请咨询作者同意后转载。
Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs(INNEREYE)
数据集,模型,评估结果:https://nmt4binaries.github.io
| 期刊/会议: | NDSS(B类) |
|---|---|
| 发表时间: | 2018年12月 |
| 发表机构: | South Carolina&Temple University |
前言
以不同的观点来看待跨平台二进制代码相似性检测问题,指出以前的方法都是以函数级别来进行检测的,不能任意挑一代码段进行检测。
为此,作者将跨平台二进制代码相似性检测问题分解为两个问题:
Problem Ⅰ:给一对不同指令集平台下的二进制基本块,判断其语义是否相似。
Problem Ⅱ:给定关键代码的片段,看它是包含在不同指令集的其他片段中出现。
方法概述
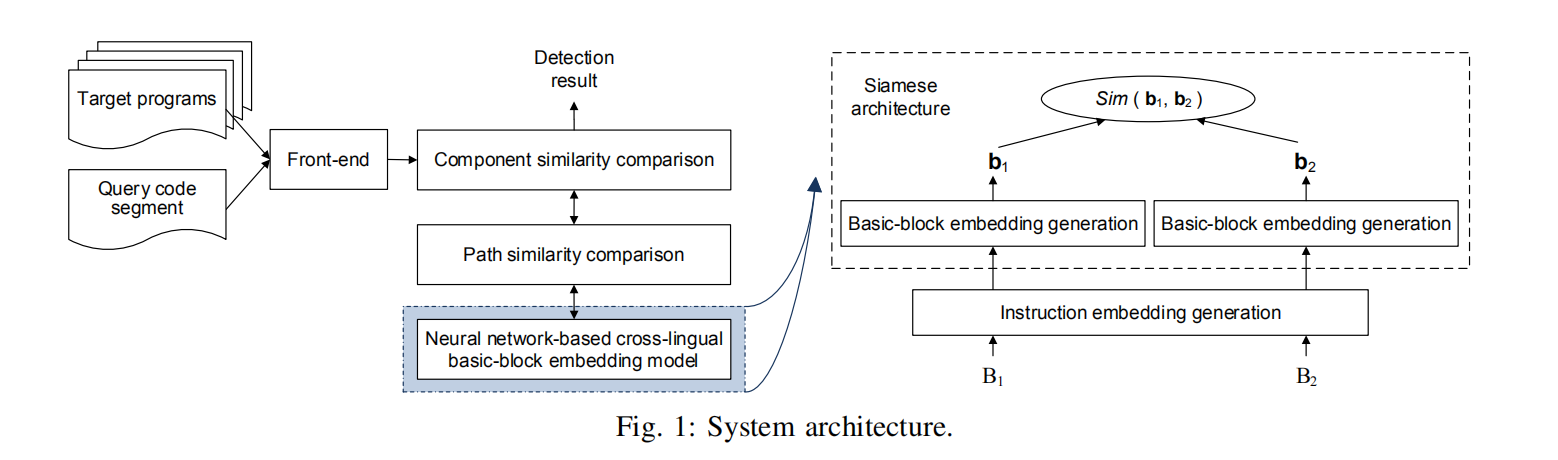 如上图,分别在三层分析语义信息:基本块、CFG路径、代码。
如上图,分别在三层分析语义信息:基本块、CFG路径、代码。
模型的输入: 要查询的代码段和被查询的程序集合。
Front-end: 反汇编二进制程序和构建控制流图
basic block embedding模块: Neural network-baseed cross-lingual model 来对每个basic block进行embedding,所有的embedding存在LSH数据库中。其中embedding分为 instruction embedding and a block embedding两个层次。
Path Similarity comparison: 利用LCS (Longest Common Subsequence)算法来比较两条Path的语义相似性。
Componet similarity comparison: 探索多条路径所共同计算出的相似性得分。
相似性检测模块: 利用LSTM和Siamese生成相似性分数(0-1),越接近1越相似。
Instruction Embedding Generation
提出了在进行Instruction embedding时面临的挑战:在机器翻译中,我们只需要使用大规模的语料训练一次就可以得到词嵌入,然后直接被其他人用。但是在这里,我们必须自己训练一个instruction embedding。还有像常量、字符串之类缺失词的嵌入生成。
定义block级别的指令流,其中$b_i$为基本块$\mathrm B$中指令的: \(\pi(\mathrm{B})=\left(b_{1}, \cdots, b_{n}\right)\) 预处理训练数据: 为了解决缺失词的问题,对训练数据做如下处理:
(1) 负号保留,但数字常量全替换成0
(2)字符串替换成<STR>
(3)函数名替换成<FOO>
(4)其他符号常量全替换成<TAG>
然后使用word2vec里的skip-gram练词向量。
Block embedding Generation
因为指令在不同的平台下具有不同的embedding,所以我们不同对其简单的累加获得block embedding。
为此搭建了如下的LSTM+Siamese网络来学习block embedding。
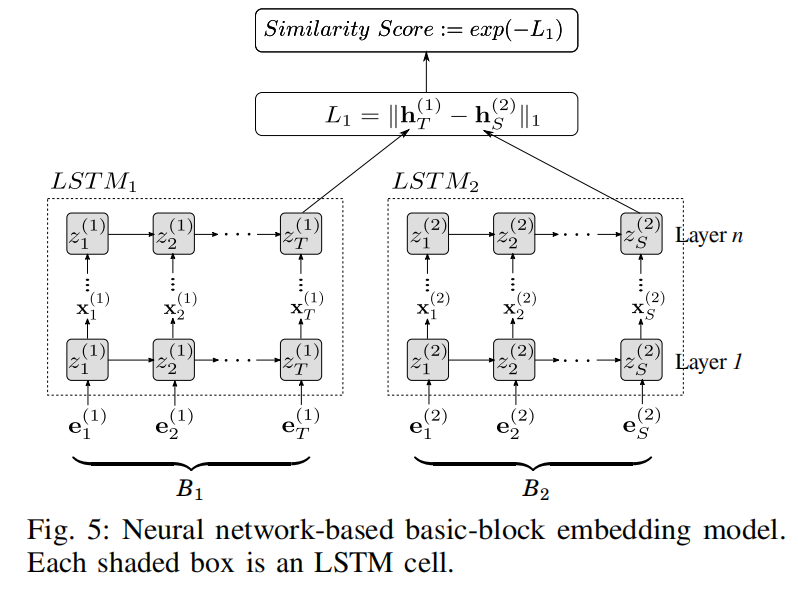 其中Siamese的网络输入为两个基本块$\mathrm B_1和\mathrm B_2$的instruction的embedding,而LSTM网络可以通过instruction embedding学习到block embedding。
其中Siamese的网络输入为两个基本块$\mathrm B_1和\mathrm B_2$的instruction的embedding,而LSTM网络可以通过instruction embedding学习到block embedding。
其中Siamese网络的损失函数为平方损失: \(\min _{\mathbf{W}_{i}, \mathbf{W}_{f}, \ldots, \mathbf{v}_{o}} \sum_{i=1}^{N}\left(y_{i}-\operatorname{Sim}\left(\mathrm{B}_{1}^{i}, \mathrm{B}_{2}^{i}\right)\right)^{2}\)
但其中存在的困难如下: Siamese网络需要大量的训练数据对,但不同于Genimi所采用的针对函数级别做标签,这里要对被个基本块做标签。其难度体现为如下:1.没有可以暗示是否相似的基本块命名可以使用。2.即使两个基本块有两段代码编译而成,它们也可能相似或者不相似。
数据集生成
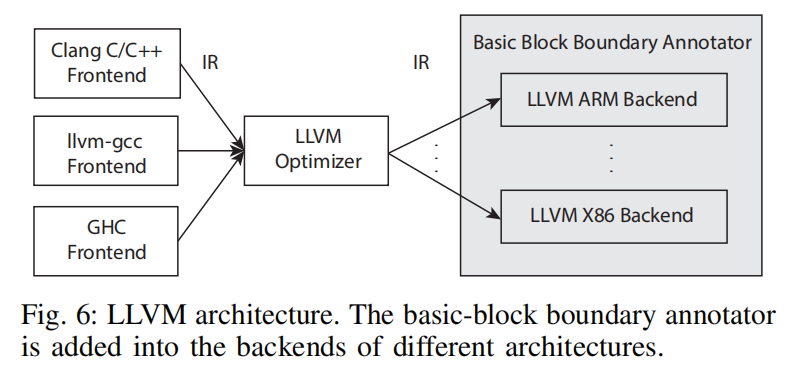 如上图所示,LLVM由左边front-end和右边backend组成,front-end会生成统一的中间表示,所以我们修改每个backend增加每个基本块的边界注释器,并添加唯一的标识ID,由相同IR编译生成的基本块获得相同的ID。
如上图所示,LLVM由左边front-end和右边backend组成,front-end会生成统一的中间表示,所以我们修改每个backend增加每个基本块的边界注释器,并添加唯一的标识ID,由相同IR编译生成的基本块获得相同的ID。
尽管相同的ID总是语义相同,但是不同的ID并不一定语义不同。 为了解决这个问题,使用N-gram来判断两个由不同代码编译所得的基本块的相似度。实验中采用n=4,0.5为threshold。
Path/Code Component Similarity Comparison
将CFG分解成许多的路径,在于目标程序的路径 利用LCS进行比较相似性分数。
线性独立路径: 至少增加一个不包括在其他线性独立路径中的节点。一旦 $Q$和目标$T$的起始block是一样的,那么我们就可以用DFS算法来寻找线性独立路径的集合。
定义:PATH相似性分数:
给定一Query代码段的线性独立路径$P$,目标程序$T$的所有线性独立路径$\Gamma=\left\lbrace \mathcal{P}_ {1}^{t}, \ldots, \mathcal{P}_ {n}^{t}\right\rbrace $。令$\left[\mathrm{LCS}\left(\mathcal{P}, \mathcal{P}_{i}^{t}\right)\right]$为$Q在\Gamma$中具有最大语义相似路径的LCS的个数。路径$P$的path相似性分数定义如下: \(\psi(\mathcal{P}, T)=\frac{\max _ {\mathcal{P}_ {i}^{t} \in \Gamma}\left|\operatorname{LCS}\left(\mathcal{P}, \mathcal{P}_{i}^{t}\right)\right|}{|\mathcal{P}|}\)
Component Similarity Comparison
在这方面遇到的挑战是:如何正确的在target program中找到Query的起始block。 解决:
- 首先所有基本块的embedding都存在LSH数据库中供我们查询。
- 我们从Query代码段的第一个基本块开始,在数据库中寻找target program中的语义相等基本块。
- 如果我们找到一个或多个语义相等基本块,我们就从此基本块开始发现路径。否则我们选择Query的第二个基本块作为起始块。
Component similarity score: 根据选择出的线性独立路径计算出相似性分数,并根据每个路径的query path的长度分配一个权重,最后的得分就是加权平均分。
实验评估
实验设置
Dataset Ⅰ:evaluate the cross-lingual basic-block embedding model。
数据源使用Openssl等软件,并使用不同的平台、编译器、优化选项编译得来。具有标签。

Instruction embedding 的定量分析:使用t-SNE对x86和ARM平台下的embedding做了可视化,结果显示有相同平台编译得到的embedding聚在一起。

并且还进一步分析发现,相似的指令也聚类到了一起。

Accuracy of INNEREYE-BB :使用DatasetⅠ来进行评估。并且与Gemini手动提取的特征作为对比,并使用SVM分类器进行分类,结果显示此方法提取特征的准确率更高,手动提取特征可能导致大量的语义信息丢失。
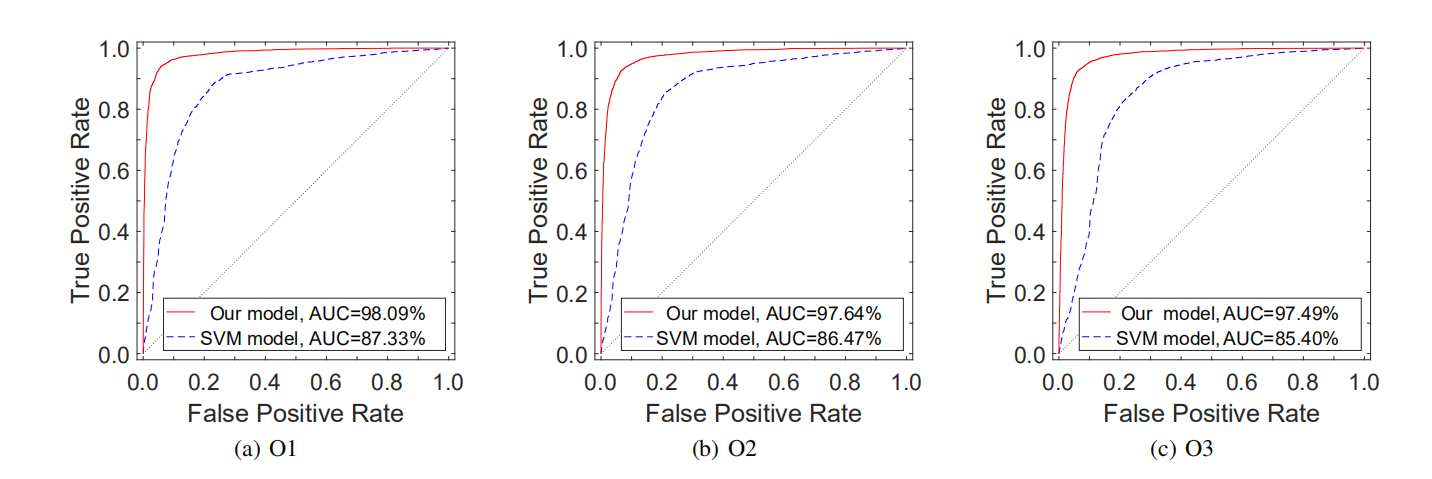
Efficiency of INNEREYE-BB:使用具有6,199,651个指令的数据集Ⅰ做Instruction Embedding,可以看出花费时间很短。

Code Component Similarity Comparison: