请咨询作者同意后转载。
Similarity of Binaries through re-Optimization(GitZ)
| 期刊/会议: | PLDI(A类) |
|---|---|
| 发表时间: | 2017年6月 |
| 发表机构: | Technion, Israel |
摘要
展示了一种scalable and prrcise的方法来去除符号的二进制建立相似性指标。其通过程序片段的out-of-context re-optimization 来缓解大规模的语义比较压力,它将二进制程序分解为一些可以进行比较的片段并使用编译器的优化器将其转化为统一的、表转化的形式,这就可以是的通过简单的语法比较来寻找相似的代码片段。
前言
对于安全研究者在逆向工程一个去除符号的库文件或者可执行文件时,面临的一个挑战是如何从二进制程序中识别已知库程序。
这种情况会在定位一个新发现0day的代码漏洞上更为恶化,漏洞代码可能被嵌入在数不清的二进制程序中,被运行在不同的设备上。 例如近几年的Shellshock漏洞,其在20多年里一直没有被发现,并且其被移植到了不同版本的Unix中,例如Apple’s OSX,Ubuntu等等。这个漏洞甚至还能影响越狱后的基于ARM 的IOS 设备。这就需要研究员对所有可能的平台设备进行排查,尤其当二进被去除了符号信息后,排查任务会变得十分困难。
问题定义 :给定一个query程序q和一target程序的大语料库,目标是寻找一个量化的手段来定义q和每个$t \in T$之间的相似性分数。我们的目标是为由相同源代码得到的程序(跨平台、编译)给高分,且为了尽可能的遵循现实场景,结果都由去除符号的热进制产生,在低误报率的同时能够处理大规模数据。
同时提出了16年之前几种方法的缺陷:
(1) 不能解决去除符号,跨平台,跨编译器的场景。
(2)高误报率
(3)不具有scalable能力
(4)除了静态分析外还需要动态分析
Our Approach
Fragmenting procedures to comparable units :将二进制程序分解为“strands” - basic blocks的数据流切片,并且使用它们作为整个程序相似性比较的基本单元。
Finding strand equality through re-optimization :作者提出了一种新颖的“out-of-context re-optimization”技术,其法可以通过对strands的优化来捕捉程序语义信息。这种方法将程序转换成不同平台、编译器、优化等级的机器码。为了能够高效、精确的克服语法之间的差异性,作者通过对strands再次应用编译器的优化器,将其变成统一、标准化的形式,从而来识别语法不同但语义相同的strands,来捕捉程序的相似性。
其过程大概如Figure 1所示。
Gaining perspective with a global context: 为了实现高的准确率和低的误报率,我们识别出并降低common strands的重要性–这些strands可能来自于编码风格、语言、编译器、或平台(比如说栈处理)。我们使用一个全局的上下文来估计出每个strands的重要性–一个所有二进制程序近似的统计框架,其通过爬取包含来自”wild world”的十万个程序的数百万strands的语料建立。
方法概述
The Challenge in Establishing Binary Similarity
图1展示了作者的相似性方法在应用于两个相似性计算时是如何工作的,其程序来自OpenSSL代码包中dl_both.c的dtls1_buffer_message函数,这些计算由编译上述程序到不同的设置下所进行,使用:
- gcc version 4.8,64-bit ARM,O0优化等级
- icc version 15.0.5,x86_64,O3优化等级
图1被分为四列,第一列(i)展示了由上述便已设置得到的二进制程序片段,(ii, iii and iv)展示了此方法的后续处理步骤。
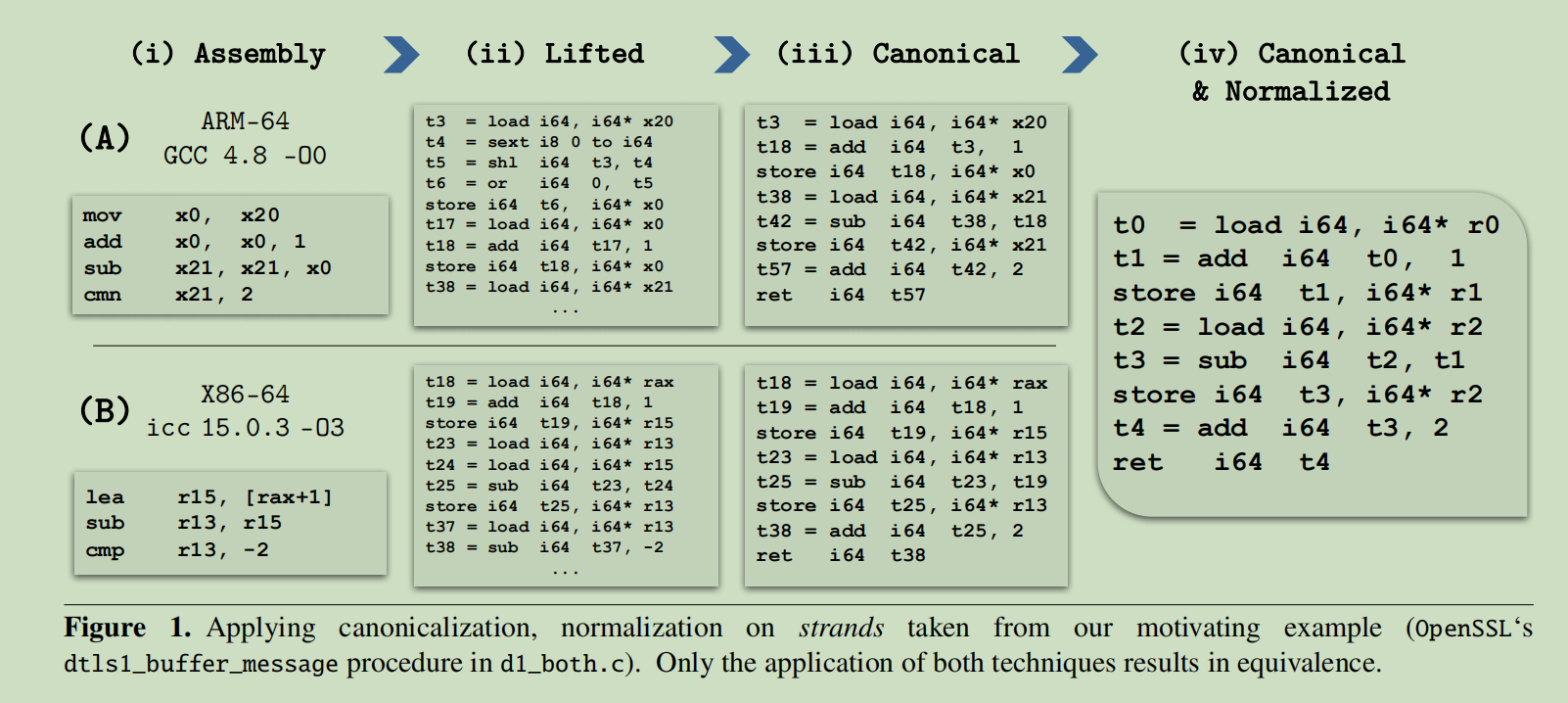
Syntactically different yet semantically equivalent code :在图1(i)中展示两个代码片段都进行了了相同的计算,但是却以不同的方法来展示,这使得比较它们语法上的不同很难。这种不同源自于不同的编译过程,在这过程中因为很多的因素导致了这些变化,这些因素包块但不限于:
Arbitary register use: 这些计算的输入被存储到不同的寄存器集合:x0,x20,x21 in (A) 和rax,r15,r13 in (B)。 编译器的寄存器选择过程是由各种启发式和复杂的代码传递细节驱动的,这就导致了相当任意的选择。在这种场景下,编译器甚至可以不遵循使用rbp作为栈帧头部。
Cross-optimization variance: 在图1中另一种语法上的差别来自于代码不同的优化设置所导致的变化。
Different instruction selection: 在图1中,这两个代码片段使用不同的比较指令:cmn in (A)和cmp in (B)。cmn 和cmp指令有着相似的语义信息,但是前者使用加而不是减来验证相等。这种改变导致比较是基于常数2而不是-2.
仅是这个小例子中的变化就导致很难对二进制代码建立相似性指标,其在不同的优化等级、编译器、平台下还会有更多的变化,作者所提出的方法就是应对这种变化。
使用被分解的、统一且标准化的形式来表征程序
Lifting binaries to intermediate representation : 我们采用一种已经存在的技术来转换二进制程序到llvm-IR的形式。这种标准的表示形式可以带来如下好处:
(1)基于LLVM-IR可以使得我们的相似性方法不必对具体架构可知。
(2)LLVM-IR的格式和配套的工具库具有很好的文档、维护和很多的创建、转换、翻译的工具可以使用。
但是目前还没有可以将不同架构的二进制代码翻译成LLVM-IR的工具可以使用,所以作者实现了一个从VEX-IR到LLVM-IR的翻译工具。
而VEX-IR是一个表征多架构下二进制代码的广泛使用且鲁棒的中间表示。 其如图1(ii)所示。
Decomposing procedures to strands: 作者基于之前的工作,使用相似分解方法将程序的基本块分解为了strands–基本块范围内的数据流依赖链。
 图2的上部分描述了一个basic block 经过icc编译的例子,下部分为从上面提取的两个strands。 一个strand 是一个basic block范围内对一个值进行计算的一系列操作指令,例如Strand 1不能存了对rbx值进行计算的指令,Strand 2保存了对比较结果 cmp r13,-2进行计算的指令。需要注意的是,指令2在两个strands中都参与了计算。Strand的提取过程的伪代码如算法1所示。
图2的上部分描述了一个basic block 经过icc编译的例子,下部分为从上面提取的两个strands。 一个strand 是一个basic block范围内对一个值进行计算的一系列操作指令,例如Strand 1不能存了对rbx值进行计算的指令,Strand 2保存了对比较结果 cmp r13,-2进行计算的指令。需要注意的是,指令2在两个strands中都参与了计算。Strand的提取过程的伪代码如算法1所示。
在我们在这个例子中测试lifter的输出时,即使对于很短的d代码片段,在我们尝试去建立相似性的时候暴露出了如下额外的挑战:
(1)在(A)中,在表达寄存器move 操作(mov x0,x20)时产生了非常复杂啊的指令集合,集合中包含了or 和移位操作。
(2)在这两个例子中都进行了冗余的load 操作,在(A)中load t39,在(B)中load t24
Canonicalizing strands: 在图1(iii)中可以看出规范化strands的好处:
(1)所有那些lifter带来的不期望的改变都得到了恢复(复杂的move操作,冗余的load操作)。
(2) 表达式被规范化,以先用常数执行加法,结果被放入减法之前的寄存器中
(3)比较被规范化到了简单的加一个正常量(而不是减去一个负数)
需要注意的是,这里的规范化步骤和对可能没有被优化过的代码进行re-optimization的作用一样。在我们的例子中进行了mov,add->add的优化。同时需要注意的还有,Intel的汇编代码被改编成了使用那些原系统架构并没有提供的指令(cmn)。
Canonicalization在图1中的代码片段中寻找相似性上是非常重要的一步,但是在寄存器选择上更大的差别将导致优化过的strands不再匹配。
Normalized form: 图1(iv)展示了我们处理过程的最后一步,标准化步骤的好处有:寄存器的具体名字变得无关紧要,并且根据其在基本块中起始位置的偏移来对其进行重新编号,而且还将那些属于冗余操作部分的临时值去除。
在最后的行驶中,两个strands就变得语法等价的了。将strands转化成由语法等价性捕捉得到的语义相似性表征,而不是使用大量的定理证明和动态分析,这允许我们的方法可以to scale。
Scalable search using hashed canonical strands: Canonicalization 和 normalization 后的程序strands可以在每个程序上进行独立的提取,在之后还可以对strands的文本表征进行hash。定义strands hash值的集合为$R(p)$,其中$p$为在比较阶段要进行表征的程序。通过比较strands的hash值,可以使我们达到更好的性能和最小化内存需求。
Determining the statistical significance of a strand : 在此方法中另一重要的部分就是使用统计框架在建立相似性的过程中来决定每个strand的相关性。其目标为:根据在源代码中出现的程序语义来区分strand的相关性,其中其他的strands是针对特定的体系结果或者特定的编译器得到的。这种统计还具有双重效应,其还可以抵消canonicalization 和normalization可能带来的overmatching。
对于两个程序q和t的相似性分数基于在q和t中出现的strands,ie..$R(q) \cup R(t)$。在统计框架中,每条strand的共同出现率以$Pr(s)$表示,在相似性分数中以倒数的形式存在。即每条strand的重要性和其在之后的相似性分数的贡献值是其概率的倒数,使得strands($Pr(s)=0$)贡献非常大的相似性权重,而常见的strand($Pr(s)=1$)的贡献非常小。
这有点类似于逆文档频率
作者使用strands s 的共同出现率来决定其重要性,在理论上的所有二进制程序的集合$\tilde W$有如重要性计算公式:
\[\operatorname{Pr}_{\bar{W}}(s)=\frac{|\lbrace p \in \widetilde{W} | s \in R(p)\rbrace |}{|\widetilde{W}|} \tag 1\]Estimating a global context through crawling binaries “in the wild”: 计算出$\tilde W$是不可能的,所以作者基于在”wild”中的有限的binaries来搭建统计框架,因此作者创建了全局上下文的估计数据集,标记为$P$。我们使用$P$来近似全局上下文$\tilde W$。$P$可以线下收集,并且作者说明了只需要相对很小数量的程序(1k)再此方法中就可以达到很高的准确率。给定$P$,计算query q和target t的相似性公式如下:
\(S_{P}(q, t)=\sum_{s \in(R(q) \cup R(t))} \frac{|P|}{f(s)} \tag 2\)
这个公式表达的意思是将存在于q和t中的每个strand的重要性(逆频率)进行求和
Algorithm
3.1 使用Canonicalized Normalized Strands的形式表征程序
Lifting opaque binary procedures to IR : 第一步使用一些工具来处理binary executables,将程序转换为一些中间表示(IR)。这一行为可以使工具的使用者来关注于二进制指令所表达的语义信息,而不是编译器的输出或者链接器的排列。有许多著名的框架可以处理此步骤,比如Mcsema ,Binary Analysis Platform(BAP),Valgrind。Mcsema使用LLVM-IR,而其他的两种方法使用各自创建的IR(BIL for BAP and VEX-IR for Valgrind)。
需要说明的是,这些框架都不是去将二进制代码进行反编译得到的,而是完全来表示二进制指令的语义。其是通过使用变量表征机器状态,根据具体的机器信息,将机器指令转换成对这些变量的操作,
这个lifting 进程通过将程序中的每个汇编指令翻译成IR,可以清楚地说明其是怎样影响机器的内存和寄存器,flag的。
Lifted IR inadvertently inhibits similarity:实现这个lifting过程需要大量的工作,因为有很多的机器指令且一部分还会造成复杂的副效应和依赖于机器状态的一些元素。为了降低这些困难,lifting过程不考虑其是否通过最优的方法来实现,而是关注于如何捕捉精确的语义信息。
图3展示了三个简单的例子,(a)和(b)可以看到一条简单的move指令在64-bit的ARM下,其对应转换的VEX-IR所示,其包含了很多条相对复杂的算是操作构成的复杂指令,还使用了三个冗余的临时值(t14,t15,t16)。
图(c)和(d)展示了x86 64-bit下简单的add指令的汇编,和其对应的BIL代码。但是,尽管BIL规则允许临时值和常量之间的加法运算,其还是使用了一个冗余临时变量(T2)。
图(e)和(f)展示了x86 64-bit下的32bit减法指令,和Mcsema为其创建的LLVM-IR。但是创建的IR却尝试去进行一个更复杂的计算,进行了一个overflow的无符号减法,返回了一个包含减法结果和overflow标志的struct,但是在下一条IR指令中却没有使用overflow标志。

在一些使用案例中,这些IR中产生的一些变化或者冗余是无关紧要的,但是在程序相似性的上下文中,如图1(ii)所示,将会是具有破坏性的,并且在不同的平台、优化等级下寻找相似性时,将会是毁灭性的。
From lifted binaries to LLVM-IR strands:之前提到的几种IR 转换工具都有自己的设计思想:Mcsema关注于对中间代码的一些转换,比如说代码混淆和增加安全机制;BAP倾向于程序分析;VEX-IR为Valgrind指令的动态分析而建立。还有,每个工具都应用在专门的OS和结构集合:Mcsema在Windows binary工作的很好;BAP包含了x86 flag计算非常精确的表示;VEX可以泛化到多种架构上。
因为VEX-IR能够同时处理Intel和ARM架构并且支持浮点数指令,作者使用VEX-IR作为原型。实际的lifting过程是使用pyvex库,其是angr.io二进制分析框架的一部分。若不考虑我们原型的实现选择,我们希望我们的方法可以是lifter不可知的,所以我们将表征仅与LLVM-IR,并且实现了一个从VEX到LLVM-IR的转换器。我们选择LLVM-IR的原因是其稳定性、大规模的辅助工具、和多平台的支持。
在LLVM-IR的转换过程之后,我们的主要目标是建立能帮助我们寻找相似程序的程序表征。
我们将在strand创建之后进行lift过程。strand的创建过程:首先创建程序的CFG,然后对basic blocks进行切片。一个strand就是basic block中影响特定值的计算的指令列表,创建的strands的列表覆盖了basic block的指令,进而覆盖整个程序。
算法1展示了strand 提取过程的伪代码,其中Ref,Def函数返回被一个指令所提及或定义的变量集合,这个算法对基本块的指令进行迭代,根据函数使用链来手机strands,直到所有的指令都被覆盖了。

Canonicalizing LLVM-IR strands: 我们对程序相似性的定义依赖于我们方法在不同程序下检测相似性的能力。这就需要我们克服三个主要的困难: (i)编译器对strand语义的更改,例如:对size、runtime和控制流的优化 (ii)机器强加的约束,例如:可用通用寄存器的数量和指令集的表达能力。 (iii)和lifter相关的变化,如之前所述
使用strands来建立相似性的基础是寻找语义等价的strands,这种等价性适用于寄存器重命名和其他的编译器或者系统架构。例如:r12 + (rax * rbx)和x2 + (x4 * x7).等价。
一种寻找语义等价strands的方法是将其变为canonical形式,这个转换过程应当能够将所有语义相等的strands转换到相同的语法表示。
幸运的是,canonicalizing表达的问题已经被很好的研究切已经是现在了现代的编译器中,来允许common-subexpression elimination和不同级别(程序级别函数还是基本块级别)的优化。
正如我们使用LLVM-IR来表征strands,canonicalizer的很明显的选择就是CLang 优化器。在内部,我们将每个strand表示成一个LLVM程序,其接收所有参与计算的寄存器作为输入。为了能够使优化器能达到我们的目标,我们对LLVM程序进行两种简单的转换:
(i)将机器寄存器的表示变为全局变量
(ii)增加一条返回strand值的指令
需要注意,这些更改是必需的,因为strand是在二进制过程中从上下文中提取的
这个重要地优化器阶段,我们应用’common subexpressions elimination’和’ ‘combine redundant instructions’(分别由-early-cse 和-instcombine激活)
这个过程的一个例子如图1 (ii)到(iii)所示。关于优化过程更多的信息,可以参考LLVM文档。
Out-of-context re-optimization is crucial to establishing similarity: 通过规范化的形式精炼strands的表征是我们相似性搜索方法的重要一步, 但重要的是要注意,优化整个过程或基本块在大多数情况下效果不大,因为多个计算路径可能相互交织。这是建立二进制相似性的一个主要挑战。
对代码进行Re-optimizing允许我们从一个一个架构生成的未优化代码和另一个完全不同架构生成的高度优化过的代码之间进行相似性寻找。另外,事实上我们的目标是将代码放到相同的‘virtual’ machine(LLVM的简称)运行,这将帮助我们缩小不同架构之间用来比较的差距。
Moving to a normalized strand representation: 在编译器进行canonicalization的步骤是,strand(在此例子中设定为只有一个程序的基本块)被表征为有向无环图(DAG)的形式。ps:DAG也许可以被理解为数据流图DFG.即使比较DAG是可行的,但我们想要简化我们的表征到一些文本的形式,这可以允许快速的计算和简单的比较。使用CLang优化器输出计算的DAG的线性版本可以实现。 为了完成最后的转换,将二进制代码生成是的原有特性和编译选型去除,所需要最后的步骤是normalizing strand表征。这需要在strand中所有的符号重命名,例如标准化寄存器和临时变量的值到顺序的符号命名。
3.2 Scalable Binary Similarity Search
Using hashed strands to detect similarity :给定一个程序$p$,定义其strand表征为$R(p)$,hash函数使用MD5:
query q和 target t之间的一种基本的相似性定义可以被实现为其hash表征的交集$M(q,t) = R(q) \cap R(t)$,然而这个相似性指标在实际中表现的并不是很好。其中的一个原因是一些匹配的strands并不相关,因为它们是编译器自带的,并不表达什么语义信息。
Accounting for the binary creation process: 在evaluation章节我们将会展示,在程序编译和汇编代码生成阶段使用确定的编译器或者特定的体系结构会增加一些非语义相关的零件在源代码中。这些零件可能会通过一种特定的结构访问机器内存而造成副效应,或者与编译器实施的特灵的优化模式有关。在之前的工作中,例如[30]展示了,这些零件甚至可以被用来检测创建binary时所使用的工具链。
在知道了在语料中的query和target程序的精确来源信息(编译时使用的工具链、平台、编译选项等)后, 有可能允许我们来去除掉这些零件,但是对于stripped executables恢复这些信息是困难的。因此我们需要一些其他的方法来将query源代码的语义strands和不相关的零件strands分离开。
一种相对简单的方法是采用如下假设:在很多程序中经常出现的strand比那些罕见的strand携带更少的重要性。通常我们可以定义$Pr(s)$为一个strand s将随机出现的概率。一种更恰当的做法是通过如下两个因素来限制我们的概率空间:(i)从真实binaries 提取的strands标记为$W$,尤其是来自那些针对一种架构我们处理可以lift的binaries的strands标记为$\tilde W$。(ii)规范化和标准化的strands
我们使用如下概率来定义相似度指标: \(S_{\bar{W}}(q, t)=\sum_{s \in M(q, t)} \frac{1}{P r_{\bar{W}}(s)}=\sum_{s \in M(q, t)} \frac{|\widetilde{W}|}{|\lbrace p \in \widetilde{W} | s \in R(p)\rbrace |} \tag 3\)
Using random sampling to approximate strand frequency: 计算$Pr_{\tilde W}$是不可行的,这是因为它依赖于$\tilde W$(即使$\tilde W$在任意时间下是有限的)。相反的,我们取样一个很大的子集$P$,使用其来近似$Pr_{\tilde W}$:
\[\operatorname{Pr}_ {\bar{W}}(s) \simeq_{P} \frac{f(s)}{|P|} \tag 4\]其中: \(f(s)=\left\lbrace \begin{array}{ll} |\lbrace p \in P | s \in R(p)\rbrace | & s \in P \\ 1 & \text { else } \end{array}\right.\)
Embarrassingly parallelizable approach: 此方法基于成对strand hash比较和应用全局上下文来产生相似性分数。因此我们能够部署到多核的环境中,全局上下文被提前计算好并由每个核共同加载,一对函数的相似性分数由单个核在一秒内独立的计算出来。
实验环境:
CPU:four Intel Xeon E5-2640 (2.90GHz) processors (72 cores)
RAM;368GB(但实际只用了23GB)
OS:Ubuntu 14.04.2 LTS
4.Evaluation
在这一评估章节,目的是解答如下问题:
- GitZ在漏洞搜寻的场景下作用多大?
- GitZ能够处理多大规模的数据?
- GitZ的准确率如何?在解决不同架构、编译器、优化等级问题上效果如何?
- GitZ的每一部件对其最后准确率的影响多大?
- 相比于之前的工作GitZ如何?
4.1 Creating a Corpus to Evaluate the Different Problem Vectors
为了进行评估,我们需要知道比较的binaries 的标签,为此我们根据如下三个问题来创建binaries。
Different archiectures: 不同的系统架构能给指令集带来非常大的变化。在跨架构的设定上,我们的语料包括两种广泛使用的架构:Intel x86_64和ARM AArch64
Different compilers: 不同的编译器可以给binaries在语法上带来非常大的变化:寄存器使用、指令选择、代码顺序上。我们的测试预料使用3个不同的编译器的多个版本进行编译。
- $C_{x64}$: 针对Intel x86_64架构的编译器集合,包括CLang 3.{4,5}, gcc 4.{6,8,9} and icc {14,15}
- $C_{ARM}$:针对ARM AArch64的编译器集合,包括aarch64-gcc 4.8 and aarch64-CLang 4.0
- $O$:优化等级的集合-O{0,1,2,3,s}.
在最后,作者还创建了一个工具叫做Compilator,其将代码包和编译器的配置$\lbrace C_{x64} \cup C_{ARM} \rbrace × O$作为输入,为每个程序输出44个版本的binary。使用Compilator可以轻松的为开源软件( OpenSSL,git, Coreutils, VideoLAN, bash, Wireshark, QEMU, wget and ffmpeg)创建~500K 二进制程序。这些软件的有些版本是故意选择那些具有漏洞的版本,方便实验。
我们从这些语料中随机的选择了1K的程序来构架全局上下文$P$。
4.2 Evaluation Metric
因为对于一对二进制程序的相似性分数为一实数,所以对于每个query 程序,我们可以对返回的target程序进行排序。因此这里我们选用CROC 指标,其广泛用于对早期检索方法的评估,和度量在top ranking中存在多少的假正率。CROC同样还可以反映在遇到所有的真正样本之前假正样本的比率是多少。 然而,必须注意的是,CROC衡量的是随着阈值的增加而遇到的假阳性率,而不仅仅是它们的数量或百分比。
CROC和ROC非常的相似,但是对假正率给予了更高的惩罚,这对于漏洞检测场景来说是非常关键的。需要注意的是CROC对所有的阈值反应了准确率。事实上,对于所有的实验来说,没有一种明确的方法来为相似性分数分类为正匹配设置一个全局阈值,因为相似性分数会随着不同的语料和query的变化而变化。
作者使用Yard-Plot 和默认因子$\alpha =7$来实现。
Yard - yet another roc drawer. http://github.com/ntamas/yard.
4.3 GitZ as a Scalable Vulnerability Search Tool
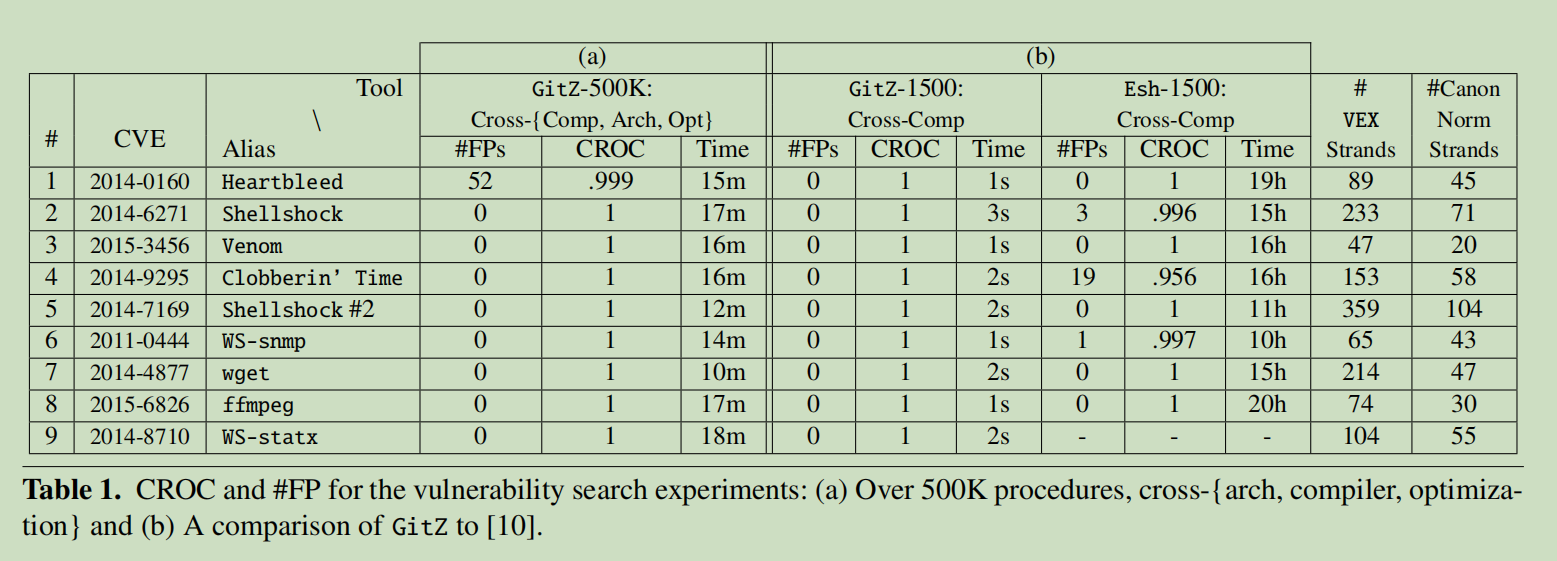
表1(a)展示了我们主要的实验细节,使用9个real-world的漏洞程序作为queries在所有的500K个程序语料中进行搜寻,对于每个漏洞,语料总共包括44个正样本。从结果中我们可以看到,除了(Heartbleed),所有的真正样本都在假正样本之前返回了。只有Heartbleed中,有52个假正样本排在了一个真正样本之前。
表1(b)中展示了GitZ与Esh的对比,且根据Esh中的实验重新创建了1500个跨编译器的程序语料(Esh不支持跨平台和优化选项)。结果显示GitZ拥有更好的准确率,并且运行时间缩短了4个量级,从18h降到了1.8s。
表1的最后两列展示了每个漏洞的原生VEX strands和canonical normalized strands的个数,从中可以看出来normalization and canonicalization能够有效的减少程序的表示大小。
4.4 All vs. All Comparison
为了更好评估GitZ的准确性和性能在不同的场景之下,我们随机从500K个程序语料中选取了1K个程序。实验在“ALL vs ALL”的设定下进行,即每个程序都作为query剩下的程序作为target进行搜寻。实验的目标是在query 和target由不同的架构、编译器、优化选项组成是,测试GitZ的性能。最后结果显示,平均CROC准确率为0.978,平均FP为0.03.总共用时1.1小时。
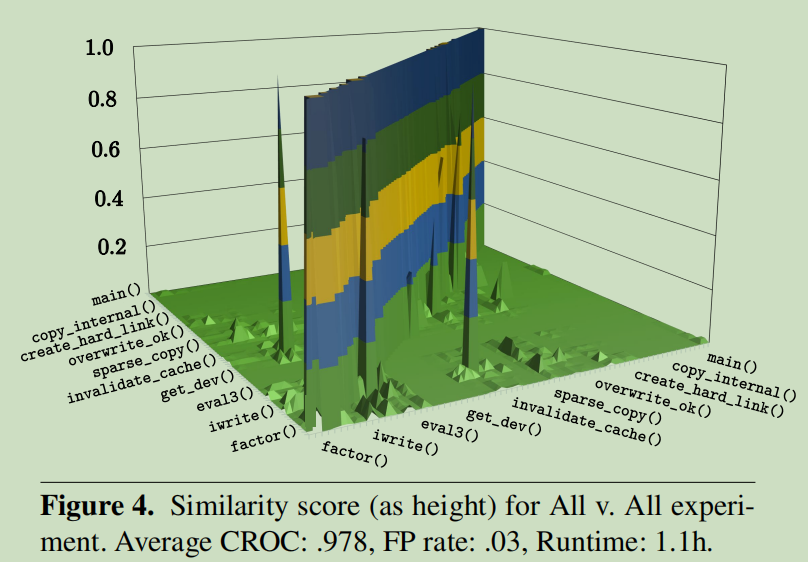 如图4所示,从中随机选取了100个程序进行展示,水平面的高度就是标准化后的相似性分数,每个轴都有相同的数据集:根据相同的原代码组在了一起。从图中有几个重要的发现如下:
(i)对角线展示了由相同原代码编译所得的程序的标签。正如期待的那样,相同源代码编译到不同的二进制程序的相似性分数低于真实标签,且依赖于在架构、编译器、编译选项上是怎么样的不同。
(ii)关于对角线对称。这是因为我们相似性分数的定义是对称的。
(iii)可以明显的看到一些误匹配。例如invalidate_cache()来自于dd.c,iwrite() 具有很高的相似性。在仔细的测试中发现,iwrite() 也来自于dd.c,且在调用iwrite() 时,invalidate_cache()会变成其中的内联函数。
如图4所示,从中随机选取了100个程序进行展示,水平面的高度就是标准化后的相似性分数,每个轴都有相同的数据集:根据相同的原代码组在了一起。从图中有几个重要的发现如下:
(i)对角线展示了由相同原代码编译所得的程序的标签。正如期待的那样,相同源代码编译到不同的二进制程序的相似性分数低于真实标签,且依赖于在架构、编译器、编译选项上是怎么样的不同。
(ii)关于对角线对称。这是因为我们相似性分数的定义是对称的。
(iii)可以明显的看到一些误匹配。例如invalidate_cache()来自于dd.c,iwrite() 具有很高的相似性。在仔细的测试中发现,iwrite() 也来自于dd.c,且在调用iwrite() 时,invalidate_cache()会变成其中的内联函数。
Evaluating all vectors, together and separately:表2展示了在“ALL VS. ALL”实验中一些架构、编译器、优化等级的组合的实验结果。
Similarity within compiler, architecture boundaries: 从表2的4-8行可以看出来,试图寻找GitZ在相同的编译器但不同的优化等级下的相似性表现。第9-18行试图寻找在跨编译器但相同架构、优化等级场景下的表现,只有很小的准确率损失,并没显示某个特定的优化等级被其他等级的问题更难解决。
Challenging cross-architecture scenarios: 第2-3 和19-28行展示了跨架构下的场景。我们可以发现跨架构场景是相对最难的问题。
如图5所示,对于调用packlist_find(&to_pack, peeled.hash, NULL)这个程序时,所需做的参数准备代码如两个不同架构下的基本块所示,这种内存布局上的差异会导致GitZ损失一部分的准确度。

对于通用模版函数,即使相同的模版函数,在不同的类型下,会编译到不同的二进制程序。在评估中,作者就遇到了模版程序,但是因为通用模版程序执行的算法流程是相同的,所以GitZ也有能力捕捉到足够的相同strands。
对于内联函数,在我们的实验中只造成了相对较小的误匹配,但是在一些场景下,内联函数通常会跟调用此内联函数的调用者更有机会误匹配。为此,为了纠正这些结果的标签,将会增加一个caller-callee相似度 pass flagging作为真正例。
4.5 Comparing Components of the Solution
The effect of canonicalization and/or normalization:GC代表全局上下文

从图6中我们可看出来:
(1)全局上下文的使用对于所有设定普遍的增加准确率
(2)Normalization对于实现语义等价性非常重要,其能将频繁变动的寄存器名字统一化。
(3)Canonicalized,normalized场景下受全局上下文的影响很大,能够多获得0.051的CROC准确率。
4.6 Understanding the Global Context Effect
 如图7所示,在一开始随着$P$的规模的增加,会大幅度的减少假正样本的个数,但最后会在大约400个程序时达到了固定值。作者还试图将$P$的大小增加到了500K,但是实验中假正样本数仍然没有减少。
如图7所示,在一开始随着$P$的规模的增加,会大幅度的减少假正样本的个数,但最后会在大约400个程序时达到了固定值。作者还试图将$P$的大小增加到了500K,但是实验中假正样本数仍然没有减少。
所以实验中作者使用$P$的size为1K,来相对稳定的获得较高的性能。