课程信息:感谢@蓝振忠老师,贪心科技–“ 共同战疫” NLP系列专题 直播课,本文所有版权归贪心科技https://www.greedyai.com/所有。
Lecture 4 - 从BERT到ALBERT
背景介绍
随着CV技术越来越成熟,CV方面呈现出比NLP更快的发展,简单的看下CV之前几年的发展史可以看出来从2012年开始有了飞速的提升。
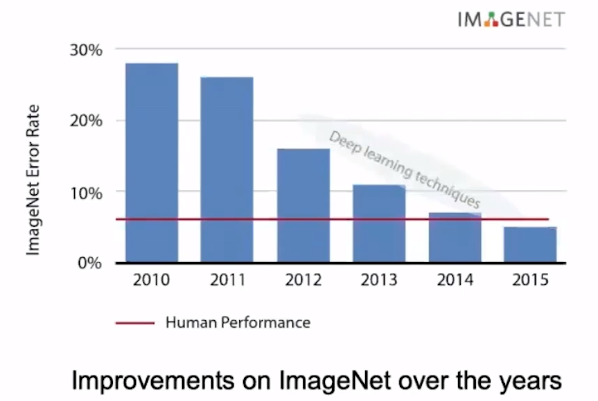
是什么原因导致了CV方面巨大的提升呢?观察下图,可以发现网络深度占据了主要的原因。
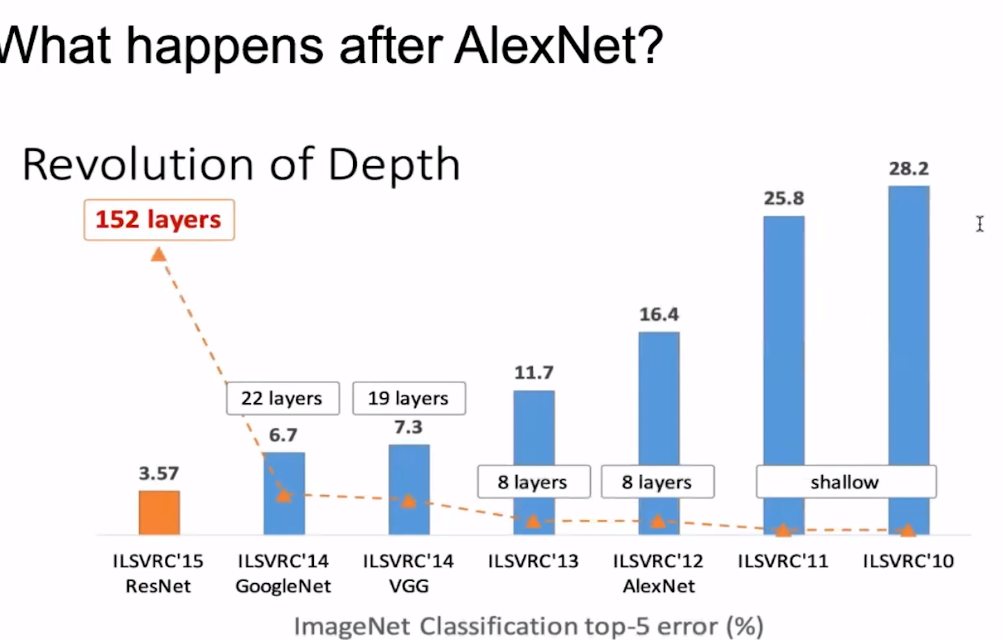
那么CV方面的经验是否能够应用于NLP呢?观察如下实验,对BERT模型不断的加大层次深度(L)和宽度(H),我们可以获得越来越好的性能。
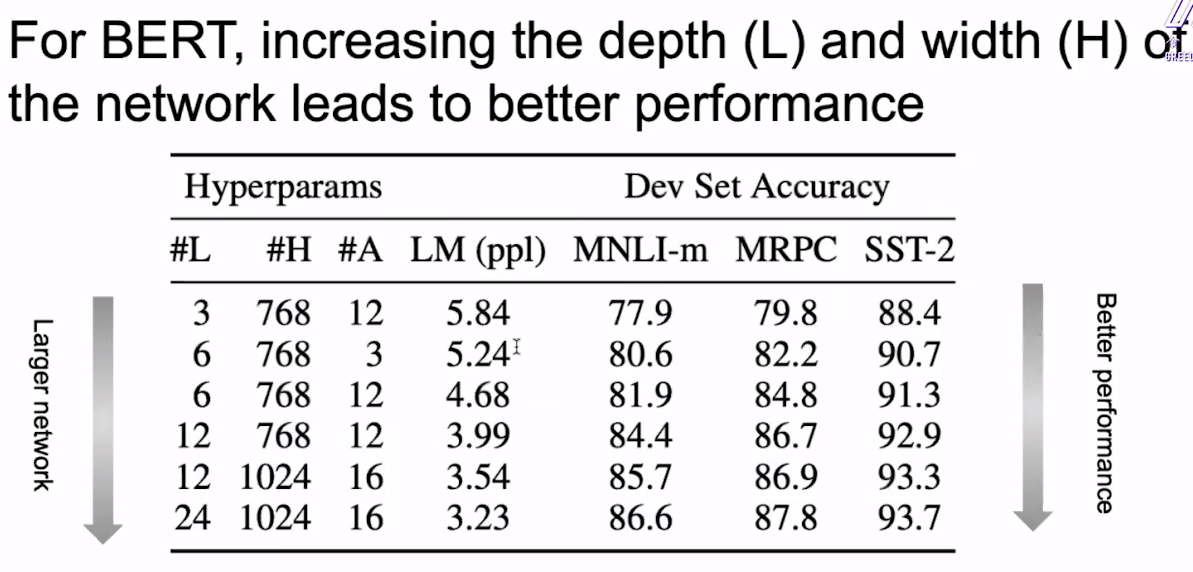
但是BERT Larget已经很大了,再大的话参数就多的爆炸了,不再是我们可以能够训练的了。
ALBERT:A Lite BERT for Language Understanding
目标:在降低参数的同时,能不能使性能不要降的特别厉害。
首先让我们看看,在BERT中参数主要集中在哪些地方,以及存在着哪些问题。
如下图为Transformer的一个基本块,将其分为上下两部分,上面为Attention feed-forward block,集中了80%的参数;下面为Token embedding projection block,集中了20%的参数。

方法1:因式分解嵌入参数
我们注意到:
- Token embedding 是上下文独立的,而hidden layer embeddings则是上下文相关的
- Token embeddings是稀疏更新的
在BERT中,词embedding与encoder输出的embedding维度是一样的都是768。但是ALBERT认为,词级别的embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本生的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让H»E,所以ALBERT的词向量的维度是小于encoder输出值维度的。
在NLP任务中,通常词典都会很大,embedding matrix的大小是E×V,如果和BERT一样让H=E,那么embedding matrix的参数量会很大,并且反向传播的过程中,更新的内容也比较稀疏。
结合上述说的两个点,ALBERT采用了一种因式分解的方法来降低参数量。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,说白了就是先经过一个维度很低的embedding matrix,然后再经过一个高维度matrix把维度变到隐藏层的空间内,从而把参数量从$O(V×H)$降低到了$O(V×E+E×H)$,当E«H时参数量减少的很明显。
效果如图:减少了17%的参数,性能只降低了不到1%

方法2:跨层参数共享
将不同层的参数进行了可视化:我们发现不同层之间的参数是有关联的,那么我们是否可以直接将这些层的参数共享起来?

作者分别对共享全连接层参数、共享attention参数和参数全共享做了实验测试,效果如下: 全共享甚至能减少70%的参数,只减少不到3%的性能。
虽然参数的减少导致了性能的降低,但是参数的急剧减少带来的是计算速度的大幅度增加,为此我们可以通过扩张隐层来追求更好的性能
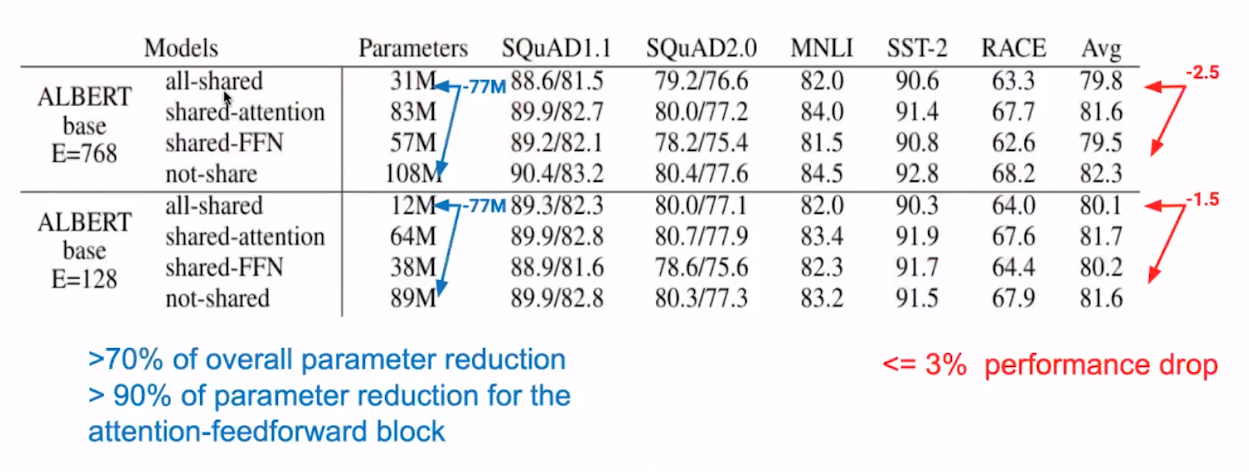
可以看到,共享FFN的参数是导致结果下降的主要原因;
ALBERT采用了attention模块和FFN模块的参数都共享的方案,尽可能减少参数量,而对performance不会产生大的影响;
尝试对ALBERT变宽和变深之后的表现:我们将BERT-Large的宽度扩大了4倍,但是仍然是BERT参数的70%。
但是由于网络规模变大的原因,ALBERT-xxlarge的训练速度只有BERT-Large的0.3 。但是,其取得了甚至更优异的性能。

方法3:句子连贯性预测
在预训练任务上提高:改造NSP任务,强化网络学习句子的连续性;
NSP任务实际上是一个二分类任务,即预测两句话是采样于同一个文档中的两个连续的句子(正样本),还是采样于两个不同的文档中的句子(负样本)。NSP任务实际上包含两个子任务,即topic预测和关系一致性预测, 而topic预测其实很简单;NSP在很多实践中被证明没有太好效果;
因此,ALBERT选择去除topic预测的影响,只保留关系一致性预测,于是提出了一个新的任务 Sentence-Order Prediction (SOP),SOP的正样本和NSP的获取方式一样,负样本把正样本的两句话顺序反转;

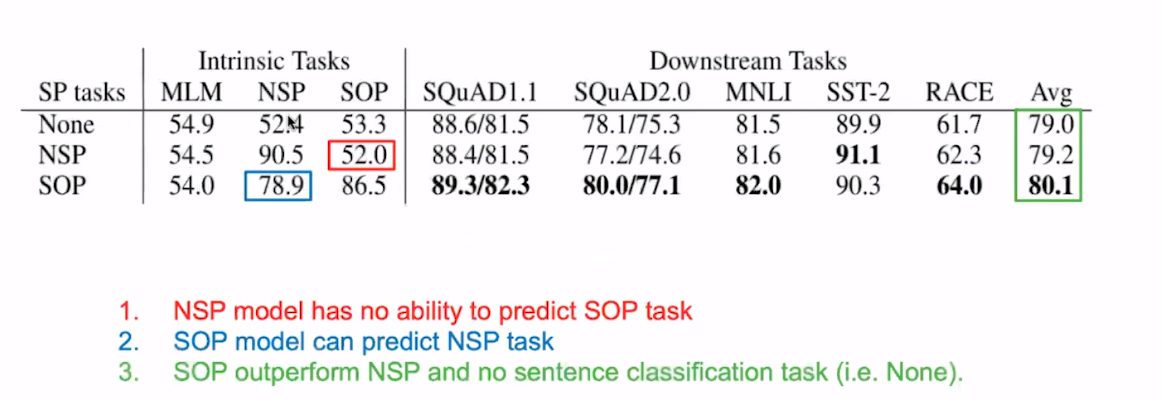
将NSP替换为SOP任务后,结果如下,并且实验结果表明,
- SOP任务中同样也能学习到NSP任务
- NSP任务不能学习到SOP任务
- SOP任务优于NSP任务
方法4:去掉dropout
因为MLM是个很难得任务,因此很难造成过拟合,并且dropout会有很多临时变量占用的内存。
为此,可以去掉dropout来寻求性能上的提升。
