请咨询作者同意后转载。
Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection
https://keenlab.tencent.com/zh/2019/12/10/Tencent-Keen-Security-Lab-Order-Matters/
| 期刊/会议: | AAAI(A类) |
|---|---|
| 发表时间: | 2019年12月 |
| 发表机构: | 腾讯科恩&AI实验室 |
前言
总结了Genimi方法的不足之处:
- 每个CFG块的特征是手工选择的,会造成大量的语义信息丢失
- 节点之间的次序在表示二进制函数上也起了关键性的作用,然而之前的方法都没有考虑
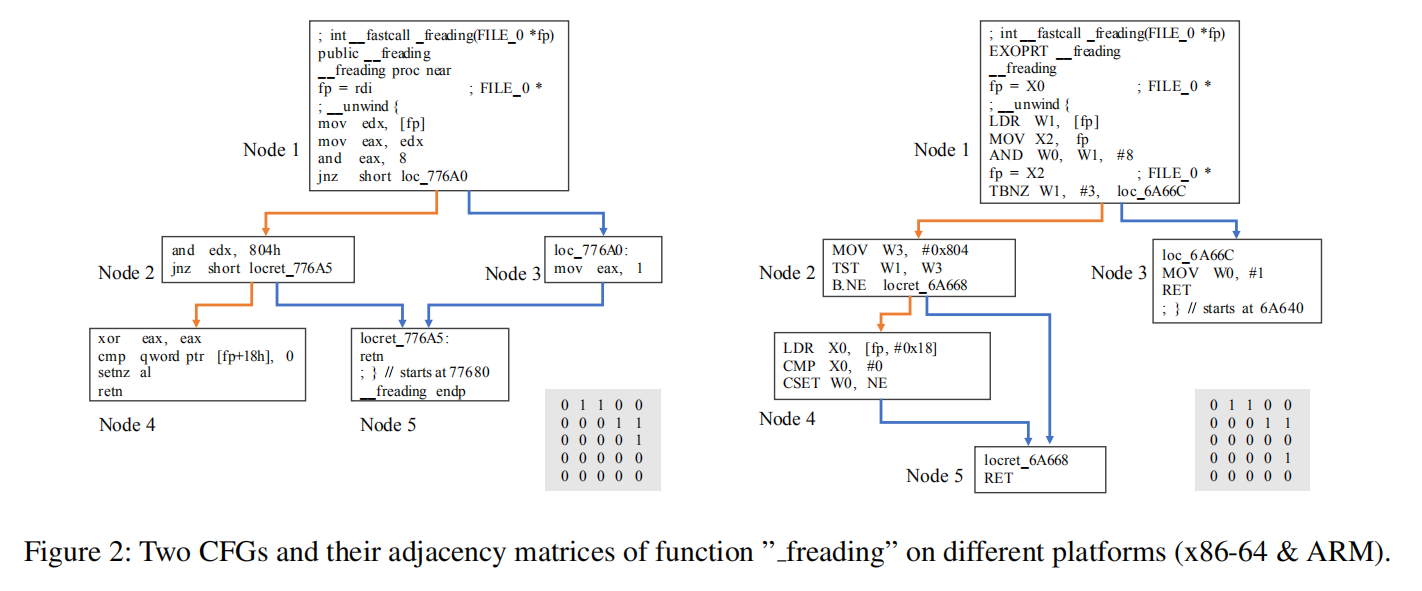
图2是函数“_freading”在不同平台x86-64和ARM上编译出的二进制代码的控制流图。这两个控制流图的节点顺序是非常相似的,例如node1都与node2和node3相连,node2都与node4和node5相连,而这种相似性可以体现在它们的邻接矩阵上。经过观察,我们发现许多控制流图的节点顺序变化是很小的。 为了解决这两个问题,提出了框架:语义感知模型、结构感知模型、次序感知模型。
方法实现
概述
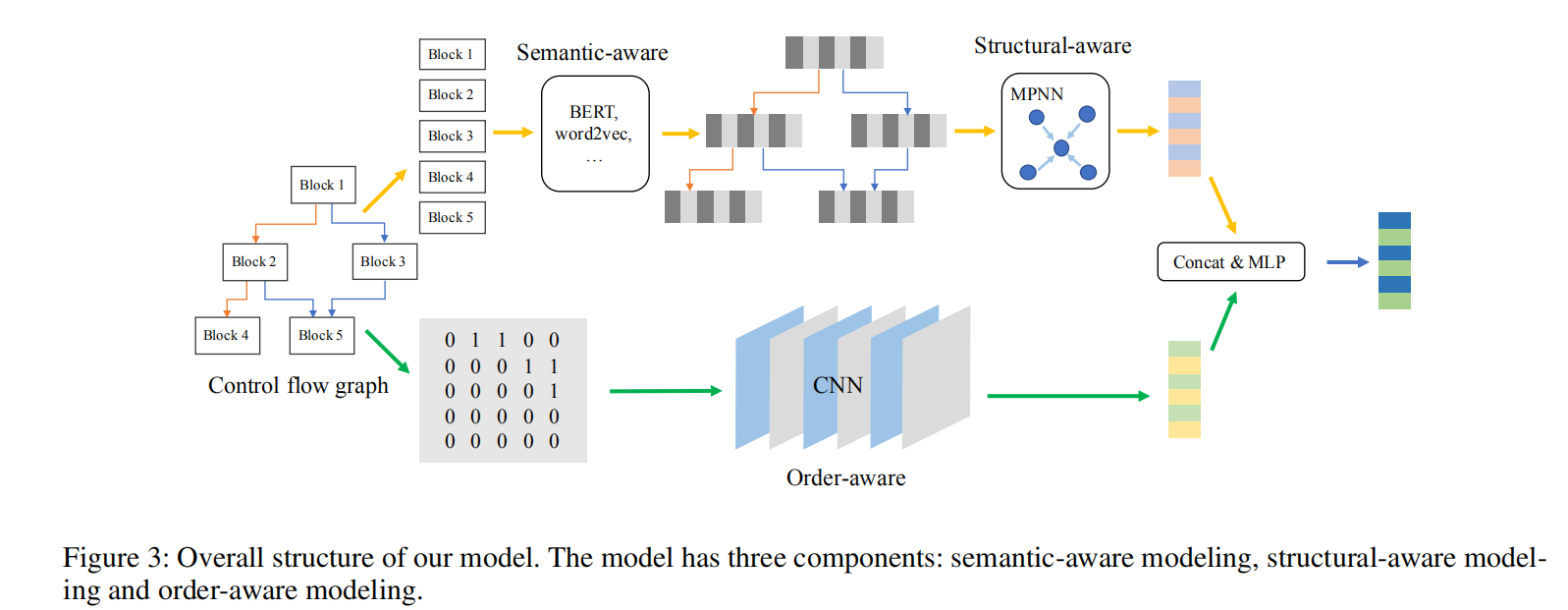 如上图所示,采取二进制函数的控制流图作为输入,其中每个基本块都为具有中间表示的token序列。
在语义感知模块,模型采取控制流图的基本块作为输入,使用BERT对token embeddings进行预训练,输出block embeddings。
在结构感知模块,使用MPNN和GRU更新函数来计算得到图的语义和结构嵌入$g_{ss}$。
在次序感知模块,模型采取CFG的邻接矩阵作为输入,并使用CNN来计算图的次序嵌入$g_o$。
最后将$g_{ss}$和$g_o$连接起来,并使用多层感知机来计算得到最后的图嵌入$g_{final}$
如上图所示,采取二进制函数的控制流图作为输入,其中每个基本块都为具有中间表示的token序列。
在语义感知模块,模型采取控制流图的基本块作为输入,使用BERT对token embeddings进行预训练,输出block embeddings。
在结构感知模块,使用MPNN和GRU更新函数来计算得到图的语义和结构嵌入$g_{ss}$。
在次序感知模块,模型采取CFG的邻接矩阵作为输入,并使用CNN来计算图的次序嵌入$g_o$。
最后将$g_{ss}$和$g_o$连接起来,并使用多层感知机来计算得到最后的图嵌入$g_{final}$
语义感知模型
使用BERT预训练4种任务来处理CFGs。优点如下: 1.我们可以基于相同的模型从由不同平台、架构、编译选项的CFGs中提取block embeddings。
- 我们可以通过预训练得到token-level,block-level和graph-level的信息。因为我们有1个token-level的任务,一个block-level的任务和两个 graph-level的任务。
- 训练过程完全基于CFG,不需要对编译器进行修改或其他的操作来获得相似的block pair。
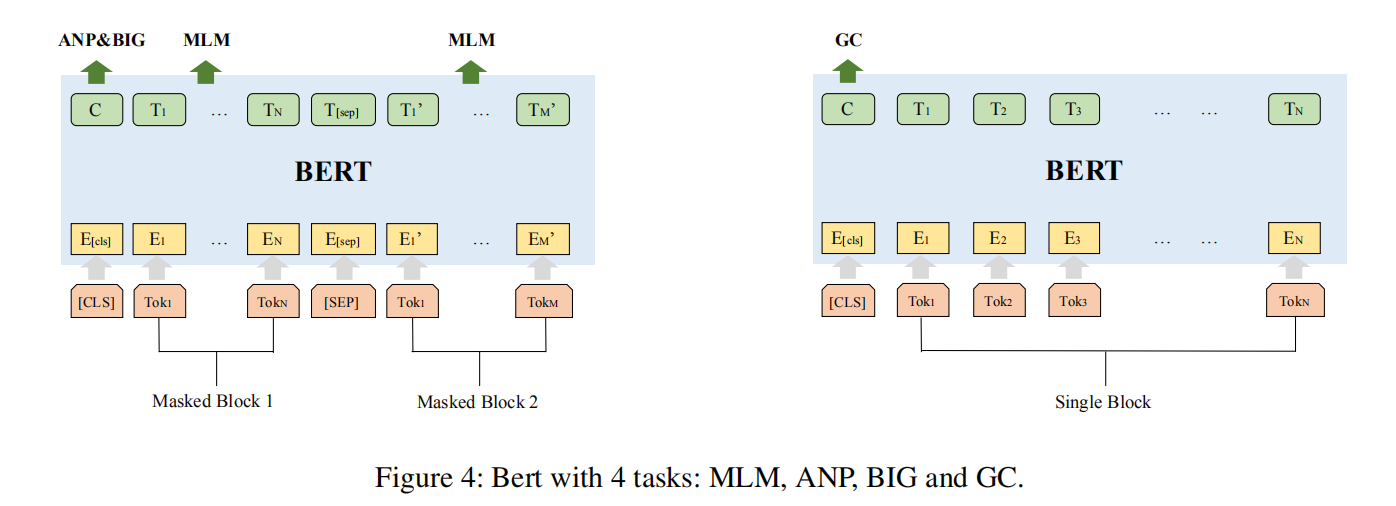 如图4所示,在预训练的过程中有4个不同的训练任务。
MLM和ANP与BERT论文中的MLM和NSP任务相似,MLM是token级别的任务 ,MLM将token中的一部分mask,根据上下文来预测出masked的token,可以学习到block内的语义信息。ANP是block级别的任务,因为在图中一个基本块不仅依赖于自己还依赖于邻居节点的信息,ANP将所有邻接的block pair和随机选取的非邻接block pair作为输入,来预测block之间的邻接关系。
如图4所示,在预训练的过程中有4个不同的训练任务。
MLM和ANP与BERT论文中的MLM和NSP任务相似,MLM是token级别的任务 ,MLM将token中的一部分mask,根据上下文来预测出masked的token,可以学习到block内的语义信息。ANP是block级别的任务,因为在图中一个基本块不仅依赖于自己还依赖于邻居节点的信息,ANP将所有邻接的block pair和随机选取的非邻接block pair作为输入,来预测block之间的邻接关系。
BIG和GC是除了BERT里的任务外新增加的两个基于graph级别的任务。BIG 通过随机选取两个不同的block,来学习这两个不同的block是否在同一graph中,这可以帮助模型来理解block和graph之间的关系,这对获得图嵌入很有用。GC 被设计用来区分block和graph是哪一类的平台、架构、编译选项。
结构感知模块
经过BERT预训练后,使用MPNN计算控制流图的graph semantic & structural embedding。MPNN有三个步骤:message function(M),update function(U)以及readout function(R)。具体步骤如公式2-公式4所示。
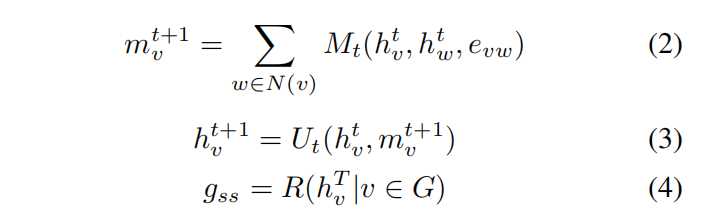 其中G代表整个graph,v表示节点,$N(v)$表示节点v的邻居节点。在本文的场景中,节点即是控制流图中的block,图即是经过预训练后表示成block向量的控制流图。本文在message步骤使用MLP,update步骤使用GRU,readout步骤使用sum,如公式5-公式7所示。
其中G代表整个graph,v表示节点,$N(v)$表示节点v的邻居节点。在本文的场景中,节点即是控制流图中的block,图即是经过预训练后表示成block向量的控制流图。本文在message步骤使用MLP,update步骤使用GRU,readout步骤使用sum,如公式5-公式7所示。
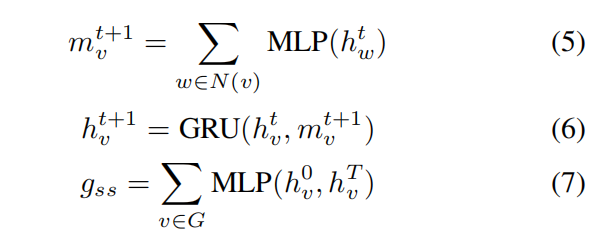
次序感知模块
本模块希望可以提取节点顺序的信息,本文中使用的是CNN模型。为什么使用CNN模型呢?
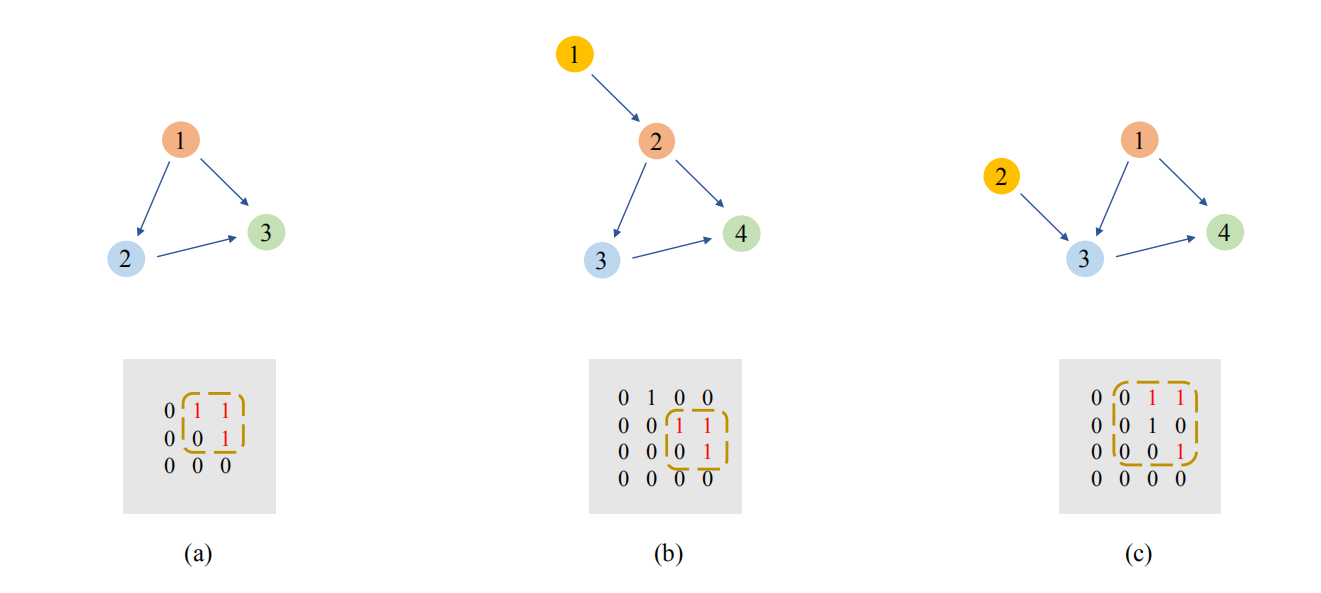 首先考虑图6中的三个图(节点中无语义信息),以及它们的邻接矩阵。这三个图非常相似,每个图中都有一个三角形特征(图a的节点123,图b的节点234,图c的节点134),这个特征体现在它们的邻接矩阵中。首先对比图a和图b,与图a相比,图b加入了节点1,节点顺序依次后移一位,但三角形特征中三个节点的顺序还是连续的,这个特征在邻接矩阵中可以看到,这个1-1-0-1的2*2矩阵仍然存在。CNN在训练集中看过很多这种样例后,可以学习到这种平移不变性。再看图c,加入了节点2,打破了原有三角形的节点顺序,但在邻接矩阵中我们可以看到它实际上是把原来的2*2矩阵放大成了3*3矩阵,当我们移除第二行和第二列时,仍然可以得到一个1-1-0-1的2*2矩阵。这与图像中的image scaling类似,CNN在训练集中包含足够多样例的情况下,也是可以学到这种伸缩不变性的。
首先考虑图6中的三个图(节点中无语义信息),以及它们的邻接矩阵。这三个图非常相似,每个图中都有一个三角形特征(图a的节点123,图b的节点234,图c的节点134),这个特征体现在它们的邻接矩阵中。首先对比图a和图b,与图a相比,图b加入了节点1,节点顺序依次后移一位,但三角形特征中三个节点的顺序还是连续的,这个特征在邻接矩阵中可以看到,这个1-1-0-1的2*2矩阵仍然存在。CNN在训练集中看过很多这种样例后,可以学习到这种平移不变性。再看图c,加入了节点2,打破了原有三角形的节点顺序,但在邻接矩阵中我们可以看到它实际上是把原来的2*2矩阵放大成了3*3矩阵,当我们移除第二行和第二列时,仍然可以得到一个1-1-0-1的2*2矩阵。这与图像中的image scaling类似,CNN在训练集中包含足够多样例的情况下,也是可以学到这种伸缩不变性的。
因为在二进制代码相似性检测任务中,对于相同的函数编译到不同的平台上去,其控制流图的节点顺序一般不会变化很大,大多数的变化为增加一个节点、删除一个节点或者交换一些节点的顺序,所以CNN很适合用于检测二进制代码的相似性。
具体的CNN网络选择,使用Resnet,因为Resnet的短连接可以更快、更高效的进行信息流动。使用11层的具有3个残差块的Resnet,所有的特征映射都是3*3的,这样可以学习到图一些小的变化。 \(\left.g_{o}=\text { Maxpooling (Resnet }(A)\right)\)
实验
本文在两个任务上进行实验。
- 任务1为跨平台二进制代码分析,同一份源代码在不同的平台上进行编译,我们的目标是使模型对同一份源代码在不同平台上编译的两个控制流图pair的相似度得分高于不同源代码pair的相似度得分。
- 任务2为二进制代码分类,判断控制流图属于哪个优化选项。各数据集的情况如表1所示。任务1是排序问题,因此使用MRR10和Rank1作为评价指标。任务2是分类问题,因此使用准确率作为评价指标。