请咨询作者同意后转载。
Cross-Architecture Bug Search in Binary Executables
| 期刊/会议: | S&P(A类) |
|---|---|
| 发表时间: | 2015年 |
| 发表机构: | Ruhr-Universitat Bochum |
方法概述
定义bug signature: 特定漏洞实例的一段二进制汇编代码,用来在其他的二进制程序(target program)中寻找可能存在的漏洞。
为了达到这个目的,作者首先为漏洞程序导出bug signature,然后将bug signature和target program 转换为中间表示,并且建立紧凑的basic block级别的语义hashes。
图1阐释了对指令ldrb(ARM),lbu(MIPS),lodsb(x86)的处理过程。首先 作者将这些汇编指令转换成中间表示,这些中间表示由易解析的S-表达式(symbolic expressions)表示的一组assignment formulas组成。这些assignment formulas告诉我们输入变量是如何影响输出变量的。例如x86例子中第一行表示ESI指向地址的前8个比特被存储在寄存器AL中,然后ESI根据标志位DF进行自增减。而对于每个formula有着不同的输入个数,例如终止符没有输入、AL,V0,V3这些变量为一个输入,ESI变量为两个输入。随后 ,使用随机的输入值来为这些formulas来取样其输入/输出行为。例如对于ESI的x86 formula来说,对于输入(5,1)–>(addr,DF),其输出值为6。最后 为这些I/O对建立语义hashes,这允许对basic blocks的I/O行为进行高效的比对。

在搜索阶段 ,使用转换过的bug signature在也经过相似转换的二进制中来识别bug。对于每个候补对,我们应用了一个CFG驱动的,贪婪地局部最优算法。该算法使用从bug signature和target program中的额外基本块扩展了初始匹配,然后计算bug signature和target programs之间的相似性分数,返回排序过的代码坐标列表。
方法详解
1.Bug Signatures
一个bug signature就是正常二进制代码:它由基本块和基本块之间可能的控制流转移组成。因此,理论上,任何的基本块选择都可以成为一个bug signature。但是,和漏洞有关的基本块将会提高性能,相反则会增加误报率,所以我们需要尽可能的只选取和漏洞相关的代码块。
2.Unifying Cross-Architecture Instruction Sets
因为不同的平台拥有不同的指令集、调用规范、寄存器、内存访问侧率等,如图2所示,相同的代码编译到不同平台下的汇编代码,就造成了不同平台之间的汇编代码具有相当大的语法鸿沟。
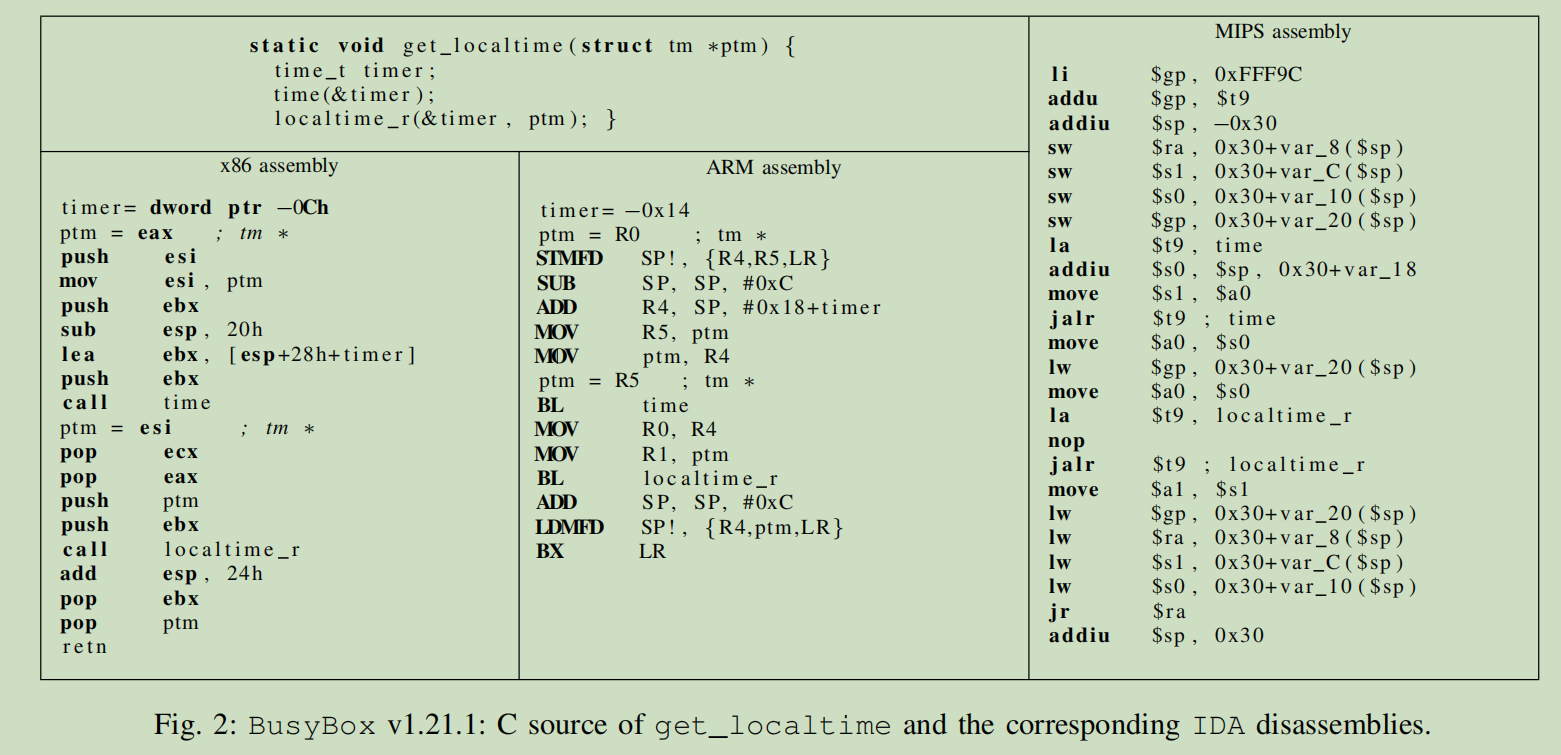
为了填补这种语法鸿沟,一个关键的步骤就是将不同架构下的二进制汇编代码进行统一化。 这样做的优点如下:
- 它从体系结构特定的工件中抽象出来,并促进符号规范化
- 之后就可以利用这些平台无关的指令集,且这个转换过程只用实现一次。
3.Extracting Semantics via Sampling
虽然统一指令集允许我们在语法上比较不同指令之间上的差异,但是像调用约定、寄存器、内存访问方式等仍然存在着差异,所以我们希望能够从二进制代码中提取语义特征进行比较。 因此,作者将基本块的每个输出变量的计算步骤累积了起来,这样就可以对于每个寄存器和输出内存地址精确的assignment formulas。(如图1第二列所示)
另外还需要特别关心控制流的转移,由定义可知,每个基本块都由一条terminator 指令(jmp,ret等)结束,来决定控制流中的下一个基本块。为了从具体的跳转地址中进行抽象,我们定义继承基本块通过函数符号名或者基本块的编号来进行跳转。
在为每个基本块提取出formulas后,需要使用定理证明来队assignment formulas进行简化来标准化。因此将这些RISC-like的指令累积起来,然后映射到定理证明器的结构,定理证明器返回S-表达式。
但目前我们获得的仍然是语法上的描述,为了能够实现bug finding的目标,作者将代码等价性的条件放宽到代码相似性。为此,作者采用了sampling的方法来提取程序的语义信息。首选作者随机生成一些具体的值,输入到每个基本块的formulas来进行计算,观察formulas的输出结果,作为语义相似性的依据。
作者为了能够更好的捕捉formulas的语义信息,对采样策略进行了设计:
- formula的输入变量越多,为其采样的输入变量的次数就越多
- 对运算进行了一些置换,来保证鲁棒性。比如$a:=b-c$和$a:=c-b$会被认为相似。
- 对于一些容易被误解的I/O pairs,为定理证明器来寻找特殊的“magic values”来进行区分。例如:$a := b == 0$和$a := 2 ∗ b + 3 == 5$这种bool作为输出的,功能不同但是输出确十分相似。
4.Similarity Metric via Semantic Hashes
我们现在已经可以根据两个基本块之间相同的I/O 对的个数,来通过Jaccard等方式来计算它们的相似性。然而这样的方法计算效率太低,为了解决这个问题,作者采用LSH中的MinHash方法通过合并I/O对来计算基本块的hashes,使得基本块I/O对集合的表变成了基本块的hash值的比较。
5.Comparing Larger Binary Structures
对于有些漏洞来说,仅仅比较单个基本块之间的相似性是不足够的,因此bug signatures通常由多个基本块和CFG组成。
我们需要将单个基本块的比较扩展为能识别整个bug signature的算法。首先,我们从bug signature中挑选一个basic block,对有目标program所有的basic block做比较,然后,作者使用一个叫Best Hit Broadening(BHB)的算法,可以随着bug signature和目标程序中的CFG拓宽初始匹配。BHB以贪婪但局部最优的方式进行,直到遍历整个signature。然后对bug signature种的其他基本块重复进行,返回有相似性排序的函数列表。
具体实现
1.Common Ground:The IR Stage
平台支持ARM,x86和MIPS,但是不支持x86-64,因为它使用不同的寄存器大小,将导致错误匹配。 首先,使用IDA PRO反汇编二进制程序和提取控制流图。
下一步 ,因为VEX-IR支持很多平台,作者利用VEX-IR来作为中间表示,VEX可以将二进制转换成IR。
然后, 利用VEX-IR的python框架pyvex,输入二进制操作码,将VEX申明拆分为语义相等的Z3定理证明器所需要的结构。(Z3定理证明器以简化和标准化表达式为目标,切能方便的返回S-表达式)
图3展示了不同平台下相同功能basic block的VEX表征,所有指令的语义信息都通过RISC(精简指令集)操作来说明。在x86例子中t1 = GET:I32(32)加载寄存器ESI的内容到临时变量t1中,t Put(8) = t8将t8的值写进AL。最后一行将返回地址写入EIP。

图4展示了上述VEX表针对应的S-表达式映射。

Extracting Semantics: Sampling
生成从$[-1000,1000]$范围内的随机向量,使用它们作为formulas的输入,这足够避免输出值发生碰撞。再使用相同的输入序列来作为输入评估素有的formulas,然后计算输入长度、输入、和输出值的64bit CRC校验码作为每个I/O对的表征。因为寄存器名字在每个平台不同,所以在计算校验码时去除输出的名字。
为了保证对取样变量顺序的鲁棒性,我们对变量进行了置换。例如对于formulas $a:=b-c$和$a:=c-b$,具有相同的功能,但是对于输入(b=1,c=2)和(b=3,c=5),其各自的输出为(-1,-2)和(1,2),结果并不相同。因此,我们对输入进行置换,(b=2,c=1)和(b=5,c=3),我们将得到输出(-1,-2,1,2)和(1,2,-1,-2),数值已经全部相同了。但是对于4个输入以上的formula不进行置换。
Semantic Hash
作者采用MinHash方法来计算block之间的相似度,采用越多的hash函数将会得到更好的MinHash性能。MinHash的工作流程如下:它应用非密码学的hash函数对列表中的每个元素进行hash,然后存储所有I/O 对种最小的hash值。两个MinHashes之间的相似性分数为$i=0…n$个hash值的平均:
\(\operatorname{sim}\left(m h_{1}, m h_{2}\right):=\left|\left\{m h_{1}[i]=m h_{2}[i]\right\}\right| / n\) n个hash函数的期望误差为$O(1/\sqrt n)$,所以当使用800个hash函数时,会导致约%3.5的误差。
我们使用仿射hash函数作为我们的hash函数,系数都为64位,p为素数。
\[h(x):= ax+b modp\]为了能够提高性能,我们对上面的hash函数做了循环移位和异或运算:
\(t(h(x)):=r o t a t e(h(x), a) \oplus b\) 这种变换改变了元素顺序,因此也改变了被选择的最小值。
坐着对标准的MinHash算法做了两种提升方案。首先 ,我们为每个基本块计算multiple MinHashes,(标记为Multi-MinHash)。其是这样做的:根据每个formula的输入变量的个数对formulas进行分组,对每个组计算一个MinHash。然后,我们只比较具有相同变量数的MinHash,根据各自基本块中formulas的数量和各自变量数目的个数来对单个MinHashes进行加权,从而计算整个相似性。因此,为了比较两个基本块,我们需要计算:
\[\frac{\sum_{i} s_{i} \cdot\left(w_{i}+w_{i}^{\prime}\right)}{\sum_{i}\left(w_{i}+w_{i}^{\prime}\right)}\]其中$s_i$为具有i个变量formulas的相似性分数,$w_i$和$w_i’$分别为第一个基本块和第二个基本块中变量的数量和formulas的数量。Multi-MinHash因此能够解决仅有少量样本的formulas在hash 值中under-represented的问题。
其次,我们不仅仅为每个hash函数存储最小的hash值,我们存储的是k个最小的hash值–我们标记为k-MinHash。这个修改允许我们一定程度的估计在I/O对的多个集合中元素出现个频率,例如,我们可以识别一个基本块中有多少个相等的formulas。
Bug Signature Matching
之前提到过我们使用Best-Hit-Broadening算法来将与b个基本块之间的相似度比较,拓宽到图之间的比较。
其工作流程为:给定一对起始点(一个来自于bug signature的基本块和其对应的target program中的基本块),首先在各自的CFG中探索其基本块的直接邻居,可向上探索和向下探索,使用匹配算法来发现刚才邻居节点的局部最优匹配,挑选出具有最大相似度的匹配标记为已匹配,如图5(a)所示。然后BHB在对已经匹配的基本块对进行扩展,如图5(b)所示,这个过程是贪婪地,以此来避免昂贵的回溯步骤。这个过程重复直到所有bug signature中的基本块都匹配完毕。然后,BHB计算所有已匹配对的平均相似性分数,得出两个图之间的相似性分数。最后,在对其他的b-1个候选对使用BHB算法,根据图之间的相似性分数进行排序。
EVALUATION
具体的自己看论文吧。。。