请咨询作者同意后转载。
FirmUp: Precise Static Detection of Common Vulnerabilities in Firmware
|期刊/会议: |ASPLOS (A类)| | —|—| |发表时间:|2018年3月| |发表机构:|Technion - Israel Institute of Technology|
一.前言
问题定义:给定程序集F={T1, T2, …, Tn} 和一个查询程序Q, Q中包含一个(有漏洞的)函数q,我们的目标是判断 Ti (∈ F) 是否包含一个与q相似的函数。
本文的方法基于以下几个想法: Representing procedures using canonical fragments: Strands是基本块的数据流切片,作者在其之前的方法上提升了基于Strand的表示方法。
Using the information in the surrounding executable:拓宽了相似性检测的范围,其不仅使用程序自身,还利用相邻的程序(在同一可执行文件下的其他程序)
Efficiently matching procedures in the context of exe cutables: 为了利用可执行文件的上下文来寻找程序的相似性,我们不仅需要对$q_{v} \in Q$和$t \in T$进行匹配,还要对其周围的程序Q和T匹配。但是进行全匹配的代价太大了,所以作者使用了一种算法来进行聚焦于Query的部分匹配。
二.方法概述
2.1 Pairwise Procedure Similarity
The syntactic gap:
 上图为MIPS平台下不同的两个代码块代码,尽管其在语法上不太相同,但是却有很多相同的语义信息:
上图为MIPS平台下不同的两个代码块代码,尽管其在语法上不太相同,但是却有很多相同的语义信息:
- 都从栈中恢复一个值。(左5,右1)
- 都以0x1F作为跳转条件(左4,右5)
- 都调用了一个程序(左1,右3)
虽然在语义上不是等价的,但这些过程具有很大的相似性,但由于指令选择、排序和寄存器使用的差异,发现这种相似性是困难的。
Capturing semantic similarity:为了能够从不同的优化选项中寻找相似性,使用文献Similarity of binaries through re-optimization中的方法进行表示。
2.2 Efficient Partial Executable Matching
Similarity in the scope of a single procedure is inaccurate 即使程序级别的相似性可以实现不错的精准率,但是在一些场景下使用由可执行文件提供的额外信息可以有效的减少错匹配个数。
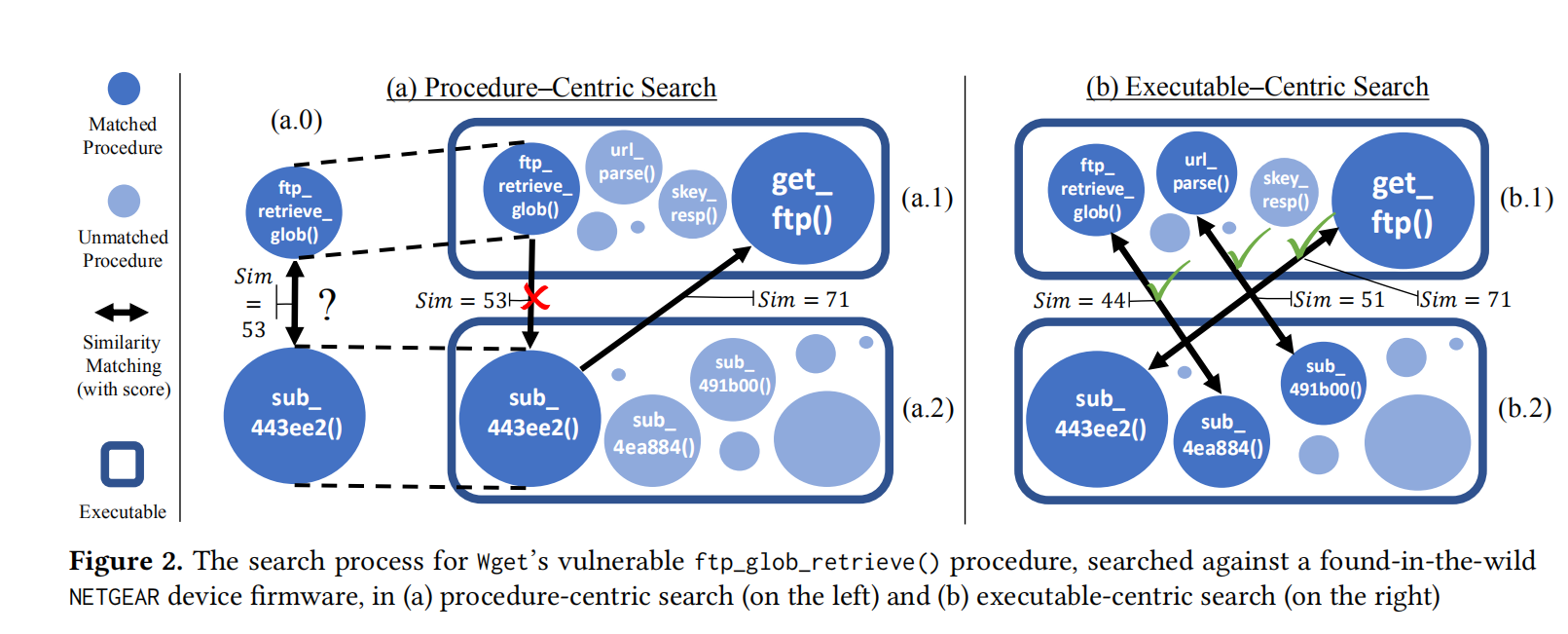 如上图所示,左边为程序级别的相似性检测,仅使用query functin ftp_retrieve_glob在目标程序中进行检测,寻找与其相似性最高的函数。但是找到的匹配却是错误的,此找到的函数与 get_ftp才是真正的匹配。
如上图所示,左边为程序级别的相似性检测,仅使用query functin ftp_retrieve_glob在目标程序中进行检测,寻找与其相似性最高的函数。但是找到的匹配却是错误的,此找到的函数与 get_ftp才是真正的匹配。
右边为利用了可执行文件信息的文件级别的相似性检测,能够发现错误的匹配,寻找出最可靠的匹配。
Procedure similarity in the scope of an executable using back-and-forth games:上图阐述了从程序级别到可执行文件级别相似性度量的转变,其结果是由back-and-forth game算法实现的。其建立和扩展了一个更加恰当的部分匹配,而且仅由必须包含query程序这个需求限制。
Outlining a matching from a two-player game:通过一个游戏来介绍匹配规则。有两个角色:player和rival。每当player找到一个匹配pair$(q_v,t_1)$时,rival就根据t_1在Query文件中寻找t_1的匹配,如果找到的匹配相似性分数比$q_v$大,play而就要重新找新的匹配。
三.Representing Firmware Binaries
3.1 Binary Lifting
From bits to intermediate representation (IR):使用Angr.io和IDA来生成中间表示。
3.2 Procedure Decomposition
Procedures to strands:我们最开始将程序分解到BB级别,但是一个BB中可能包含不同的执行序列,它们是因为编译器编译到了一起。所以我们需要通过切片进而将BB分解到独立的执行单元。
算法如下(意思大概就是,从BB后往前遍历,只要有与输出有关的指令就加入到strands中。其实就是数据流分析):

3.2.1 Optimizing and Normalizing Strands
Offset elimination:第一步:移除与具体二进制文件结构有关的偏移值。
Register folding:即使一个程序的返回值被存储在一个寄存器中,返回的值一定先要在程序中生成,这样才能被捕捉到Strand中。
Compiler optimization:使用LLVM优化器应用在 offset elimination step后,这可以VEX-IR过渡到LLVM-IR。每个strand被变换到LLVM-IR函数。这样统一的形式对我们寻找相似性很有用。
Variable name normalization:根据每个变量出现的顺序对其重命名
例子:

3.3 Pairwise Procedure Similarity
给定pair$(q,t)$,其中$q_{v} \in Q$,$t \in T$,我们定义程序相似性如下:
\[\operatorname{Sim}(q, t)=|\operatorname{Strands}(q) \cap \operatorname{Strands}(t)|\]为了加快计算Sim, keep the procedure representation as a set of hashed strands。
四.Binary Similarity as a Back-and-Forth Game
4.1 Game Motivation
Procedure-centric matching is insufficient :函数变成了strand集合的形式,来说明程序级别的不准确性。
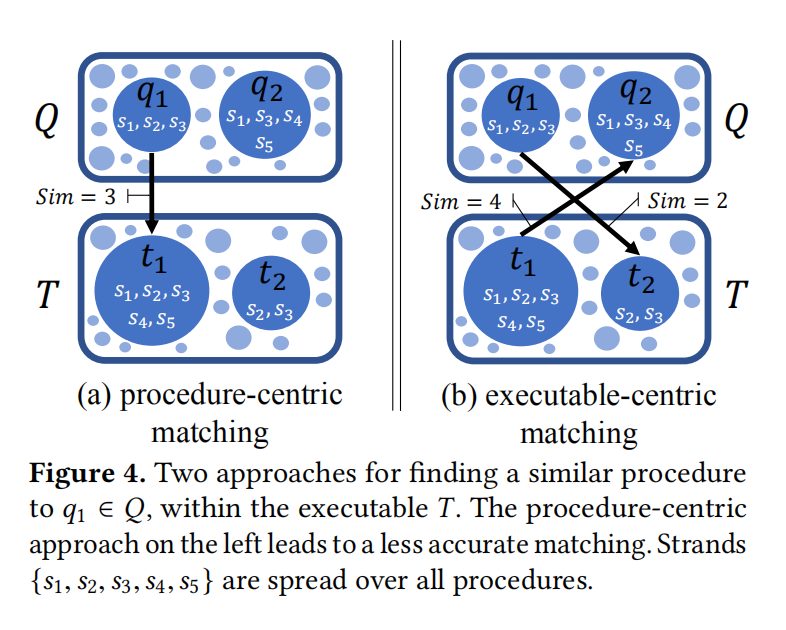
Knowledge in surrounding executable leads to better matching:省略吧。。还是这个意思。
4.2 Game Algorithm
之前只是介绍了Game算法的策略与作用,所以这里介绍具体的实现:
 看不懂的话,看论文会很好懂。
看不懂的话,看论文会很好懂。
4.3 Graph-based Approaches
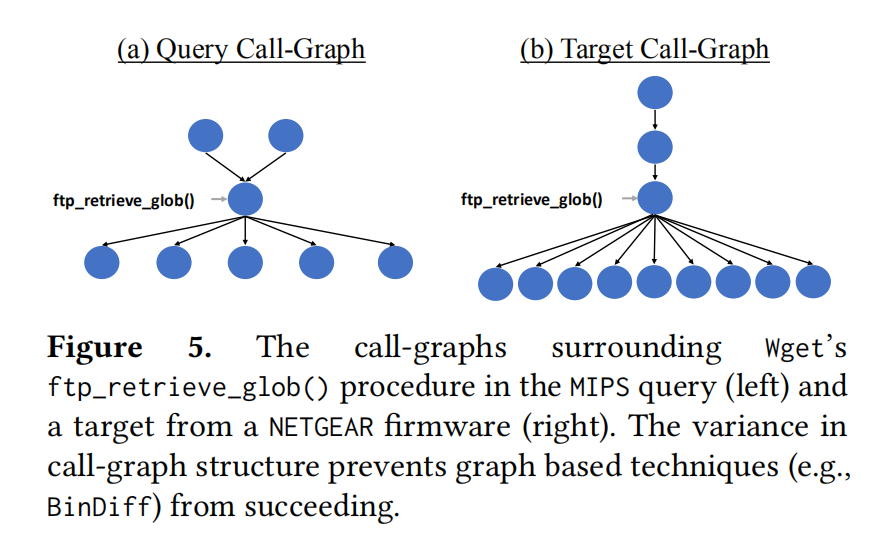
举了个例子,论证基于图方法,可能会出现的问题。