An Evaluation Study on Log Parsing and Its Use in Log Mining 阅读笔记
https://github.com/cuhk-cse/logparser
| 期刊/会议: | DSN 2016 (CCF-B) |
|---|---|
| 发表时间: | 2016年 |
一. 研究背景
传统日志分析方法面临的挑战:
- 现代操作系统的复杂性,导致日志结构的多样性和复杂性
- 越来越大的日志规模,一小时50GB.
现在有的四种自动化日志解析方法:
- SLCT
- IPLoM
- LKE
- LogSig
现有自动化日志解析方法使用时存在的问题:
- 缺少系统的评估
- 缺少可用的方法实现
研究三个主要问题:
- 这些日志解析方法的准确率如何?
- 这些日志解析方法面对数据量增长时的伸缩性如何?
- 不同的日志解析方法怎样来影响日志挖掘的结果?
二. 日志解析
日志解析的目的: 将日志中的常量部分提取出来,并且形成事件模板。
例如,将下面这条日志
Receiving block blk_-1608999687919862906 src: /10
.251.31.5:42506 dest: /10.251.31.5:50010
解析成
Receiving block * src: * dest: *
流程图示如下:
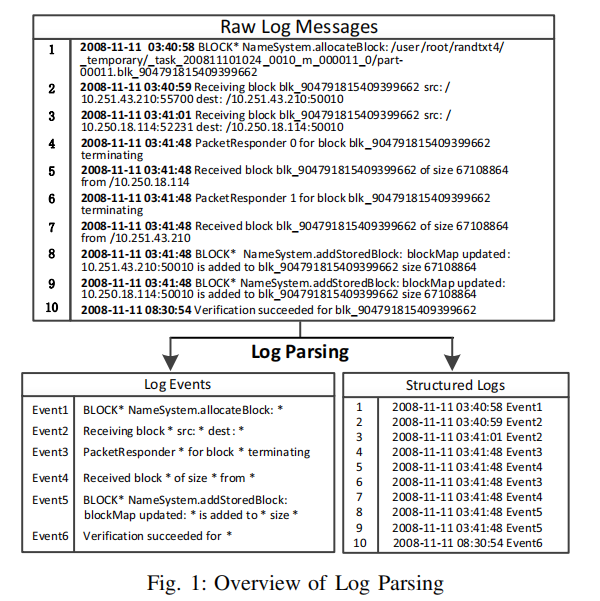
工具实现: 用python实现了一遍。
三. 日志挖掘
日志挖掘的应用场景:
- 异常检测
- 部署验证: 验证开发环境(伪云)与部署环境(云)日志的一致性。
- 系统模型构建: 帮助开发者了解系统的运行。
作者重点对异常检测的流程进行了概述。
系统异常检测:
- 日志解析
- 事件矩阵生成
- 异常检测模型使用
四. 实验评估
数据集构建: 使用了从超算(BGL,HPC)到分布式系统(HDFS,ZooKeeper)到独立工作站(Proxifier)的5个大规模数据集,16百万行日志记录。
4.1 RQ1: Accuracy of Log Parsing Methods
从每个数据集中随机抽选了2k个样本,进行日志解析的准确度测试。
结论: 现在的日志解析方法能达到一个很高的准确率。
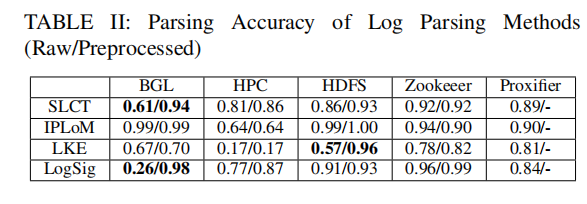
使用专家知识对数据集进行预处理(IP地址移除)后,评估准确率是否有提升?
结论: 一些简单的预处理方法可以有效的提升日志解析的准确率。
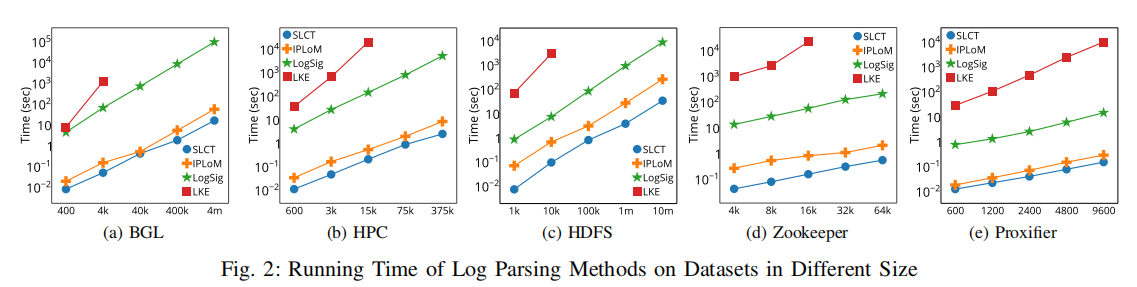
4.2 Efficiency of Log Parsing Methods
在每个数据集上,对不同算法的运行时间进行了统计。
结论:
- SLCT和IPLoM的运行时间和日志规模大小成线性缩放,都能在5分钟内处理1千万条日志数据。
- LogSig虽然也是线性缩放,但是会更耗时一些。
- LKE为指数时间阶级,不能应用到大规模系统上去。
4.3 RQ3: Effectiveness of Log Parsing Methods on Log Mining
使用不同的日志解析方法,应用到具体的异常检测场景中去,看看效果如何?
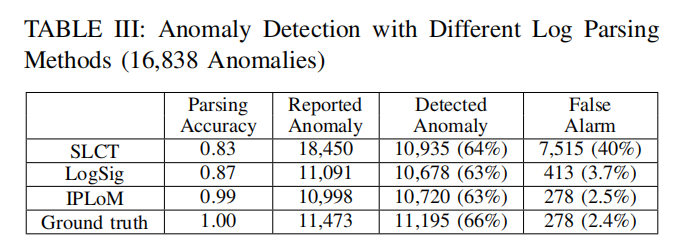
结论1: 日志解析是非常重要的,好的日志解析可以达到更好的应用效果,更低的误报率。
结论2: 日志挖掘对个别的验证事件比较敏感,在解析过程中4%的误差可能导致应用场景性能的急剧下降。