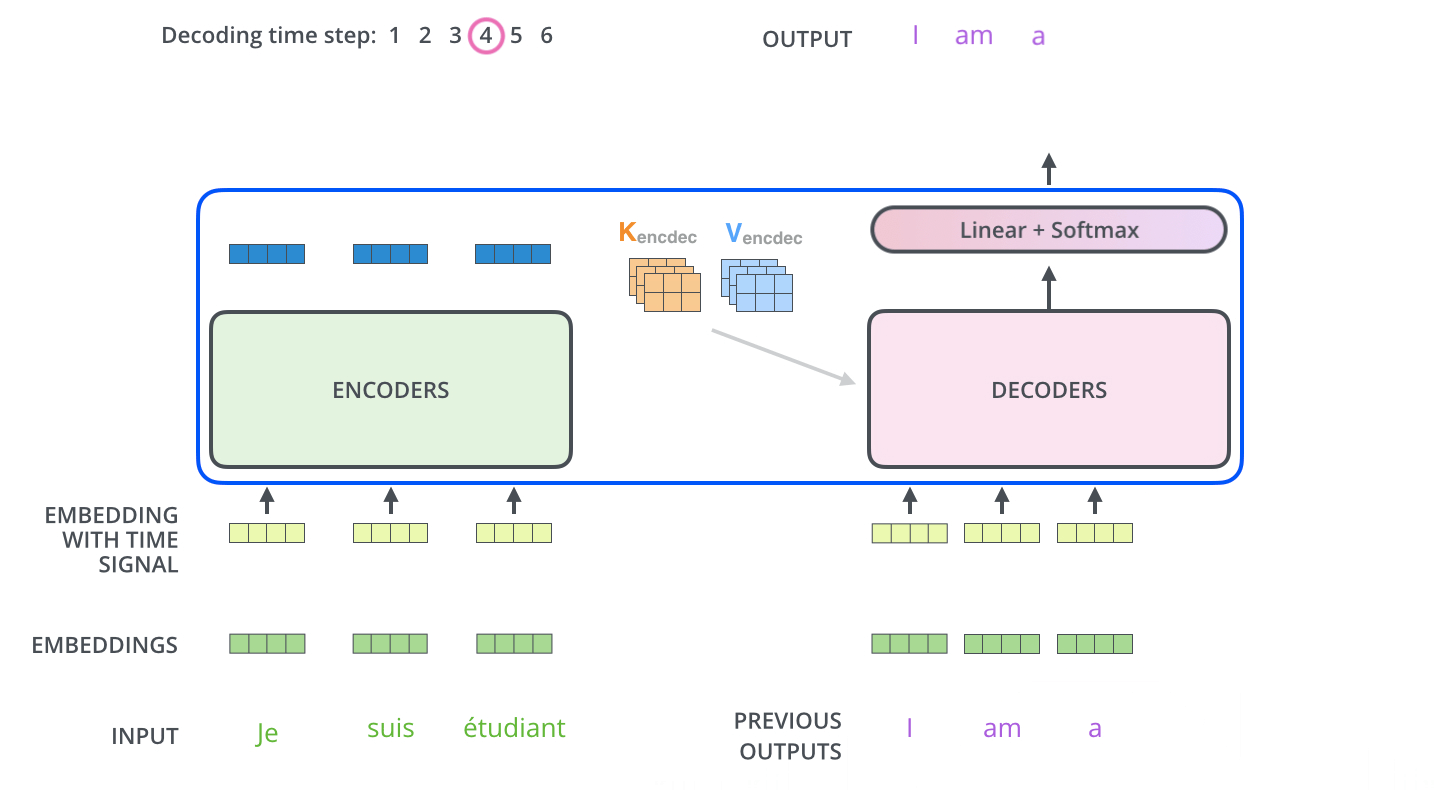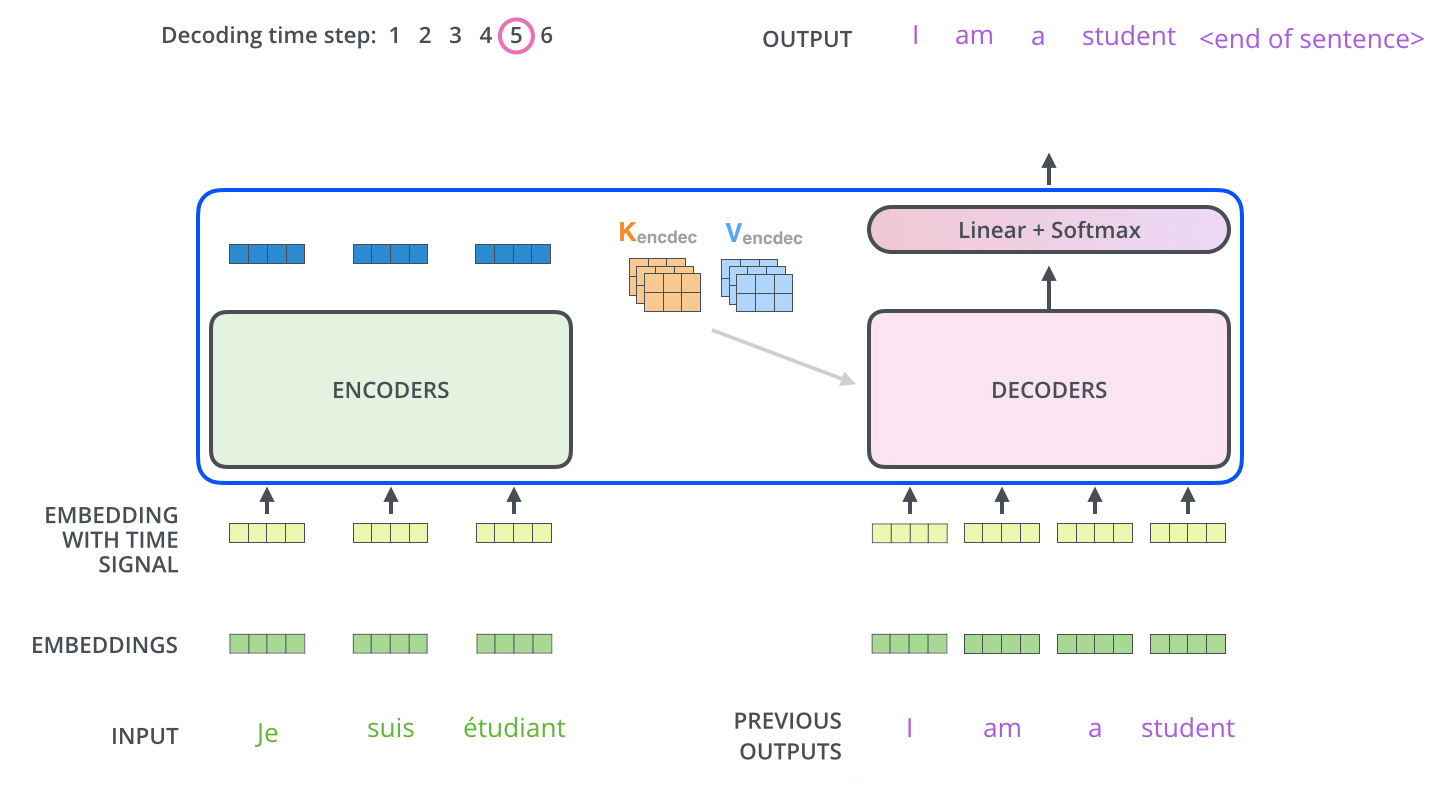
我们来看下下面的动图,我们将Encoder所产生的输出输入到Decoder中,在Decoder的第一个时间步输出最可能出现的单词“I”,第二个时间步输出在单词“I”的概率下最可能的单词“am”,以此类推….
我们可以发现,这其实和普通的RNN Encoder-Decoder模式一样。
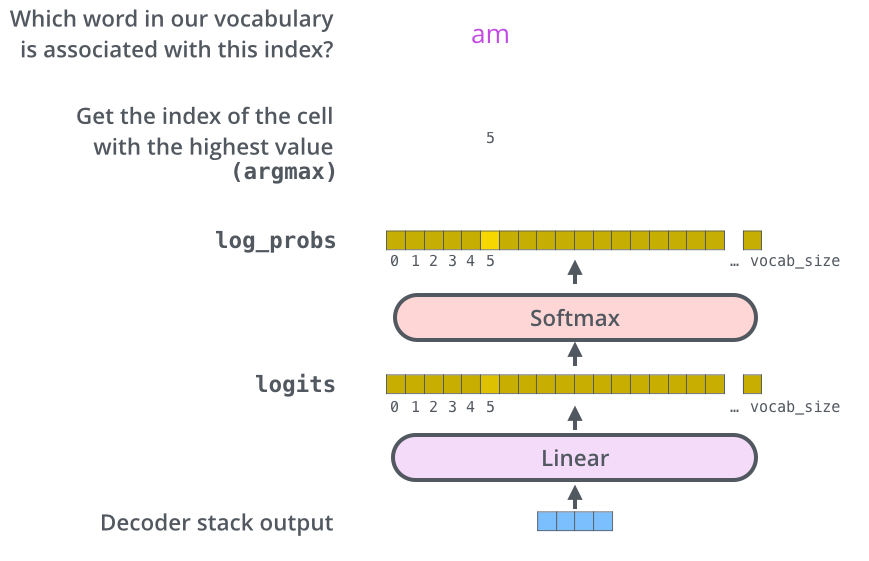
在Decoder的后面还跟着全连接层和Softmax层,全连接层的作用为将Decoder的输入向量映射为词汇表大小的logit,可以认为每一维logit都对应一个单词的score,随后Softmax层转化成每个词出现的概率。
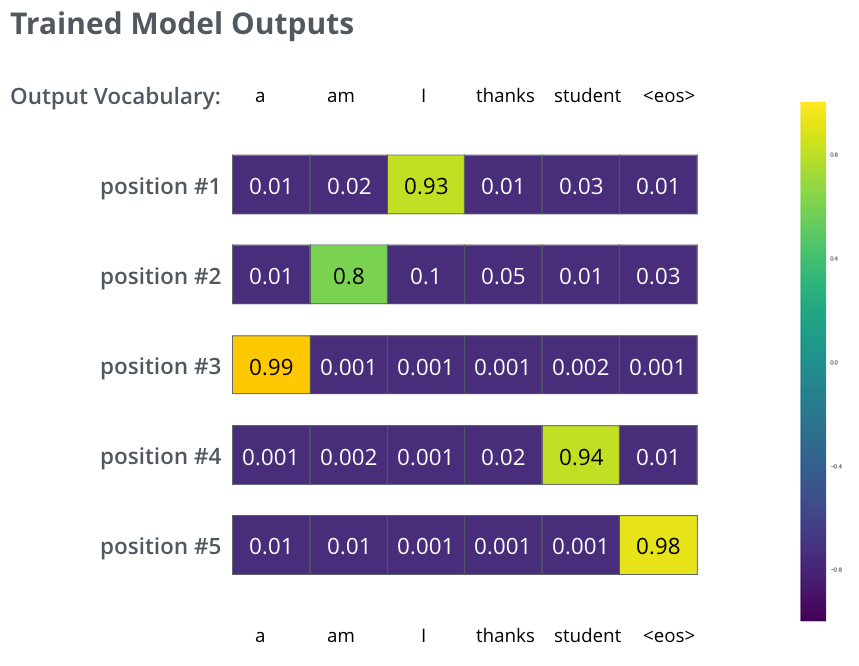
在经过了大规模预料训练后,我们模型的输入大致如下,其训练的损失函数为与one-hot标签的交叉熵损失。
8.Training trick
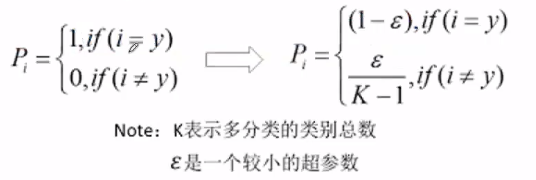
Label Smoothing (regularization):不使用完全的ont-hot编码作为标签,而是赋予当前词较大的概率,其他词较小的概率,来避免过拟合。
比如[0,1,0,0,0,0]—->[0.2,0.9,0.2,0.2,0.2,0.2]
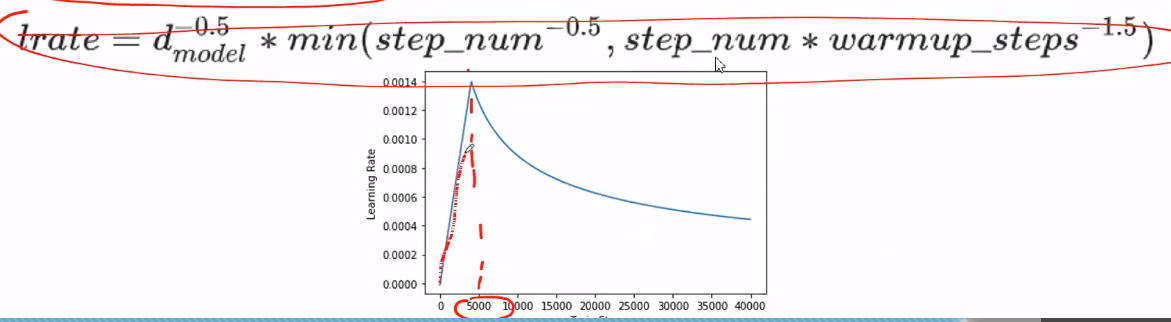
Noam Learning rate Schedule :刚开始线warmup个5000步线性增长达到较大的一个learning rate,然后再通过指数减少到想要的learning rate。
9.Transformer特性
优点:
- 每一层的计算复杂性比较低
- 比较利于并行计算
- 模型可解释性比较高
缺点:
- 有些RNN轻易可以解决的问题,transformer没做到。比如复制string,或者推理时碰到的序列长度比训练时更长。
- RNN图灵完美,Transformer不是。图灵完备的系统理论上可以近似任意图灵计算机可以解决的算法。