请咨询作者同意后转载。
Where Does It Go? Refining Indirect-Call Targets with Multi-Layer Type Analysis
| 期刊/会议: | CCS(A类)Best Paper! |
|---|---|
| 发表时间: | 2019年11月 |
| 发表机构: | University of Minnesota |
一.研究背景介绍
1.1 函数间接调用(Indirect call)
什么是Indirect Call?
现在的系统软件通常都会使用Indirect Call (后续记为iCall)来实现程序的动态行为。例如Linux kernel就提供统一的文件操作API,比如说open(),在不同的文件系统中,内核会使用函数指针->open()来决定在运行时具体调用哪一个函数实现。 通常iCall的目标函数包括:回调函数、虚函数、jump table实体等。
函数指针可以存于原生类型变量和复合类型变量中,在一个函数指针被分配到一个变量对象前,它的函数类型可以被保留或者被转换。作者对Linux kernel中函数指针的存在情况进行了调研,在212K个存储函数指针的指令中,88%会将函数地址存储到复合类型,12%会存储到原生类型。
这里原生类型指的是c语言里的int、void、char等默认类型,复合类型指的是struct等自定义类型。
更多介绍见:深入理解C语言函数指针
因iCall而导致的问题:
而因为iCall其动态决定的本质特性,通过静态分析并不能精确的解析出iCall的目标函数。这就导致在构建全局控制流图(global CFG)时会遇到怎样将iCall和其目标函数连接起来的挑战,而构建一个精确的全局控制流图则是许多静态程序分析技术的基础需求。
通常,在构建CFG时,对无法解析出的iCall有两种方案:
- 直接跳过
- 根据函数指针的类型,将所有可能的函数都作为目标函数
第一种方案限制了静态分析的覆盖率,导致在iCall目标函数中的bug没法找到;第二种方案则是限制了分析的扩展性(路径爆炸)和准确性(误报)。
1.2 iCall target识别研究现状
目前, 研究人员尝试通过两种方式来静态的确定iCall的目标函数:指针分析和类型分析。
对于指针分析, 理论上来说,通过全程序的分析可以找到所有iCall的目标函数。但是这样的分析必须从程序一开始就运行,且计算复杂度非常高,实际中并不可取。
对于类型分析, 有一些CFI的研究工作会根据函数指针的类型和函数申明的类型进行匹配来识别。但是这样粗糙的识别会产生大量的误报。
二. 案例解读
图1展示了一个函数指针和iCall的代码片段,这个代码片段中定义了一个函数指针的类型fptr_t和三个结构体A,B,C。其中,A中包含一个fptr_t类型的函数指针handler,B和C中都包含了一个结构体A的实体。 这个代码片段还包含了两个字符串拷贝函数copt_with_check和copy_no_check,其函数类型和参数都一样。在代码片段的第15行和18行,定义了两个全局变量:类型为B的b和类型为C的c,并对其内部的函数指针进行初始化。在第23和24行,两个函数指针被两个iCall所使用。

2.1 Motivation
通过上面的例子,我们可以看到一个函数地址经常存储到具有多层类型阶级的对象中,当一个函数指针在一个iCall中被使用时,函数指针的值也会从相同的类型阶级中一层一层的加载出来。例如,b.a.fptr=&f,函数f的函数地址被存储到类型为B对象b中的类型为A的对应a的fptr域中。在调用时,函数指针值也会这样一层一层的加载出来。作者就基于这样的发现,通过对函数指针和地址取值函数之间的多层类型进行匹配,来对iCall进行解析,这种方法称之为multi-layer type analysis (MLTA)。 对应的,只使用一层类型的方法称之为first-layer type analysis (FLTA)
2.2 FLTA的局限性
在图1中的例子中,函数copy_with_check和copy_no_check都具有相同的函数类型和参数类型,且在第23和24行的两处iCall中,第一层的类型均为fptr_t,这就会导致这两个iCall都有两个相同的目标函数copy_with_check和copy_no_check。 但是实际上,第23行的iCall对应的是copy_with_check,第24行的iCall对应的是copy_no_check,这就引入了iCall解析的false positives。
iCall解析的错误会导致bug detection时的误报。 第23行的iCall的目标函数进行了参数长度的验证,因此是安全的,但是在检测时,因为有两个目标函数,就都会进行分析,从而因为错误的目标函数copy_no_check而产生额外的检测误报。
iCall解析的误报,会削弱CFI的保护强度。 CFI的目的是防止控制流劫持,CFI会确保每个控制流上的间接转移(例如iCall)仅会前往预先定义的有效的目标,而精确的iCall解析会增强CFI带来的保护。但是在第23行多余的错误目标函数解析,会削弱CFI的保护力度。
2.3 MLTA的思路
MLTA通过对iCall进行多层的类型分析,来逐步缩小目标函数范围。例如,在图1中,第23行iCall中的函数指针b.a.handler的多层类型可以表示为B.A.fptr_t,MLTAX需要23行iCall的目标函数满足:其函数地址必须被取值过、其函数地址赋值给一些具有三层类型B.A.fptr_t的函数指针。
通过这样的多层分析,我们就可以确定第23行的iCall目标函数仅为copy_with_check,因为copy_no_check是赋值给了类型为C.A.fptr_t的函数指针。
而MLTA方法带来的好处有:
- 显著的降低了FLTA的误报。
- 没有引入false negatives。
作者实现了MLTA方法的原型,并命名为TypeDive。
三. TypeDive方法总览
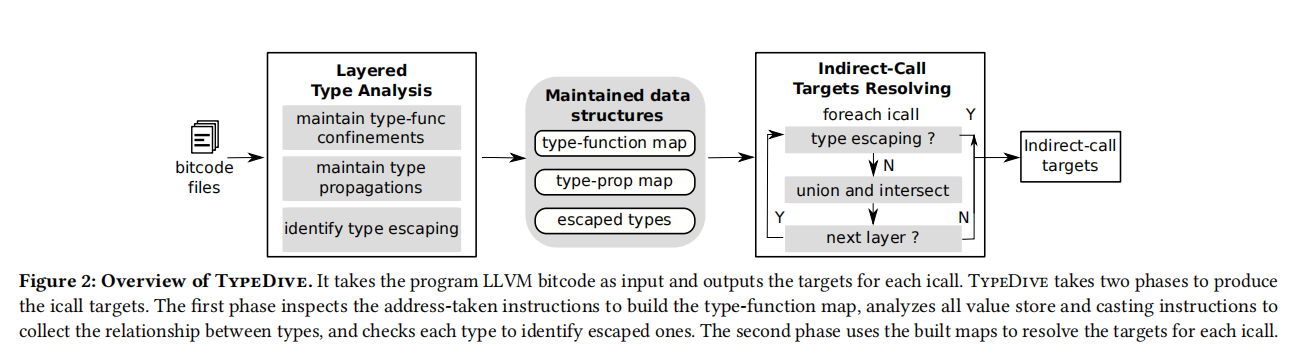 TypeDive主要由两个阶段组成:type analysis phase 和 target resolving phase。
TypeDive主要由两个阶段组成:type analysis phase 和 target resolving phase。
3.1 Type Analysis Phase
第一阶段主要是彻底的扫描所有的bitcode文件,来收集和类型相关的信息。
首先,会收集所有的address-taken函数和识别所有的address-taken operations,然后分析这些address-taken operations来识别内存对象的multi-layer type。比如说,图1中的第15行,copy_with_check的地址被赋值给了b.a.handler,TypeDive就会识别出这个对象的multi-layer type为B.A.fptr_t。
然后,将multi-layer type划分为多个two-layer type,来进行有效的目标传播。比如说将B.A.fptr_t划分为fptr_t(第一层)、A.fptr_t(第二层)和B.A(第三层)。这时,将这些类型和函数信息添加到type-function map中,其中,key为two-layer type的hash值,value为相关的函数集合。
之后,识别出那些有类型的对象是如何存储到不同类型的对象中去,例如*p=a,并将这两个操作类型添加到type-propagation map中,其中key为对象a的类型,value为对象p的类型。这个map维护了所有的类型转换的信息。
最后,捕捉潜在的type escaping案例,并将其添加到escape-type set中去。
type escaping的定义为:我们不能为这个type来限制target的范围,那么这个类型就发生了逃逸。比如说如果我们将一个原生类型转化成一个复合类型,那么我们就不能确定这个原生类型的目标函数,因为原生类型可以转化成任意符合类型,因此无法约束target的范围。同样的,这个被转化的符合类型,也因为由原生类型转化而来,变得无法确定target了。 所以这种情况下,这个原生类型和复合类型都发生了类型逃逸。
3.2 Target Resolving Phase
第二阶段的目标是,为每个iCall解析目标函数。
给定一个iCall,先识别出函数指针的multi-layer type,然后将其划分为一系列的two-layer type。 然后使用first-layer type匹配来初始化目标函数的集合,随后一层一层的根据当前的类型来解析当前层的目标函数。需要注意的是,在每一层类型解析后,要将当前层的解析函数结果和上一层的解析函数结果取交集。
在每一层解析的过程中,TypeDive要根据type-escaping set检查当前layer的类型是否逃逸,如果逃逸的话,就保守性的停止迭代,并将当前解析的结果作为最后的结果。如果没有逃逸的话,就查询type-propagation map找到所有曾经转换到当前类型的类型。上面这些的类型对应的目标函数,会添加到当前layer的目标函数结果中,做一个并集。
虽然作者没有给出一个这个阶段具体运行的例子,但根据TypeDive的方法思路,我们可以用图1中的例子来解释这一阶段的运行:
对于图1中第23行的iCall,解析流程如下:
- 根据first-layer type (
fptr_t)匹配的结果为set1 = {copy_with_check,copy_no_check}。 - 根据second-layer type (
A.fptr_t) 匹配的结果为set2 = {copy_with_check,copy_no_check}。set2和set1的交集仍然是set2。 - 根据third-layer type (
B.A) 匹配的结果为set3 = {copt_with_check},和set2取交集为$set_2 \cap set_3 = ${copy_with_check}。
因此对于第23行的iCall,可以解析得到唯一一个正确的目标函数。
四. TypeDive 设计与实现
方法思路与具体流程在之前部分已经介绍,下面只描述几个重要的点。如果对更细节的部分感兴趣请refer paper。
识别逃逸的类型 (escaping types)
如3.1中所说,如果一个类型发生逃逸的话,那么我们是不能为这个类型来缩小目标函数范围的。为了更加明确识别escaping type的策略,作者定义了几个TypeDive理论上unsupported types:
- 原生类型。比如,
char *。 - 指针经过算数计算的对象的类型。
第一种类型不支持的原因是,作者发现,这些类型通常具有非常大量的潜在目标函数,会导致分析的效率问题。
第二种类型不支持的原因是,指针经过了算法运算,那么其指向的对象类型有可能发生变化,不可确定。
五. 实验效果
仅展示部分我感兴趣的实验结果。
5.1 运行效率
如下图所示,在Linux、FreeBSD和Firefox上进行了测试,花费的时间如下。
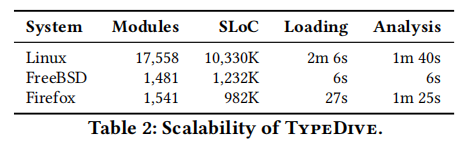
需要注意的是,这里并没有把生成bitcode的时间算进来,根据经验,在Linux上生成bitcode files在工作站上都需要大半天的时间,但很多程序分析技术都是在bitcode上搞的,所以生成bitcode的时间可以不考虑。
还是可以看出,仅用了不到5分钟,就能为linux kernel解析出iCall的target,效率很不错的,有实用性。
5.2 iCall解析结果
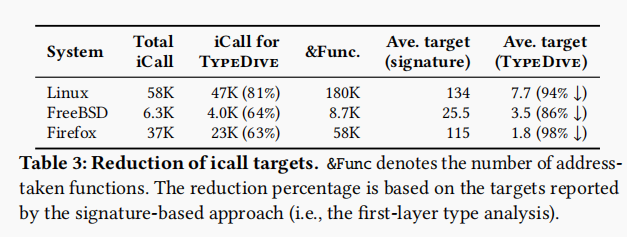
iCall target的平均数量: 这类作者除去了unsupported types的iCall,在Linux上还剩下47K的iCall要进行解析。 使用FLTA方法,平均每个iCall会解析出134个targets,使用MLTA方法平均只会解析出7.7个targets,减少了94%的误报。 但这里作者很鸡贼,因为只有两层以上的iCall才会收到MLTA的好处,所有表中的数据(7.7)仅是对那些具有两层以上的iCall的解析结果。 而对于所有支持的iCall解析来说,对于Linux、FreeBSD和Firefox分别为:31.6, 11.5和44.6。
不过还是能起到不错的效果。
和指针分析方法对比: 明显iCall解析这种事是指针分析很擅长做的,但因为实际开销和复杂度的问题才导致指针分析对于iCall解析实际中并不是这么好。 所以作者也和指针分析方法在解析iCall上做了个对比。
作者在FreeBSD上使用指针分析,得到每个iCall的平均targets数量为6.64。这里注意到指针分析的结果(6.64)是要比MLTA方法(11.5)要好的,这结果很打脸啊,MLTA存在的意义在哪?,作者为了说明MLTA更好,又说了一大堆。
个人认为,MLTA的好处有如下几点:1. 效率高,可以为对效率有要求但对准确率没那么严格的场景服务,比如CFI。2. MLTA不会引入漏报,所以和指针分析的结果取一个交集可以得到更准确的targets。但我估计MLTA的结果可能是指针分析结果的超集。