课程信息:感谢@李文哲老师,贪心科技–“ 共同战疫” NLP系列专题 直播课,本文所有版权归贪心科技https://www.greedyai.com/所有。
Lecture 5 - 从BERT到XLNet
因为标签样本的稀缺性,所以我们也同样需要将无标签样本利用起来。
下图为NLP中的一些无监督学习方法:

Denoising Autoencoder
这里需要先介绍下Autoencder 与Denising Autencder的区别。
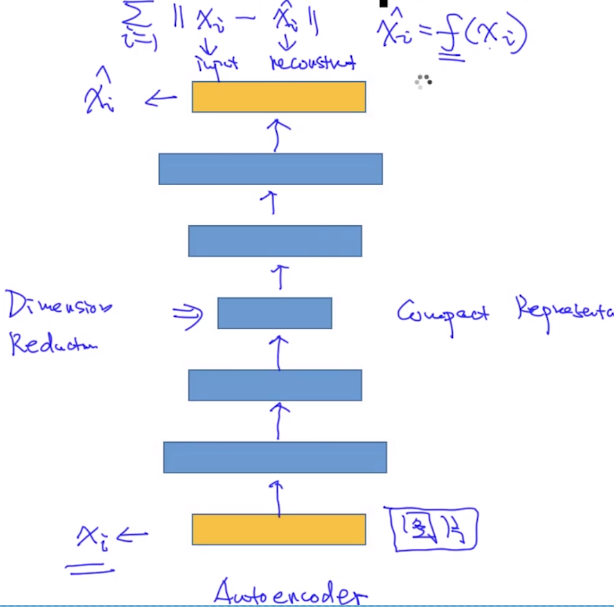
AutoEncoder: 如下图,我们希望神经网络能够学习到输入(图片、向量)的紧凑表示(compat represention),并且能够通过紧凑表示恢复出尽可能与原来相似的图片或者向量。
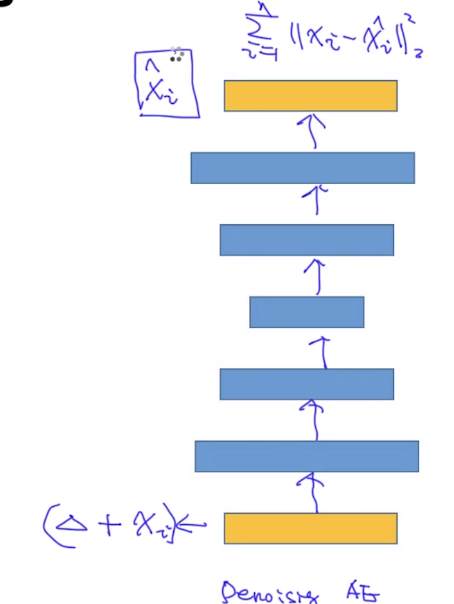
Denoising AutoEncoder: 结构和Autoencoder一样,但是我们在输入加了点噪声$x_i + \delta$,并且仍然希望其学习到紧凑表示,并且学习到的紧凑表示仍然能够尽可能的还原出输出$x_i$。
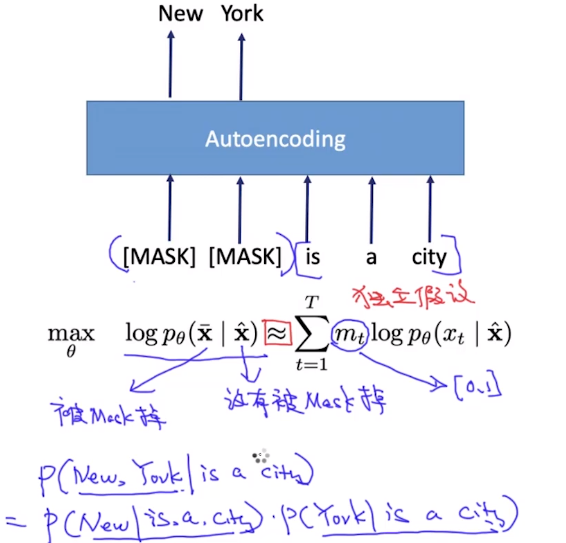
这样能够使得学习出的紧凑表示更加的鲁邦,BERT的MASK就是DAE的一种形式。
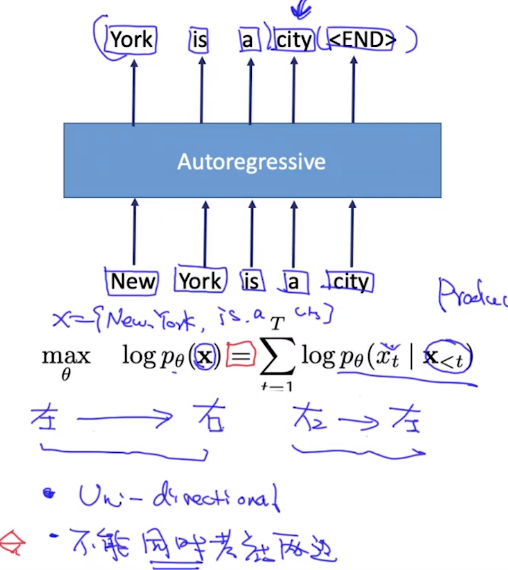
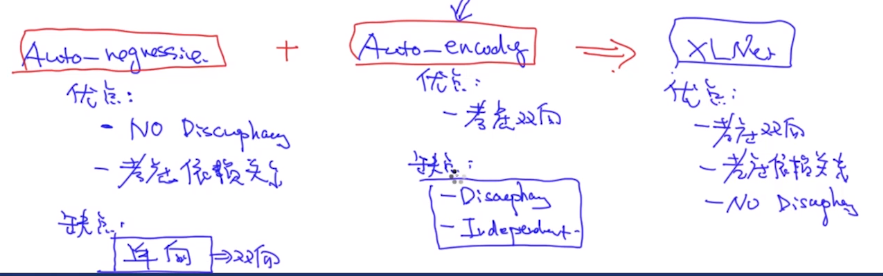
Autregressive vs Autoencoding
对于Autoregressive,其目标函数符合语言模型,但是即使对于ELMo来说,也只能同时考虑一边的依赖关系。
对于Autoencoding来说,其是基于条件独立假设 ,将联合概率分解为两个独立的概率,并且存在训练环境和测试环境的不一致性。
而我们就是为了解决上面两种目标函数的缺陷,其存在两种可能:
- 解决Auto-Encodeing的缺点,这个有点难
- 解决Auto-regressive的缺点,即只用将单向改为双向。
这就引出了XLNet:
如何使autoregressive变得双向?
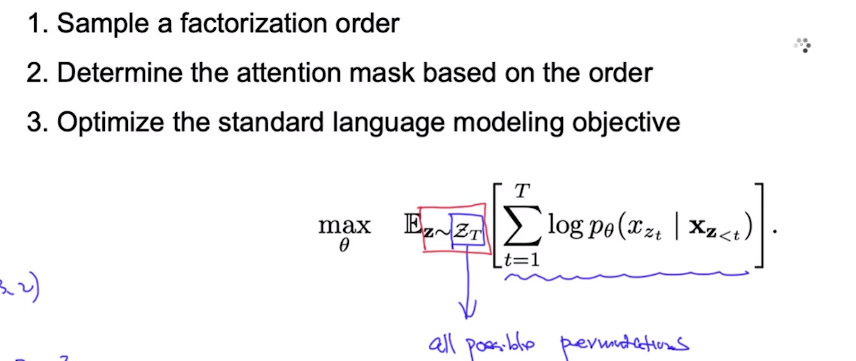
答案:考虑所有可能的句子分解(置换)来训练。
例如,我们将下面5个单词的句子进行全部置换,那么在不同的置换中,为了预测“York”,就考虑了所有的上下文了。
在具体的实现中,因为置换的复杂度为阶乘,所以我们只需要从中随机选取一部分来训练,然后求所有可能置换的期望。
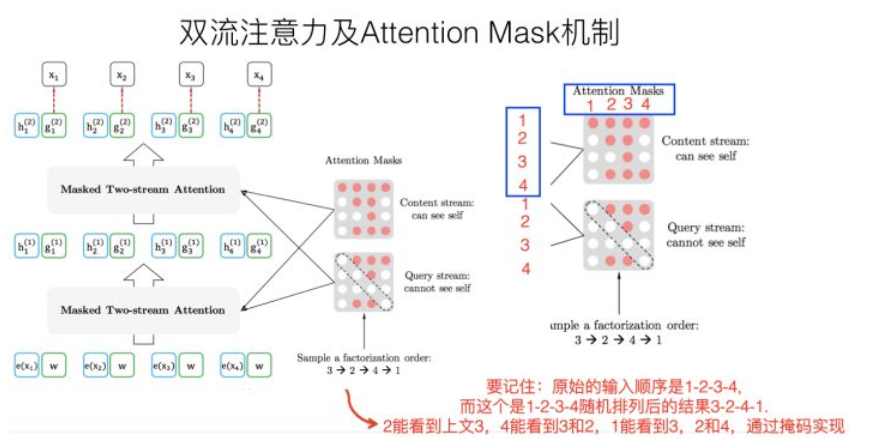
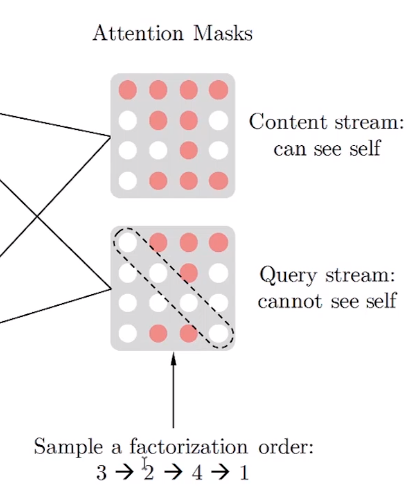
在网络每一层的传递中,比我们希望预测x3,对于不同的Order根据Attention Mask矩阵来分配当前单词需要注意的单词。

Attention Masks如下,再具体实现中,在Transformer内部通过Attention Mask,将order中预测词下文的部分MASK掉,我们可以保证输入不变,而实现刚才的逻辑,只关注Order上文单词.
双流自注意力机制
这里还需要提一下,XLNet是基于Auto-regressive结构的。

现在我们将Auto-regressive的语言模型目标函数进行参数化:
其中$h_\theta (x_{1:t-1})$为$x_1….x_{t-1}$所代表的意思,但不包含任何位置信息。

但是上面的目标函数存在歧义性:”New”在第一个句子中和”New”在第二个句子所在位置出现的概率应当是不一样的,但是在上面的目标函数中算出的结构却是一样的。只考虑空格上下文,但却没考虑位置信息。
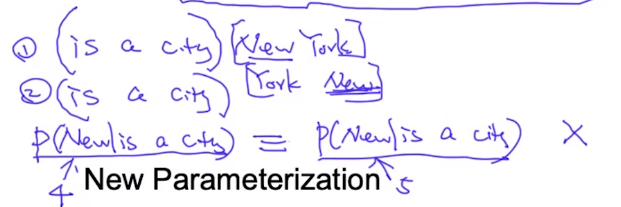
所以在新的参数化的目标函数中,我们不仅需要知道上下文所表达的意思信息,还需要知道当前预测词所处在的位置信息。
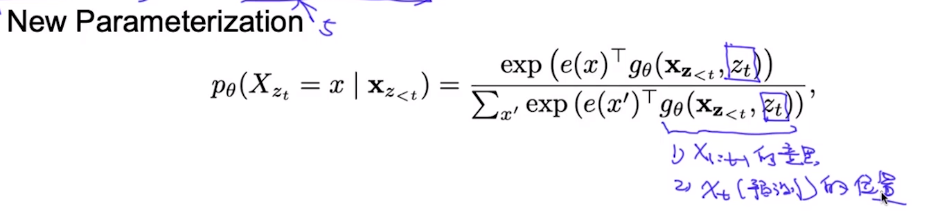
那么我们现有的网络结构是否能够支持我们既传达内容信息,又传达位置信息呢? 现在让我们看看下面这个例子,对于Order 3 2 4 1来说,左边的图中,我们希望 (1)获得3的内容信息 (2)获得2的位置信息 (3)不能获得2的内容信息
右图中,我们希望
(1)获得2,3的内容信息
(2)获得4的位置信息
(3)不能获得4的内容信息
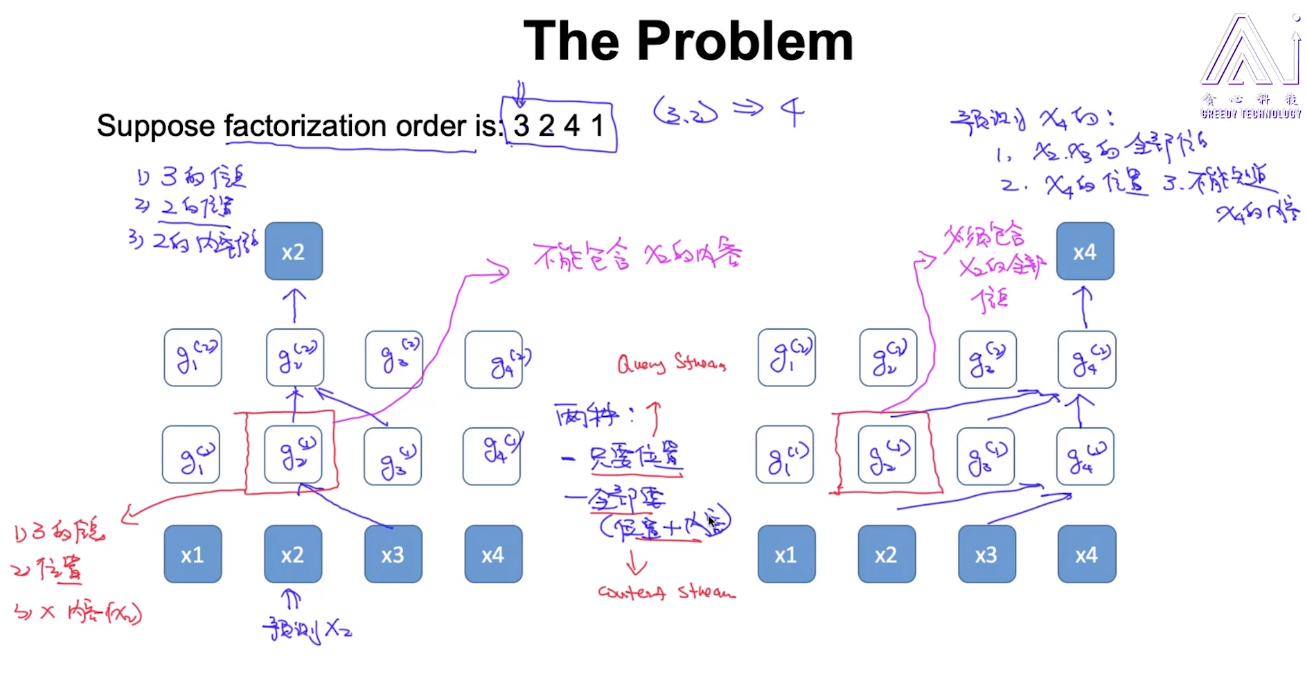
可见,对于上面两种情况不能同时满足,起了冲突。
这里的解决方案为:Decouple。 对于h来说传递所有信息(包括位置信息),对于g来说只传送位置信息。
其中w为一个共同参数,可以在学习过程中不断学习得到。
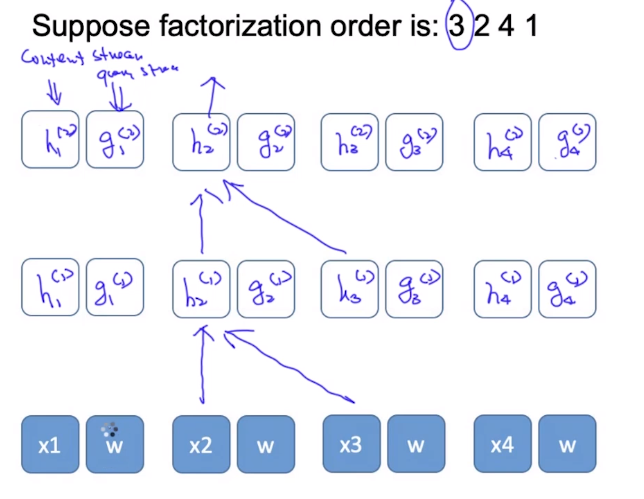
所谓的双流,就代表的是Content Flow 和Query Flow,上图中的h就代表的是Content Flow,通过Content Mask来过滤掉Order下文的单词,作用上替换Transformer的[MASK]功能。而Query Flow在上图中用g来表示,通过Query Mask只传递位置信息。