DEEPBINDIFF: Learning Program-Wide Code Representations for Binary Diffing
https://github.com/deepbindiff/DeepBinDiff
| 期刊/会议: | NDSS2020 |
|---|---|
| 发表时间: | 2020年2月 |
| 发表机构: | Cornell University |
前言
这篇文章提出了一种细粒度的基本块匹配的方法,因为之前已经有INEEREYE事针对基本块匹配的,所以指出了其InnerEye的缺点:每个函数都要通过有3百万参数的神经网络,极大的影响效率。并且scalability不是很好,对于两个二进制文件可能要花费数小时。并且还会遭受OOV(out of vocabulary)的问题 。
所以作者设计了新的模型来提高效率和准确率。
方法总览

整个系统包含三个主要的成分:
- 预处理: ICFG(过程间控制流图)生成和基本块的特征向量生成
- embedding生成:根据ICFG和特征向量来为每个基本块生成包含了图上下文信息的embedding。
- 代码比较:使用k-hop贪心算法来进行匹配
一、预处理
1.1 特征向量生成
这一部分主要包括两个子任务:token embedding 生成和 basic block的特征向量生成
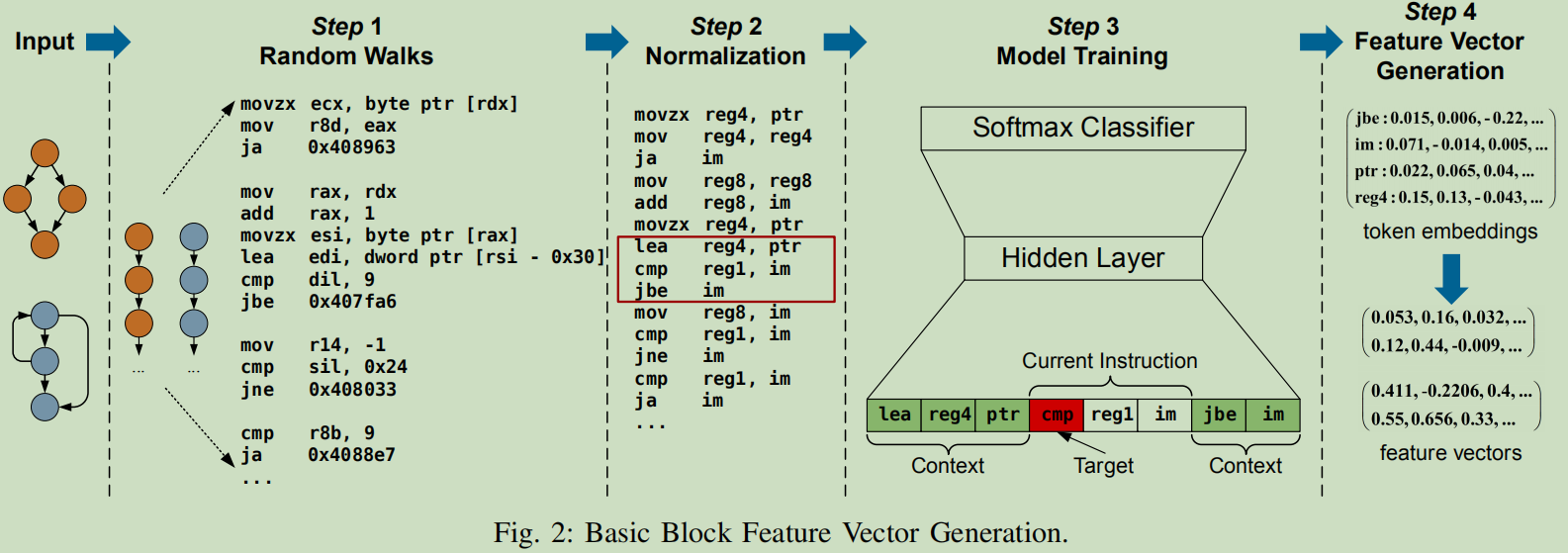
随机游走: 在对每个词条(指令中的操作码和操作数)进行嵌入的时候,作者使用了Word2vec,所以我们需要从ICFG中提取控制流依赖路径来生成语料。
作者根据以下策略来配置随机游走引擎:
- 每个基本块至少包含在两个随机游走序列中
- 每条随机游走路径长度包含5个基本块
标准化:
- 所有数字常数被替换为“im”
- 所有通用寄存器根据其长度重命名
- 指针被替换为字符串“ptr”
需要注意的一点是,在INNEREYE中将所有的字符串替换成了
,但是我们这里进行了保留,因为其可以帮助进行基本块的区分。
模型训练: 作者采用Word2Vec中的层级式CBOW模型,使用每条指令的前一条、后一条指令中的词条作为上下文,来对每个词条进行建模,
在对Word2vec模型的修改上,类似于Asm2Vec,如图2 Step3所示,将指令中每个操作数的embedding求平均,然后串接上操作码的embedding来生成该条指令的mebedding,最后将这个基本块中的所有的指令embedding求和来形成基本块的特征向量。
但是,因为每条指令可能具有不一样的重要性,所以作者对操作码的embedding乘以TF-IDF权值。
所以,整个基本块的特征向量的计算公式为:
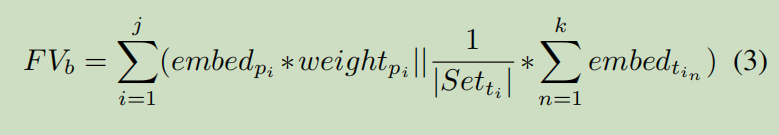 其中$in_i$为一条指令,$p_i$为操作吗,集合$Set_{t_i}$为指令$in_i$的操作数的集合,$FV_b$为此基本块的特征向量。
其中$in_i$为一条指令,$p_i$为操作吗,集合$Set_{t_i}$为指令$in_i$的操作数的集合,$FV_b$为此基本块的特征向量。
这里需要注意,虽然对token embedding的方式十分类似,但是DeepBinDiff是通过对程序的随机游走来学习token embedding;而Asm2Vec是祈求在函数内同时学习函数和token embeddings。
二、EmBedding 生成
在这一阶段,需要基于ICFG和前一步生成的基本块的特征向量,来生成包含了上下文图信息能用来做相似度判别的embedding。主要分为两步:合并ICFG,TADW(Text-associated DeepWalk algorithm (TADW))。
2.1 TADW算法
TADW算法能够融合节点的特征到网络的表征学习过程中,在其论文中证明了DeepWalk等价于分解一个矩阵$M \in R^{|v|\times |v|}$,其中每个实体$M_{ij}$是节点$v_i$随机游走到节点$v_j$的平均对数概率。基于此思想,TADW算法的流程描绘如图3所示:
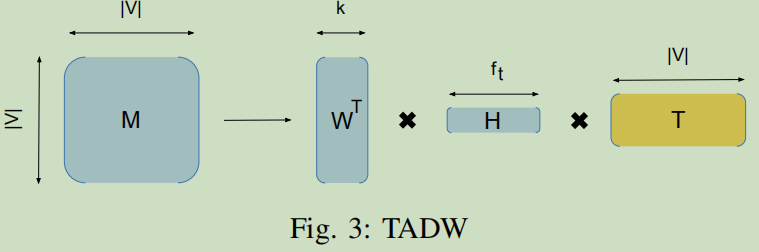
可以将矩阵$M$分解到三个矩阵的乘积的形式:$W \in R^{k \times |v|}$,$H \in R^{k \times f}$和文本特征$T \in R^{f \times |v|}$。然后$W$可以和$HT$串接起来形式2k维度的节点表征。
2.2 图合并
这里如果我们直接使用TADW算法对两个图运行两遍的话会有如下两个缺点:
- 分解两次矩阵是低效的
- 单独的生成embedding可能会丢失某些重要的相似性判别指标。
此方法中的图合并示意图如图4所示:
 先提取每个基本块中的字符串引用和库函数调用,并为其添加一个虚拟节点,将相同的引用、调用节点之间添加边,这样具有相同引用、调用的节点之间至少有一个相同的邻居。
先提取每个基本块中的字符串引用和库函数调用,并为其添加一个虚拟节点,将相同的引用、调用节点之间添加边,这样具有相同引用、调用的节点之间至少有一个相同的邻居。
2.3 基本块Embedding 生成
利用合并后的ICFG和基本块的特征向量,使用TADW算法最小化如下的ALS损失函数:
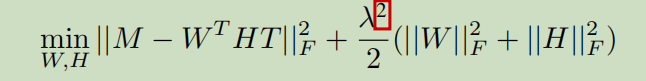
三、代码相似性比较
INNEREYE中所采用的方式是线性比较,即每个基本块都和其他基本块生成一个相似性分数,但这样比较的效率就太低了。 为此,作者采用了两段式比较的方法:先生成函数级别的embeddings,来匹配函数。然后在对匹配上的函数使用基本块比较的方法。
另外,作者还引入了K-Hop 贪心匹配算法来进行快速的基本块匹配。
3.1 K-Hop 贪心匹配算法
算法的整个流程如下图所示:

先使用虚拟节点生成最初的匹配集合$Set_{initial}$,然后的得到当前匹配节点的k hop邻居,在这些邻居中寻找相似度最大的且过阈值的未匹配的节点对,加入到当前节点中。最后对那些从未匹配过的节点使用线性方法进行匹配。
最后$Set_i$为插入的基本块,$Set_d$为删除的基本块。