课程信息:感谢@葛翰驰老师,贪心科技–“ 共同战疫” NLP系列专题 直播课,本文所有版权归贪心科技https://www.greedyai.com/所有。
Lecture 3 - 从Transformer到BERT模型
1.背景介绍
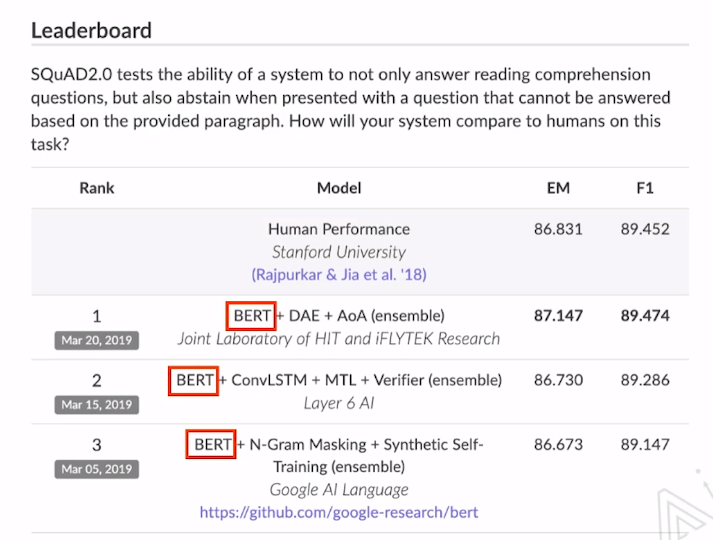
首先看18年的时候BERT在SQuAD2.0中的排行榜单,可以看到BERT取得了绝对的领先。
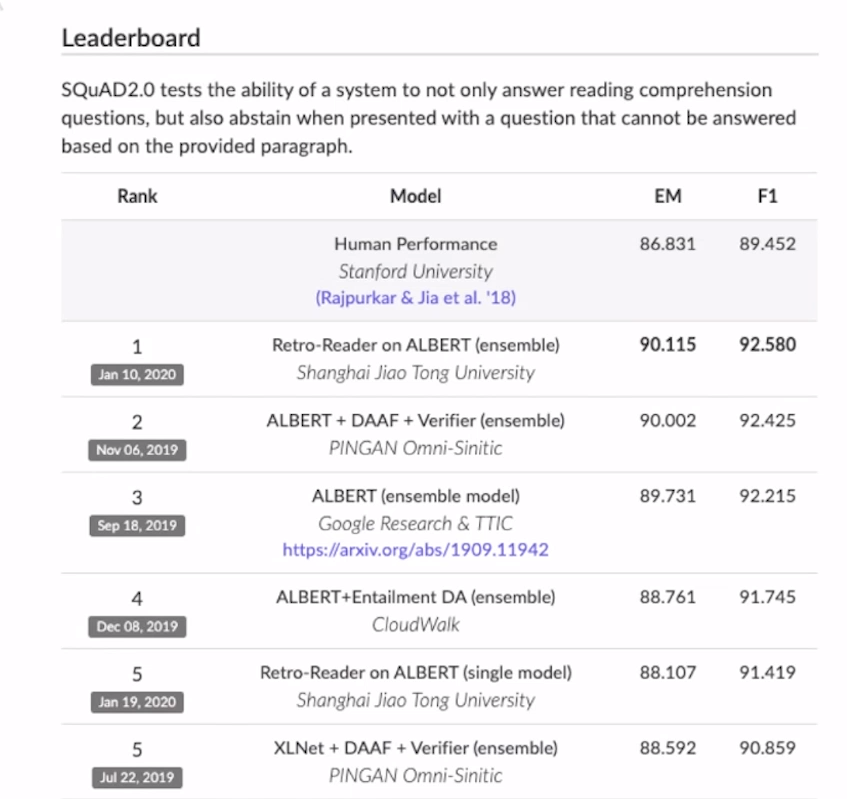
再看看现在的榜单取而代之的是ALBERT,已经超过了人类的区别能力。
在NLP领域,语言模型的预训练早已被证明是提高下游模型表现的不二选择,从目前提出的预训练方法来看,主要可以分为两个类型如下, 1)基于特征(Feature-Based)主要的代表有ELMO,用做任务的模型来学习提前预训练好的语言模型内部隐状态的组合参数。
2)微调(Fine-Tuning)主要的代表有OpenAI GPT,用做任务的数据来微调已经训练好的语言模型。
而BERT则利用了前面一些模型的优点,其模型结构如下,可以看出结构上与ELMo十分相似,只是使用Transformer来提取特征:
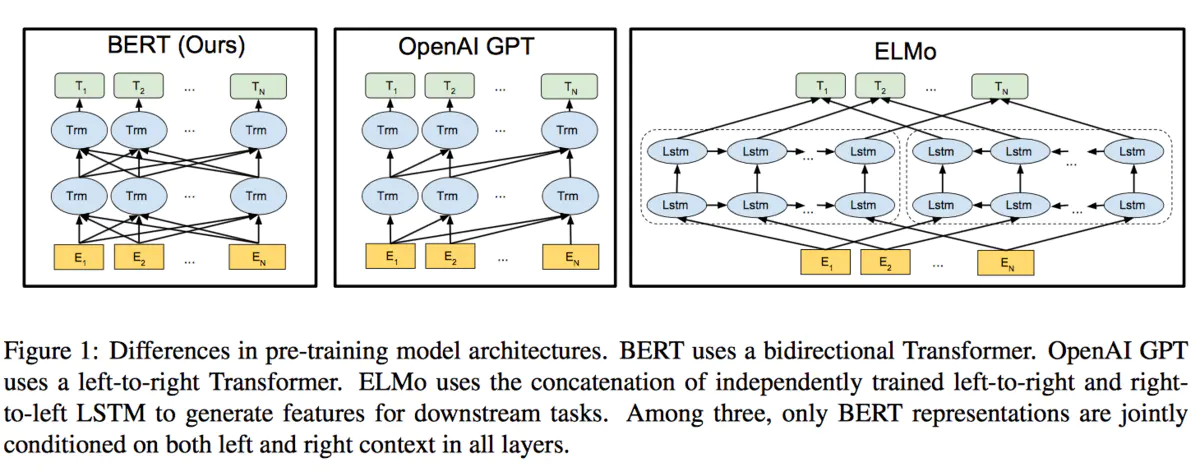
对照上图BERT的模型结果图,总结下双向性:
- BERT是多层的Transformer encoder堆叠而成
- 每层只存在一个transformer encoder,并不像图中所示每个输入词就一个transformer encoder cell。
- 既然每层只有一个transformer encoder cell,那么其双向性如何实现的呢? MLM任务,[MASK]通过attention均结合了左右上下文的信息,这体现了双向。
2.模型结构
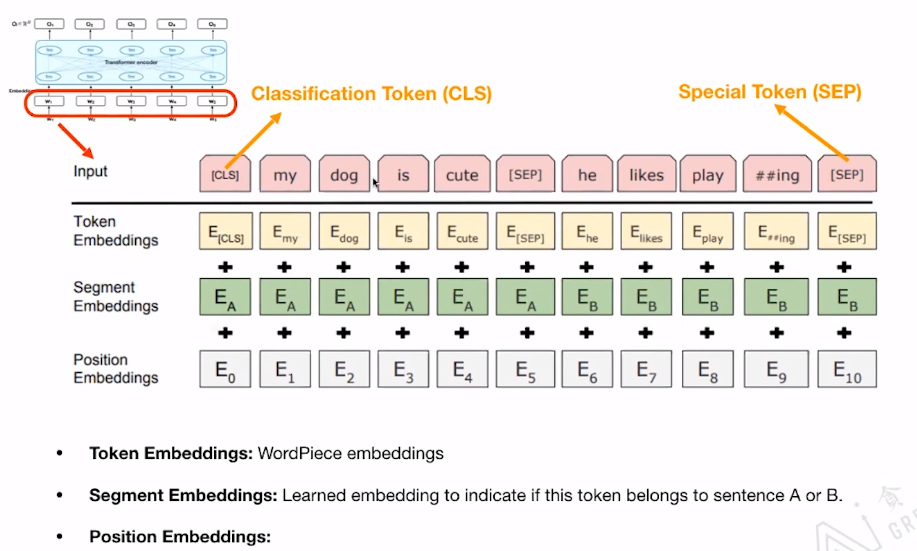
模型的输入: 包括三个部分
- Token Embedding:词条的Embedding
- Segmeng Embedding:学习Embedding来识别此Token属于句子A还是B
- Position Embedding: 为每个单词提供其位置信息。
Classification Token(CLS) 的作用:用来做Classification task。
Special Token(SEP) 的作用:用来区分两个句子。
3.Pre-train BERT
两个预训练任务:
- Masked Language Model(MLM)
- Next Sentence Prediction(NSP)
而Bert的Loss就是这两个任务的Loss相加 Loss_BERT = Loss_MLM+Loss_NSP
Bert官方提供了两个大小版本的BERT:BERT Base 和BERT Large 其中BERT base:
- 12层
- Hide layer embedding 维数:768
- 12 个head
- 总参数:110M
BERT Large:
- 24层
- Hide layer embedding 维数:1024
- 16 head
- 总参数:340M
Masked Language Model(MLM)
就是将输入的句子15%的词给屏蔽掉,然后根据其周围的上下文来预测被屏蔽的词。

但是屏蔽根据以下规则:
- 80%的概率将被屏蔽词替换成[MASK]标记
- 10%概率将被屏蔽词替换成另一个单词
- 10%的概率保持不变
需要注意的是,我们的LOSS计算只计算被[MASK]的部分的,上面的规则能保证鲁棒性。
Next Sentence Prediction(NSP)
关注于两个句子之间的关系。
我们之前在模型结构图中可以看到,BERT的输入有两个句子,分别通过[SEP]分离开,在NSP任务中,我们就需要根据句子A,B,来预测B是否是A的下个句子。
其二分类任务规则:
- 50%选取真正的下个句子
- 50%随机选取句子
Train tips
需要注意以下几个参数: dupe_factor:允许从文本中重复采样的比率,如果训练集很少的话,可以适当调高一些。 max_predictions_per_eq:再一个样本中最大允许masked的token数量。 do_whole_word_mask:对整个单词进行mask,而不是单词的一些字符。即进行word级别的learning,而不是字符级别的learning。 Length of a sentence is larger than the limit:对于超过一定长度的句子,将会从开头或者末尾去除一些单词。
4.BERT学到了什么
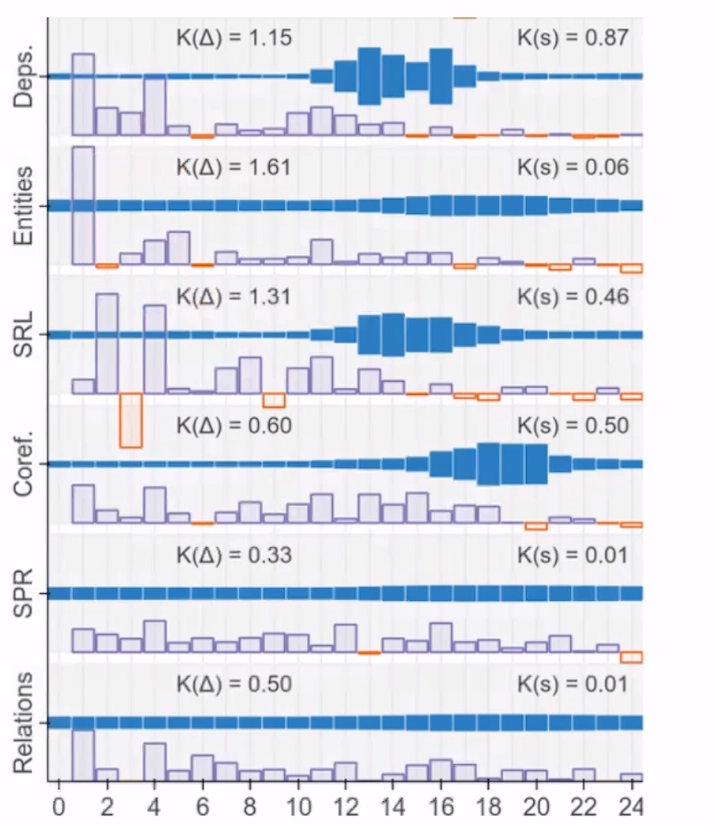
以BERT Large为例子,来探究BERT究竟在24层中学到了什么,为什么BERT会如此的强大。
看下图,分别为7个NLP任务,深蓝色的区域代表其分别在24层中发挥作用的大小,可以看到对于不同任务在不同层发挥着不同的作用。
和ELMo一样,将每一层的embedding加起来,或者average,甚至weighted average。至于weight可以从不同的任务中获得。
5.BERT的应用场景(Fine-Tuning)
- 分类
- 问答
- 命名体识别
- 聊天机器人(Intent Classification & Slot Filling)
- 阅读理解
- 情感分析
- Reference Resolution
- Fact Checking
- etc.
下面列举三个应用场景例子:
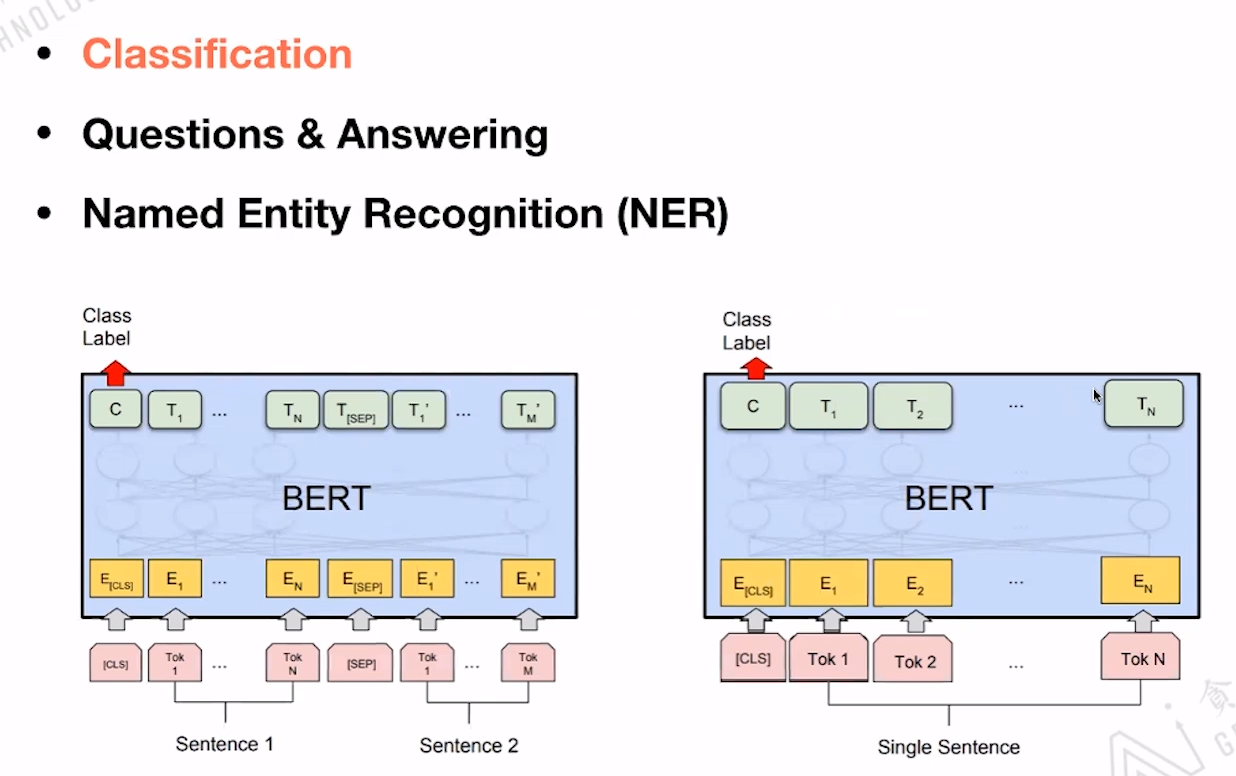
Classification: BERT模型基本不变,输出只用关注[CLS]的Embedding即可。
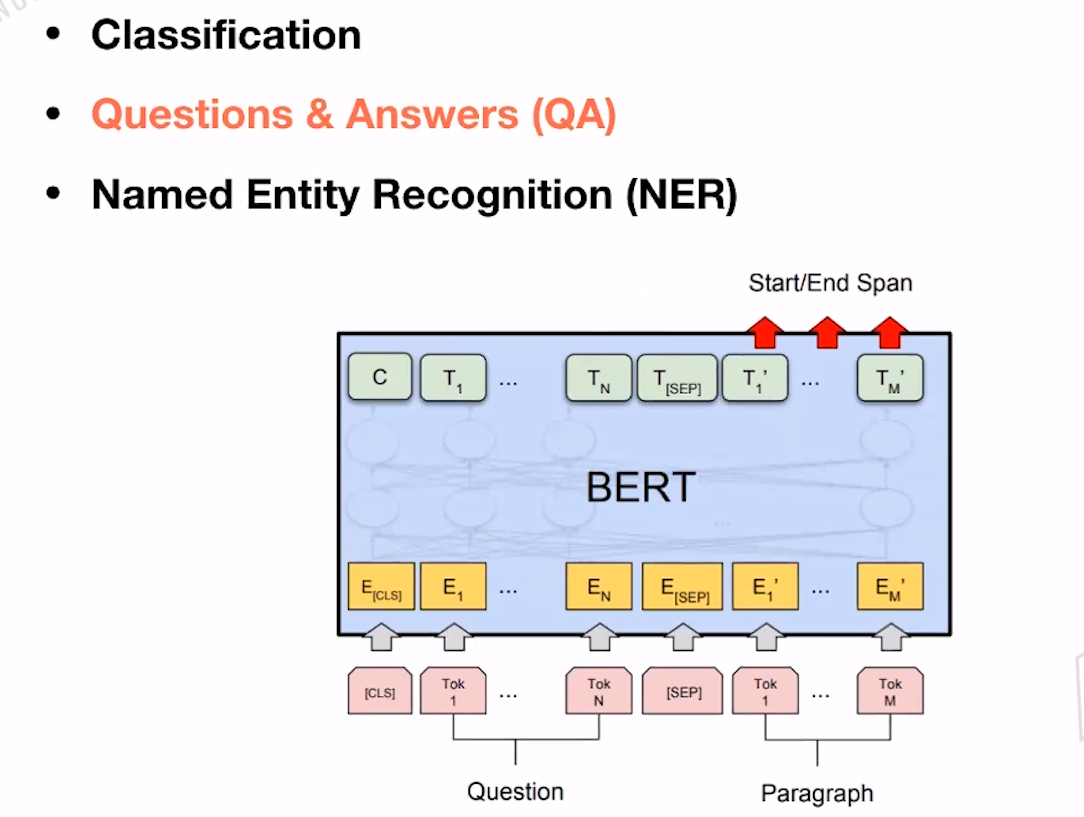
Questions & Answers: 输入为Question和Paragraph,我们需要根据Quenstion在Paragraph中知道到答案的位置。因此需要两个额外的向量:Start Vector 和End Vector。 Start Vector 和End Vector可以是答案在Paragraph中的索引,start-end之间的即为答案。如果End>start,可以认为没有找到答案。
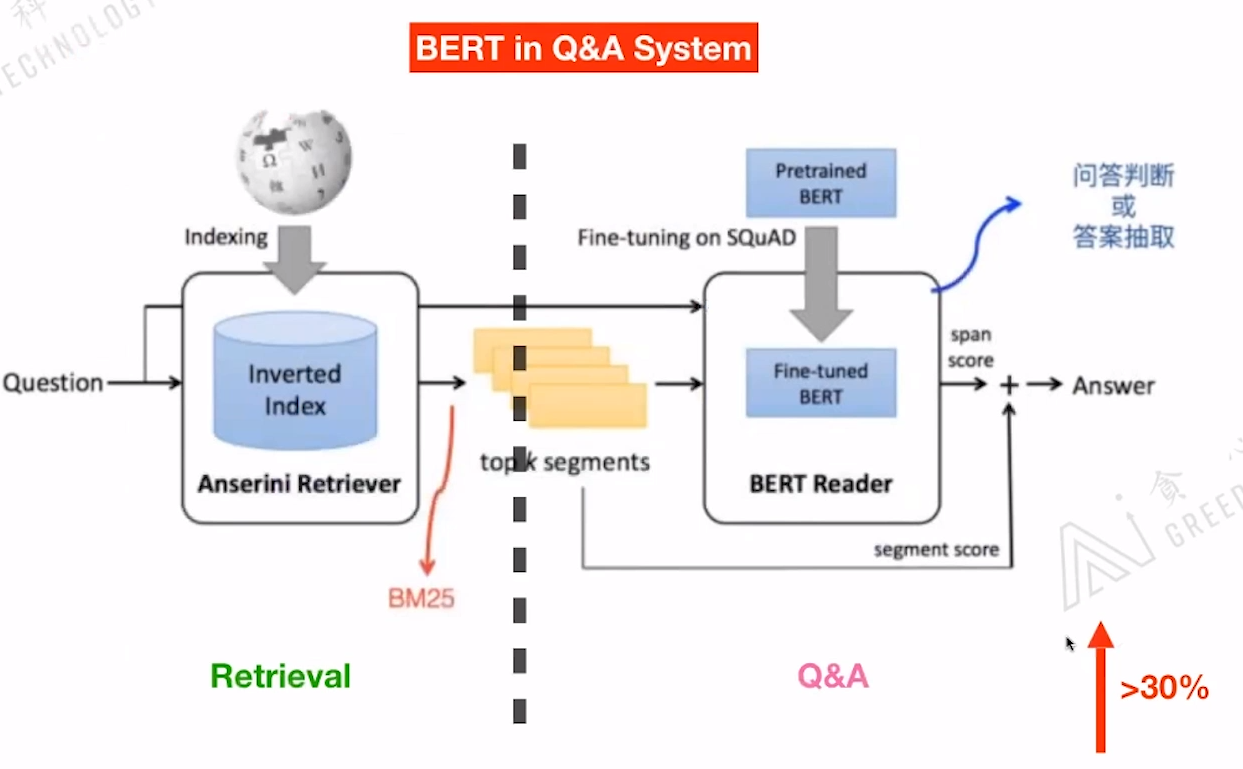
下图为BERT在Q&A系统中的应用流程图:左边还是传统的信息检索部分,通过Qustion寻找到可能相关的语料,右边根据检索出来的语料输入到Fine-tuning过的BERT模型中,来输出答案。
BERT的加入可以使的性能提升30%左右。
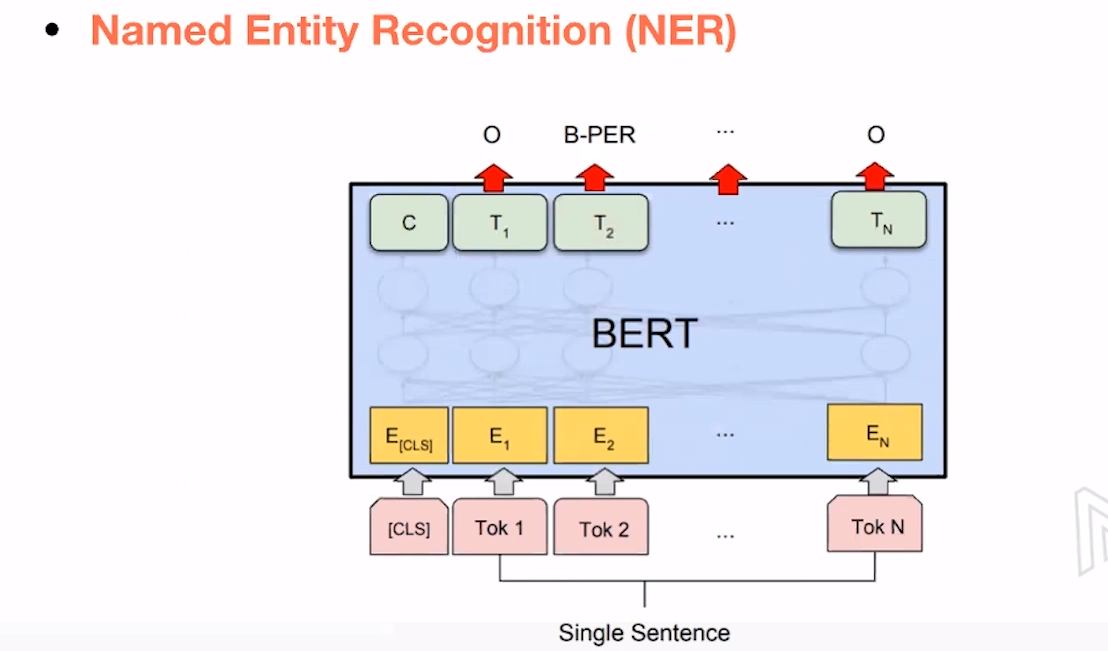
Named Entity Recognition(NER):token的输出向量表示其属于哪个命名类别。
Chat Bot:[CLS]来判断想要进行哪类动作,token embedding来进行Slot Filling.