请咨询作者同意后转载。
discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code
| 期刊/会议: | NDSS(B类) |
|---|---|
| 发表时间: | 2016年2月 |
| 发表机构: | University of Bonn |
方法概述
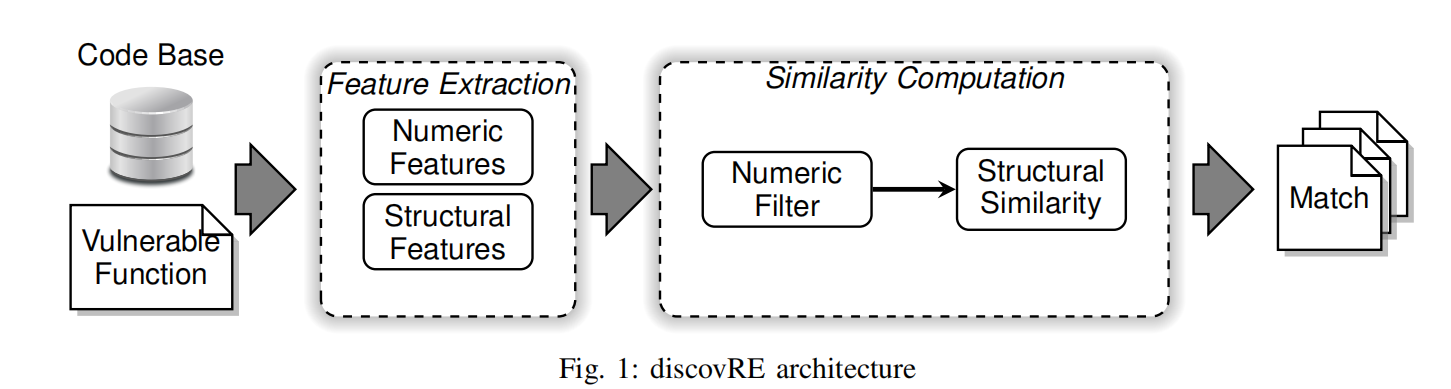 输入:IDA反汇编过的二进制函数
输入:IDA反汇编过的二进制函数
特征提取: 数字特征(指令数、局部变量数、基本块数),结构特征(CFG和其他基本块特征)。
相似度计算:这些Filter可以在早期识别不相似的函数,来增加准确率。
Numeric Filter:把输入函数当作search pattern,使用KNN算法来基于数字特征寻找相似函数。
Structural Filter:基于maximum common subgraph isomorphism (MCS)建立Structural Similarity评估标准。是最复杂的filter。
方法实现
A. Data set
(Ⅰ)开源软件选择:要能够在不同的平台、编译器、操作系统运行。 尽可能的多覆盖各种库。
BitDHT, GnuPG, ImageMagick,LAME, OpenCV , SQlite and stunnel 。
总共包含超过31k个函数
预处理:将指定平台或编译器的函数删除、还将包括汇编代码的函数给删除、仅考虑五个基本块以上的函数。
(Ⅱ)函数去重: 重复的函数可能会造成跨平台的偏差。将所有引用内存地址的比特清零,然后计算比特校验码。
(Ⅲ)Identification of robust numeric features: 评估特征robustness的标准:1.仅在所有的编译选项下变化小。2.值的分布空间应当大。
为了评估特征特征的质量,选用皮尔逊相关系数,+1代表强相关,0代表不相关,-1代表负相关。
不同的特征评分结果如下:
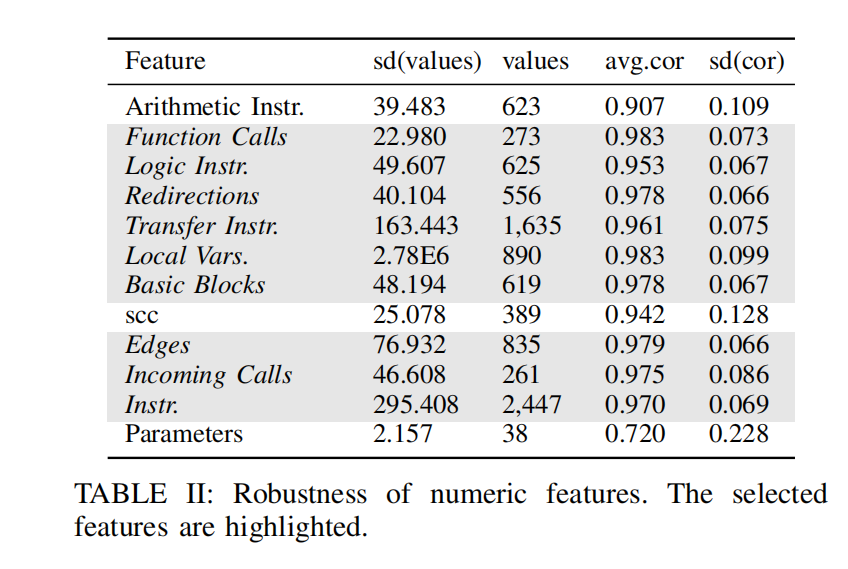 前两列的值越高,代表相关性越强,第三列为平均相关系数,第四列为相关性的标准差。我们要寻找的就是高相关性,低标准差的特征。
前两列的值越高,代表相关性越强,第三列为平均相关系数,第四列为相关性的标准差。我们要寻找的就是高相关性,低标准差的特征。
B.Numeric filter
出于性能和内存的考虑,选择了KNN算法来做相似性函数查询,
(1)数据标准化:因为不同的特征具有不同的范围,所以会导致在KNN计算距离时出现问题。所以每个值都采用均值为0,标准差为1来标准化。
有可能出现个问题:两个函数的特征映射碰撞,所以在返回时会将所有映射到这个点的函数返回。 另外,distance threshold应当用来移除那些相似度很低的函数。
(2)Evaluation of the numeric filter: 采用k-d trees作为距离测量标准,并使用PCA进行降维
C. Structural Similarity
在这个阶段,输入为经过Numeric filter过滤后的query function的最近邻。给定基本块和其连接,我们定义过程间控制流图为函数$f$的结构表示:
\[G_{f}:=(\lbrace v | v \text { is basic block in } f\rbrace,\lbrace(u, v) | u \text { redirects to } v\rbrace)\](1)Basic block distance:在这里,我们不仅仅使用函数的结构属性,我们还要额外的使用各个基本块中各自的特征。例如:
首先,每个节点都会有一个关于其在函数中拓扑顺序的标签。
其次,字符串引用和常量保存。
再次,每个节点包含其自身的robust features集合。
因此,定义基本块之间的距离如下:
\(d_{B B}=\frac{\sum \alpha_{i}\left|c_{i f}-c_{i g}\right|}{\sum \alpha_{i} \max \left(c_{i f}, c_{i g}\right)}\)
其中,$c_{if}$为函数$f$的numeric feature$i$。对于字符串特征将绝对差替换成Jaccard距离。
(2)Graph matching algorithm: 这里基于最大公共子图同构问题(MCS)来计算图的相似性。
传统的MCS距离定义如下:
\[d_{\text {mes.orig}}\left(G_{1}, G_{2}\right):=1-\frac{\left|m c s\left(G_{1}, G_{2}\right)\right|}{\max \left(\left|G_{1}\right|,\left|G_{2}\right|\right)}\]为了说明两个基本块之间的相似性,我们将距离函数扩展为以下形式:
\[d_{m c s}\left(G_{1}, G_{2}\right):=1-\frac{\left|m c s\left(G_{1}, G_{2}\right)\right|-\sum d_{B B}\left(b_{i}, b_{j}\right)}{\max \left(\left|G_{1}\right|,\left|G_{2}\right|\right)}\]因为图同构问题是NPC问题,所以我们需要尽可能将其复杂度降低,所以在这里我们选用McGregor算法。在展开阶段,所有图的候选节点都被检查其潜在的相似性,如果被认为相似的话会被选择。在这个阶段使用basic block distance 有两个目的:1.早期决定展开哪个候选图pair。2移除超过一定阈值的pair。
。。。。后面跳过一大段部分无关紧要的算法对比,参数选择等部分。
EVALUATION
A. Similarity Metric
将OpenSSL(不包括在提取特征的数据集中)编译到不同的平台、编译器、优化选项中,得到了593 binaries with 1,293 sufficiently large functions。定义$f_n^{c,a}$为OpenSSL编译到平台a,使用编译选项c下的第n个函数。
给定一个函数n,通过以下来测试discovRE的匹配能力:
(1)随机选择要搜寻的目标函数$f_n^{c1,a1}$
(2)随机选择一个匹配的函数$f_n^{c2,a2}$
(3)随机选择一个有99,999个函数的集合$F$
(4)构建代码库$C=F \cup\left\lbrace f_{n}^{c 2, a 2}\right\rbrace$,$(|C|=100,000)$
结果如下:
 仅使用Numeric Filter时,返回的f2基本在前5.5个返回,当添加了图匹配后,总是第一个返回。
仅使用Numeric Filter时,返回的f2基本在前5.5个返回,当添加了图匹配后,总是第一个返回。