Experience Report: System Log Analysis for Anomaly Detection
https://github.com/cuhk-cse/loglizer
| 期刊/会议: | ISSRE 2016 (CCF-B) |
|---|---|
| 发表时间: | 2016年 |
| 发表机构: | The Chinese University of Hong Kong |
一.研究背景
日志异常检测的重要性:
- IT企业的大规模分布式服务器 每天24小时运转
- 这些服务器上的应用为全球数百万的用户提供服务
- 这些服务器上出现的事故会造成巨额的经济损失
日志异常检测现今面临的难点:
- 因为现代操作系统大规模和并行化的特性,导致日志内容很复杂,需要领域知识
- 日志数据规模非常的大,分布式系统每小时可产生50GB日志
- 日志系统中通常含有大量的冗余信息
基于以上原因,所以传统的基于规则和启发式的日志挖掘方法不再适用。
作者指出的自动化日志异常检测方法在应用时面临的问题:
- 需要阅读大量的相关文献,来找到一个合适的方法
- 很多的异常检测方法都没有开源,来直接使用
- 没有关于这些异常检测方法之间的对比
为此,作者实现了3个有监督方法(逻辑回归、决策树、SVM),3个无监督方法(Log Clustering、PCA、Invariant Mining)来在收集到的数据集上做比较。
二. 日志异常检测的框架流程
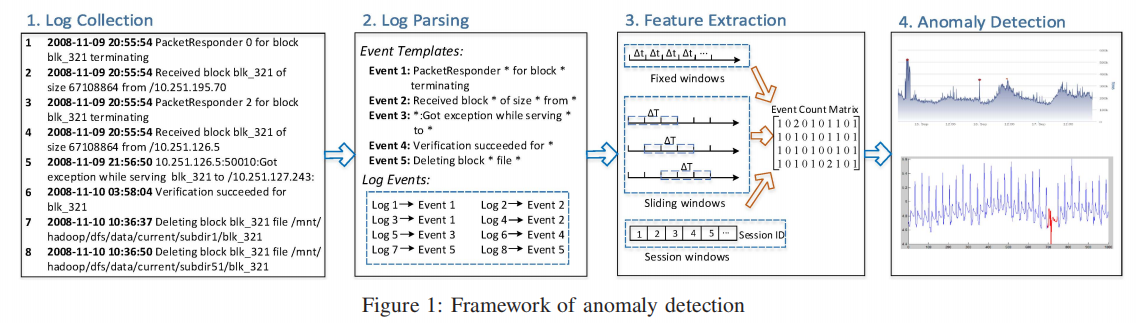
异常检测框架主要由如下四步组成: 日志收集、日志解析、特征提取、异常检测。
Log collection: 将系统运行时的日志信息收集起来。
Log Parsing: 将纯文本的每个日志记录,转化成对应的事件模板。
Received block * of size * from *
Feature Extraction: 将日志序列编码成关于 每个事件出现频率的 特征矩阵。
Anormal detection: 应用机器学习的方法,在特征矩阵上训练和预测。
三. 方法论
3.1 日志解析
日志通常是纯文本内容,并且由固定部分和可变部分这两部分内容组成。
比如
Connection from 10.10.34.12 closed
Connection from 10.10.34.13 closed
中Connection from * closed 就是固定部分,而ip地址则是可变部分。
而日志解析的目的: 就是把每条日志解析成固定部分和可变部分,并且形成一个事件模板。
上面的例子Connection from * closed 就是解析得到的一个事件。
通常可采用聚类方法或者启发式方法来完成日志解析。
3.2 特征提取
特征提取的主要目的是: 从记录的事件中提取有价值的特征,来供异常检测模型使用。
而为了从日志中提取特征,首先需要将这些日志数据划分到不同的日志序列中去,每个日志序列包含多个日志事件。
通常有三种类型的提取方法: Fixed windows, sliding windows, session windows.
Fixed windows: 基于每个日志事件的事件戳,每窗口大小$\Delta t$时间内的记录下的事件为一个日志列。
Sliding windows: 类似于TCP的滑动窗口,除了窗口大小$\Delta t$外,还有步长参数,会在每个步长进行一次窗口滑动,来记录日志序列。 滑动窗口相对于固定窗口可以收集到更多的日志序列,但同时不同日志序列中会有很多冗余的事件记录。
Session windows: 相对于前两种使用时间戳来进行序列划分的方法,session windows使用的是一些日志事件记录时所用的会话id,而一个会话通常就是一个完整的日志序列。 前提是每个日志事件都有会话id。
3.3 异常检测
有监督方法:
- 逻辑回归
- 决策树
- SVM
无监督方法:
- Log Clustering
- PCA
- Invariants Mining
四.实验
4.1 实验设置
数据集:
- HDFS
- BGL
总共15,923,592个日志信息和365,298个异常样本。
在这两个数据集上,对之前的6种机器学习方法做比较。
实验结果
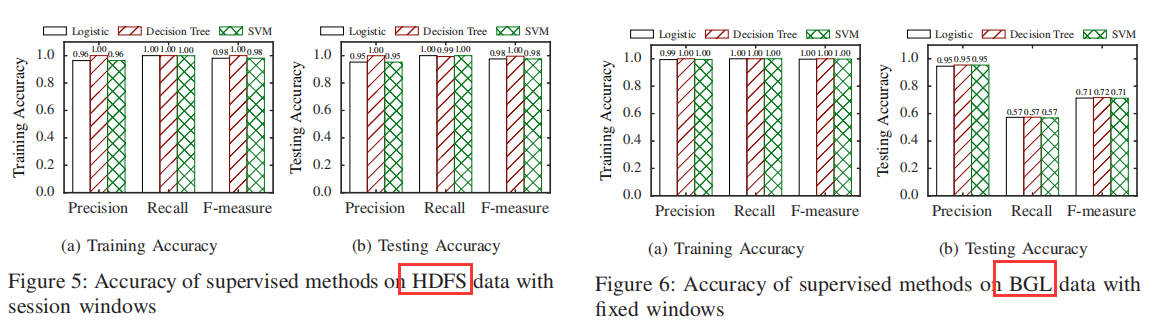
结论 :有监督方法可以达到很高的精确率,但是召回率在不同数据集上不同。
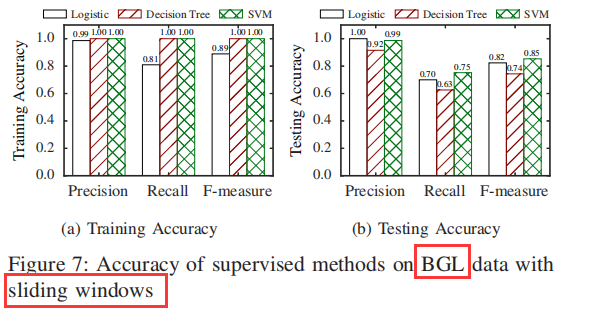
结论: Sliding windows可以达到更高的准确率和召回率。
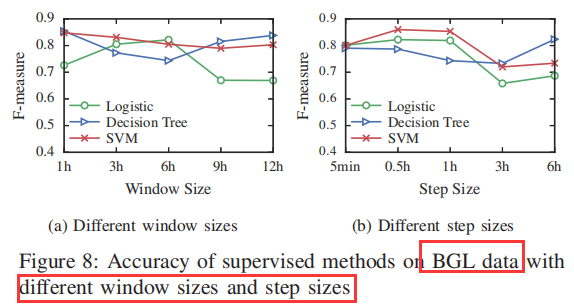
结论: SVM的表现相对更好,参数步长会对结果产生较大影响。

结论: 无监督方法会比有监督方法,准确率更低一些。 Invariant Mining方法表现更好。
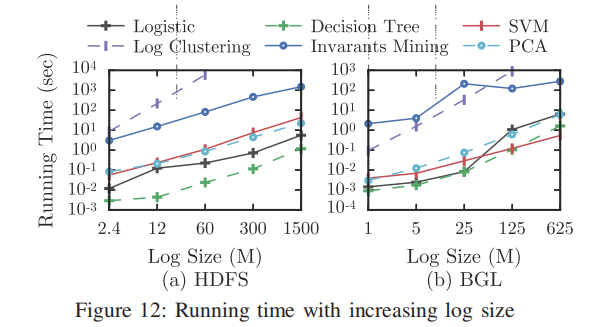
结论: Log Clustering 和Invariants Mining方法 比较耗时,其他方法耗时和数据规模成线性关系。