请咨询作者同意后转载。
VulSeeker: A Semantic Learning Based Vulnerability Seeker for Cross-Platform Binary
VulSeeker is available at https://github.com/buptsseGJ/VulSeeker The video is presented at https://youtu.be/Mw0mr84gpI8.
| 期刊/会议: | ASE(A类) |
|---|---|
| 发表时间: | 2018年9月 |
| 发表机构: | Tsinghua University |
前言
VulSeeker通过带标签的语义流图(LSFG)和基于函数的语义可知DNN实现了更高的准确率和性能。语义可知DNN模型将函数内基本块的数字特征转化为函数的语义特征(或者说是embedding vector),通过比较embedding vector之间的的余弦相似度来识别漏洞。
与之前方法的主要差别: Vulseeker是第一个通过合并CFG和DFG来形成LSFG的工具,并应用深度学习来进行跨平台漏洞搜索。它它从LSFG的每个基本块中提取8种类型的轻量级的指令特征。基于图拓扑结构和修正的语义可知DNN模型,我们对LSFG应用6次迭代来获得整个二进制函数的语义表示,从而获得更高的准确率。
VulSeeker设计
整个VulSeeker的工作流图如下,它主要包含4个模块:LSFG 构建、Block 特征提取、基于DNN的函数语义生成、相似性计算

VulSeeker的目标 是:给定目标二进制程序,判定其是否具有已知的漏洞。因此,此模型的两个输入为来自目标二进制程序和漏洞库的两个二进制函数。
首先,VulSeeker为两个二进制函数构建LSFGs,然后提取8种类型的轻量级指令特征,并且将LSFG中的每个基本块编码为数字向量。函数的语义信息通过将数字向量feed DNN从而得到。最后基于输入两个函数的相似性来判断是否包含漏洞。
LSFG构建
LSFGs构建的方法如下: 先使用IDAPython基于IDA pro来提取出CFG,并将CFG的每个控制依赖边标记为0,基于CFG再利用IDA Pro的插件LLVM IR来 推断两个基本块之间 是否应当有一条数据指向边(data pointing edge)。
数据指向边的一个例子如下:如果指令i和j来自于CFG的两个不同basic block,并且指令i写了一个内存地址,指令j读了一个相同的内存地址,那么我们就可以为这两个数据块标记一条数据依赖边,其被标记为1.
另外,只有不同basic block之间的数据依赖会被保留,并且两个basic block之间最多存在一条数据依赖边。
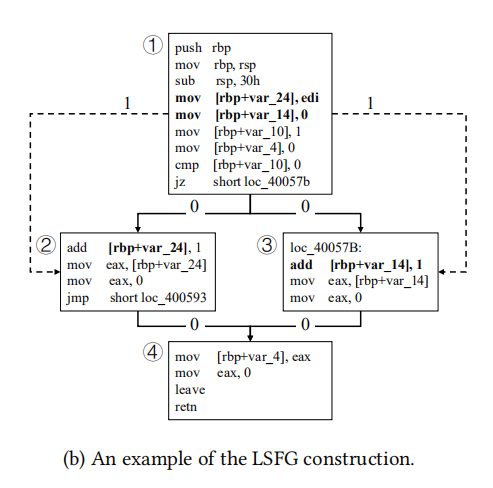
因为LSFG既考虑了程序的控制结构,也考虑了函数内的数据流动,所以其可以有效的缓解不同平台下对CFG的变化扰动。
block feature 提取
根据过去工作中使用的特征和在经过了一系列的对不同特征及合的代码克隆实验后,最终确定使用表1中的8类特征来作为每个basic block的语义表征。这些被选择的轻量级特征时比较健壮的,在不同的平台、处理器架构、编译优化配置上变动很小,并且可以容易地被提取。
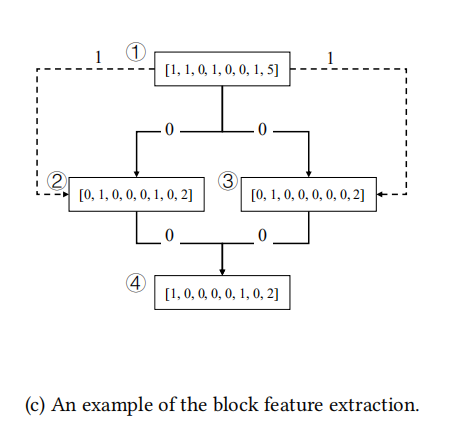
利用IDAPython可以提取出如上的特征,然后将每个基本块的8个特征编码为数字向量,
对图(b)的一个block feature的例子如下:
Function Semantics Generation
此模块的输入为函数内所有基本块的初始d维数字向量,输出为p维的函数表征嵌入向量。
为了能够精确地捕捉函数语义信息,LSFG拓扑中的数据依赖和控制依赖都需要考虑到。为此,根据structure2vec神经网络,作者提出了图2所示的感知模型,专门用来处理结构化的LSFG表征。
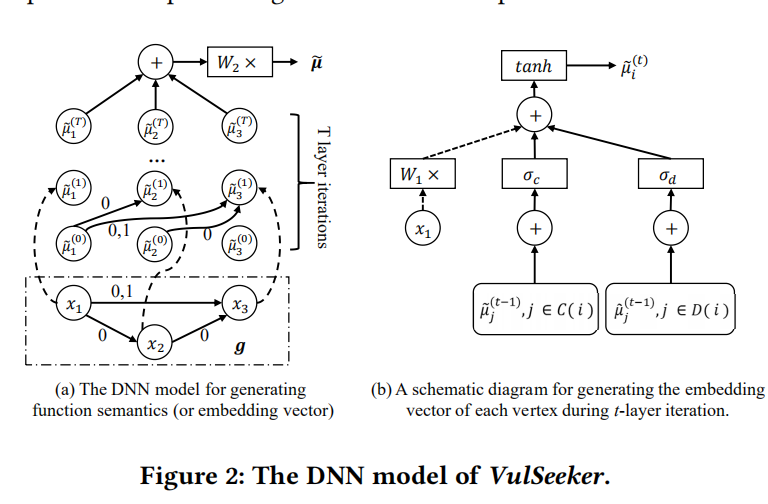
图2(a)中,LSFG被表示为$g=<V,E>$,包含了3个节点,其初始向量分别为:$x_1,x_2,x_3$。Edges被标记为0和1分别代表数据依赖和控制依赖。DNN模型总共包含T层的迭代,并且每一层迭代都将每个节点i的输出向量$x_i$转换成其嵌入向量$\widetilde{\mu}_{i}^{(t)}$.
在获得了函数内所有basic block节点的嵌入向量后,将它们全部累加后乘以$p \times p$维参数矩阵$W_2$后得到$p$维的嵌入向量$\widetilde{\mu}$。其计算的具体公式如下: \(\widetilde{\mu}=W_{2}\left(\Sigma_{i \in V} \widetilde{\mu}_{i}^{(T)}\right)\)
图2(b)展示了在第t-层迭代中每个节点i的嵌入向量$\widetilde{\mu}_{i}^{(t)}$的生成过程示意图。这个转换过程的输入有三个不同的部分组成:节点i的初始向量$x_i$(图中的虚线箭头)、通过控制依赖指向节点i的之前的节点嵌入向量之和(由$C(i)$表示)、和通过数据依赖指向节点i的先前节点的嵌入向量之和(由$D(i)$表示)。
这里也许值得注意下,在实现的过程中structure2vec的邻居使用的是入度邻居,那为什么不能用出度邻居呢?
其中节点i的嵌入向量通过如下公式计算:
\(\widetilde{\mu}_ {i}^{(t)}=\tanh \left(W_{1} x_{i}+\sigma_{c}\left(\Sigma_{j \in C(i)} \widetilde{\mu}_ {j}^{(t-1)}\right)+\sigma_{d}\left(\Sigma_{j \in D(i)} \widetilde{\mu}_{j}^{(t-1)}\right)\right)\)
其中$W_1$为$d \times p$维参数矩阵,$\sigma_c和\sigma_d$是两个n层全连接网络来计算具有更强表征能力的嵌入向量,其网络结构如下:
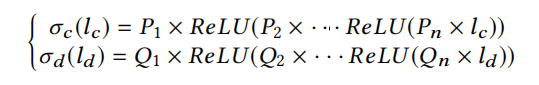 其中n为每个节点的embedding深度,$P_i和Q_i$为$p \times p$维的参数矩阵。
其中n为每个节点的embedding深度,$P_i和Q_i$为$p \times p$维的参数矩阵。
在经过了T层的迭代后,每个节点的features都被传播到其他的节点,来保证每个基本块都具有其对应上下文的语义信息。
相似度计算
一旦我们获得了目标函数和漏洞函数的embedding vector $\widetilde{\mu}$和$\widetilde{v}$后,我们可以直接计算器余弦相似度: \(\widehat{y}=\cos (\widetilde{\mu}, \widetilde{v})=\frac{\tilde{\mu} \cdot \tilde{v}}{\|\tilde{\mu}\|\|\tilde{v}\|}\) 并设置一个阈值来判定是否相似。
实验结果
数据集
Dataset I: compile BusyBox (v1.21.0),OpenSSL (v1.0.1f and v1.0.1u) and Coreutils (v6.5 and v6.7) in X86,X64, MIPS32, MIPS64, ARM32, ARM64 architectures, using GCC(v4.9 and v5.5) with optimization levels O0-O3。共包含735540个函数,9345K个基本块。 Dataset Ⅱ: 用的还是Genius中的4643个固件镜像。
Accuracy
和Genimi的对比,AUC值和ACC值比Genimi高 8.23% and 12.14%。原因是除了CFG还采用了DFG,和修改后的DNN图嵌入网络。

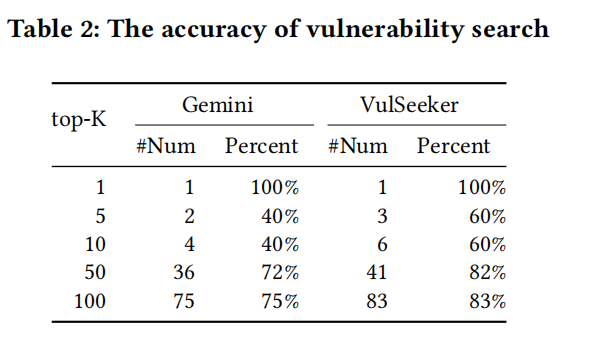
也就是说在此实验设定下,VulSeeker的AUC值为88.49%,准确率为81.3%;而Genimi的AUC值为80.26%,准确率为69.16%。造成这样的原因是因为,在Genimi文章中的实验设置过于简单,在这样简单的设定下Genimi可以达到97%AUC,Vulseeker可以达到99%AUC.
效率: Genimi对一个二进制程序进行搜索已知漏洞所需要的时间为0.15s,而VulSeeker需要0.2秒