PDiff: Semantic-based Patch Presence Testing for Downstream Kernels
作者:Zheyue Jiang,Yuan Zhang,Jun Xu,Qi Wen,Zhenghe Wang,Xiaohan Zhang,Xinyu Xing,Min Yang,Zhemin Yang 单位:复旦大学 出处:CCS 2020 论文:paper
1.Abstract
这篇文章介绍了一种从patch-related functions中提取语义信息,比较语义信息的相似性来度量开源Kernel 中patch存在性的方法。
引出问题: 开源的Kernel系统如今被大规模的下游服务商(downstream vendors)所采用,比如说基于Linux的安卓和IOT设备,但是这些下游的服务商们经常忽略或者拖延采用mainstream Kernel发布的补丁,这就导致上下游Kernel之间的安全等级会不一致。
对于那些需要重视安全威胁的企业、政府单位来说,测试下游Kernel patch存在与否的技术就显得至关重要。
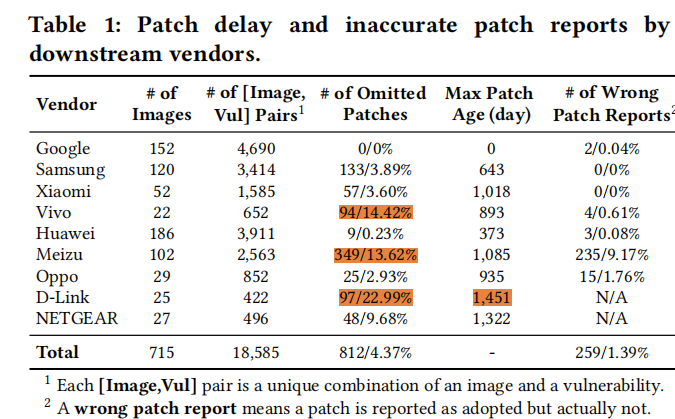
为了更好的揭示下游服务商们对mainstream Kernel发布补丁的采用情况,作者从9个下游服务商收集了715个基于Linux的Kernel镜像,并对mainstream Kernel的152个 漏洞的补丁状态进行了分析:
- Vivo、Meizu和D-Link忽略了10%以上的mainstream Kernel的patch
- 有些patch超过1000天才被采用
- 厂商存在报告了patch但实际没patch的情况
2.Problem Scope
问题定义: Mainstream kernel修补了一个漏洞,并且公开这个patch的源代码,PDiff需要测试这个patch是否在下游 kernel中是否存在。
任务假设:
- 测试人员仅能访问下游Kernel的binary。
- 下游kernel的bianry没有经过混淆
- …
3.Challenges
补丁存在测试技术的面临的主要挑战是上下游kernel 代码之间的差异,这些差异主要源自以下两方面
1. 第三方代码定制化: 下游服务商通常会对mainstream kernel进行定制化的修改来适应到自己的设备上去。
作者对收集的下游kernel镜像中被安全补丁影响的函数进行分析,发现72%的函数和mainstream kernel版本存在代码差异(被下游服务商定制化)。
挑选了其中12%的函数进一步分析,发现65.12%的定制化代码是和patch相关的,这些定制化代码会使得上下游kernel之间的patch不一样,会导致对下游kernel patch的测试更加困难。
2.非标准的build配置:下游服务商还会使用自己的配置信息来编译下游kernel,比如:编译选项、自己设计的宏和优化选项。
4.Approach
4.1 Insight
PDiff的insight可以说是从由上及下的三个层次进行展开: 第一层:比较目标kernel 和patch前/后的mainstream kernel版本的相似性。(看与哪个版本更相似) 第二层:使用被patch所影响区域的语义信息进行比较。(降低patch代码变化造成的差异程度) 第三层:精心规划被patch影响的区域。(包含完整patch语义,且具有最少的patch无关代码)
4.2 OverView
- 首先根据mainstream kernel的patch、其patch前后的版本,选择出一个Anchor block,来确定被patch影响的区域。(Insight 3)
- 从被patch影响的区域中提取语义摘要。(Insight 2)
- 根据patch区域的语义摘要来和目标kernel做对比。

4.3 Anchor Block Selection
4.3.1 Selecting Anchor Blocks for Reference Versions
首先确定和patch相关的函数,和被patch影响的基本块。 选择策略:
- 所有被patch影响的路径最终都会经过anchor block。
- Anchor block后没有和patch相关的代码。
- 最后确定的reference anchor block必须在patch前/后的版本都为anchor block。

4.3.2 Selecting Anchor Blocks in the Target Kernel
先定位patch对应的函数,提取出函数中的基本块,然后寻找如下两个方面和reference anchor block一致的基本块作为anchor blocks:
- 一致的Termination type (function call, return, …)。
- 一样的全局内存访问个数。
这样的anchor blocks可能有多个,但是在进行相似性比较时只会选择一个。
4.4 Patch Summary Generation
为了从patch区域中提去尽可能多的语义信息,PDiff使用符号执行提取如下信息:
- 路径约束—- Abstract Syntax Trees (ASTs)
- 内存状态—- Memory accesses pair
- 函数调用列表—-Ordered list
4.5 Summary-based Patch Presence Testing
对patch前/后的mainstream kernel版本和目标kernel版本分别提取三类patch摘要信息, 来计算$Sim(target,pre)$和$Sim(target,post)$
若$Sim(target,pre)>=Sim(target,post)$,则目标kernel没有被patch; $Sim(target,pre)<Sim(target,post)$,则目标kernel被patch。
因为目标kernel中可能存在多个anchor block,最后选择的anchor block需要最大化: \(Sim(target,pre)+Sim(target,post)\)
5. EVALUATION
5.1 测试集的建立
收集的715个images中只有406个具有源代码,根据这些源代码,作者使用一种半自动的方法来根据152个漏洞的patch是否存在于这些images中作为ground truth。
首先,如果patch添加的代码出现在测试image的源代码中,那么认为这个image是被patch过的。若未出现,则手动检查。
其次,将这些源代码进行编译,如果生成的binary中patch的指令序列和测试image中的指令序列不一致,则从这个patch的ground truth中移除这个image。
最后生成了11,511个具有ground truth的(image,patch)样本对,对应51个不同的patch。
5.2 评估PDiff在实际使用中的效果
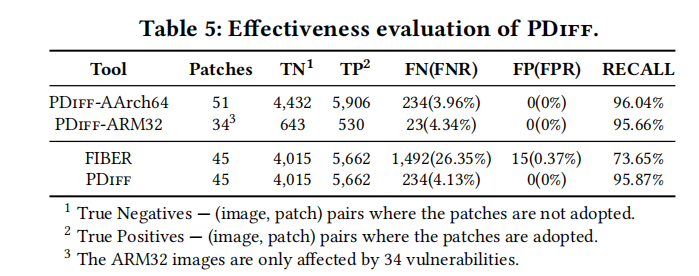
PDiff的误报率为0,漏报率为4.13%;FIBER的漏报则为26.35%。
5.3 评估PDiff能否应对代码定制化问题
实验设置: 从测试集中选取了173对样本,其中105个样本的patch会受到定制化的影响。
FIBER对受定制化影响patch的漏报率上升到了36.67%,而PDIFF只有6.67%。

5.4 评估PDiff能够应对不同的编译配置
实验设置: 从测试集中选择了1080对样本,其中308对样本的宏和mainstream 定义的不一样。
对于那些收宏所影响的patch,FIBER的误报率从28.27%上升到了40.85%,而PDiff只有6.33%的误报率。
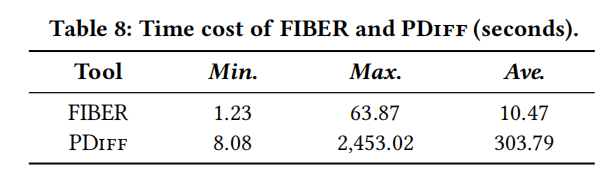
5.5 运行效率